| 00:05 | <roc> | smaug____: wfm too |
| 00:06 | <smaug____> | k |
| 00:08 | <roc> | actually I think it would be slightly neater to have "sandbox" be a boolean attribute and have allow="forms same-origin" etc |
| 00:08 | <roc> | but maybe it's too late for that |
| 00:09 | <annevk> | Opera does not have sandbox |
| 00:09 | <annevk> | does IE? |
| 00:10 | <roc> | I believe IE10 does |
| 00:11 | <smaug____> | yes, IE10 has http://msdn.microsoft.com/en-us/library/hh673561%28v=VS.85%29.aspx |
| 00:11 | <annevk> | guess there goes the idea for a better syntax |
| 00:12 | <roc> | well, IE10's not out yet |
| 00:12 | <zewt> | roc: is there really much benefit to that over just having regular attributes? since that's how everything else does it... |
| 00:12 | <annevk> | yeah, and we could transition from one to the other somehow |
| 00:13 | <roc> | a browser could easily support both syntaxes |
| 00:13 | <smaug____> | yeah |
| 00:13 | <zewt> | but why have two syntaxes? |
| 00:13 | <annevk> | zewt: currently it's sandbox=allow-scripts |
| 00:13 | <annevk> | zewt: or sandbox="allow-scripts allow-forms" |
| 00:13 | <annevk> | if we are going to have an allow attribute |
| 00:13 | <annevk> | letting that take "scripts" and "forms" seems way better |
| 00:14 | <annevk> | (and other values) |
| 00:14 | <roc> | zewt: it seems cleaner and easier to use to have all the permission-granting following the same pattern instead of some permissions only working in the sandbox attribute and others working in the "allow" attribute |
| 00:14 | <Hixie> | i prefer keeping the things that sandbox="" turns off separate from the things that allow="" turns on |
| 00:14 | <Hixie> | but i think that ship has sailed, anyway |
| 00:14 | <roc> | sandbox doesn't turn things off, it turns things on |
| 00:14 | <roc> | the things in its attribute value |
| 00:15 | <roc> | so now you have to know, for each thing you want to turn on, whether it belongs with sandbox or not |
| 00:15 | <Hixie> | sandbox="" turns things off, its value can then turn things back on |
| 00:15 | <annevk> | which it first disables |
| 00:15 | <Hixie> | as opposed to allow="", which turns things on that are by default off |
| 00:17 | <roc> | as an author, if I've got a sandboxed iframe and I want to add fullscreen permission and forms permission, say, I have to know that the former doesn't belong in "sandbox" and the latter does. It's no biggie, but it's unnecessary complexity |
| 00:19 | <zewt> | requesting fullscreen permission in markup would be bizarre anyway |
| 00:19 | <zewt> | and way outside the general permissions model that's been used so far (ask when you need it, don't bundle up permission requests and ask at the start) |
| 00:20 | <roc> | this is different |
| 00:20 | <smaug____> | (this has nothing to do with requesting permission) |
| 00:20 | <roc> | this is about the outer page allowing the content in an <iframe> to go fullscreen |
| 00:21 | <roc> | it's about granting permission, not requesting it |
| 00:24 | <zewt> | Hixie: fwiw, if there's both sandbox="allow-things" and allow="other-things", i'd change one "allow" or the other (to "permit" or something) |
| 00:26 | <Hixie> | i don't think it'd be wise to change sandbox="" at this stage |
| 00:26 | <Hixie> | churn in specs just pisses people off |
| 00:26 | <Hixie> | especially once they've implement it |
| 00:27 | <Hixie> | and pissing off implementors is not a good way to get interoperability in the future |
| 00:27 | <zewt> | two ways to go though--is @allow newer? |
| 00:27 | <Hixie> | allow="" doesn't exist yet |
| 00:27 | <zewt> | then that'd be the one to change |
| 00:29 | <annevk> | I do think though that if a feature is not deployed everywhere yet changing it should be acceptable even though not ideal |
| 00:30 | <annevk> | If you look at the kind of relatively minor details that trip people up... If we can simplify, we should |
| 00:44 | <zewt> | uhh, what? javascript:alert("foo") in FF8 is ... not finding alert() |
| 00:45 | <gavin> | javascript: URLs entered into the lcoation bar in Firefox 6 and later don't inherit the context of the current page |
| 00:45 | <zewt> | braaaaaaaindamage |
| 00:45 | <gavin> | they are also unfortunately not run in a DOM context at all, so no window.alert |
| 00:45 | <gavin> | javascript:1+1 works, though! |
| 00:45 | <zewt> | "we can't remove this! let's just utterly break it, because that's okay" |
| 00:45 | <zewt> | ugh. |
| 00:46 | <gavin> | we broke it because users were getting pwned on facebook |
| 00:46 | <zewt> | no, really. ugh. |
| 00:46 | <smaug____> | I thought other browsers will do the same |
| 00:46 | <gavin> | they did (some in less effective ways) |
| 00:46 | <zewt> | (trying to write some test instrumentation dumping javascript: stuff into the address bar to avoid having to modify the page directly, which should work just fine) |
| 00:46 | <smaug____> | and yes, it is really annoying, though I use javascript: mainly as a calculator |
| 00:47 | <roc> | shift-ctrl-K, go crazy in the Web Console |
| 00:47 | <roc> | it's actually less to type than "javascript:" |
| 00:47 | <zewt> | that'll be different in every browser (vs. automating alt-d + type stuff) |
| 00:48 | <zewt> | no, i was trying to automate keystrokes to run diagnostic code on different browsers; javascript: in the address bar is one approach that shouldn't have been massively different in each browser |
| 00:50 | <roc> | various Firefox extensions let you remap keys |
| 00:51 | <zewt> | this is automation from an external script |
| 00:51 | <kbrosnan> | javascript: is an attack vector |
| 00:53 | <zewt> | not a reason to not have an about:config to revert this nonsense for the people who are 1: not stupid enough to copy and paste whatever people tell them to and 2: actually do use browser features that have been around forever |
| 00:54 | <zewt> | guess i'll just need more browser special cases; oh well |
| 02:02 | <MikeSmith> | hmm |
| 02:02 | <MikeSmith> | http://www.securityweek.com/ca-industry-group-creates-new-standard-issuance-ssltls-certificates |
| 02:02 | <MikeSmith> | http://cabforum.org/Baseline_Requirements_V1.pdf |
| 02:02 | <MikeSmith> | Are browser vendors actually still participating the CA/Browser Forum? |
| 02:03 | zewt | clicks link, gets a "subscribe to us" nag and hits control-f4 |
| 06:15 | MikeSmith | reads |
| 06:15 | MikeSmith | reads http://www.w3.org/2011/webtv/wiki/MPTF/Netflix_Content_Protection |
| 06:16 | <zewt> | is anyone actually taking that seriously? heh |
| 06:18 | <zewt> | drm being fundamentally and irreconcilably incompatible with open source browsers, apis specifically to support pieces of it seem completely useless (unless browsers become less open, and anything encouraging that is bad) |
| 06:20 | <Hixie> | not to mention it being user-hostile |
| 06:20 | <Hixie> | i don't understand how any engineer who works on drm tech can live with themselves |
| 06:21 | <zewt> | i've worked on drm :( (but for turnkey arcade systems, not consumer stuff) |
| 06:23 | <zewt> | (and given that the underlying game engine was, for the most part, released open source, I can live with that) |
| 06:24 | <Hixie> | the vast majority of arcade machines i see these days are privately owned |
| 06:24 | <Hixie> | so it's still "consumer stuff" |
| 06:25 | <zewt> | $5000+ machines aren't consumer products, no matter who ends up buying them in the end |
| 06:26 | <Hixie> | cars aren't consumer products? :-) |
| 06:26 | <Hixie> | houses aren't consumer products? :-) |
| 06:26 | <zewt> | different scale of product :) |
| 06:26 | <Hixie> | i don't see how |
| 06:26 | <zewt> | consumer games are $50, not $5000 |
| 06:27 | <Hixie> | my point is that if it's privately owned, the drm would stop someone from making private modifications to their property |
| 06:27 | <zewt> | also vastly different scale (we'd have been happy to sell a thousand units) |
| 06:28 | <zewt> | i know all the arguments; at least in that case (the one I happen to have direct experience with), the practicalities had to come before principle |
| 06:28 | <Hixie> | (and if it's not a consumer product, why bother with drm? a commercial competitor who is so beyond the law that the legal system is not a sufficient recourse is certainly not gonna have any trouble reverse-engineering some obfuscation) |
| 06:29 | <zewt> | because the variables don't work out that way |
| 06:29 | <Hixie> | (in fact such a competitior is far more likely to just steal the code/assets/designs/whatever straight from the source repository than bother with buying an actual product) |
| 06:29 | <Hixie> | (just look at how movies get redistributed before they're even commercially available) |
| 06:29 | <zewt> | there are plenty of people who would pirate our game if it was easy to do (just a new HDD), but nobody with the expertese to break it was actually trying |
| 06:30 | <Hixie> | and how many of those people actually bought copies instead? |
| 06:30 | <zewt> | versions of our game where the encryption was broken sold significantly less than the ones where it wasn't (don't have exact numbers, probably couldn't say them if I did) |
| 06:31 | <zewt> | also, enforcing copyright internationally takes a lot more resources than domestically |
| 06:32 | <Hixie> | should've just paid for a security guard for each unit to stand there with a cane and beat anyone who tried to open the box, instead |
| 06:32 | <zewt> | then we'd need our own legal defense team. heh |
| 06:32 | <Hixie> | anyway |
| 06:32 | <Hixie> | the ends don't justify the means |
| 06:32 | <Hixie> | consumer or not |
| 06:33 | <zewt> | when the lack of DRM means there will be no future product, they can |
| 06:33 | <Hixie> | better to have no products than to have drm, imho |
| 06:34 | <Hixie> | (luckily, that isn't even close to the actual result of not having drm) |
| 06:34 | <zewt> | it definitely was in our case (i'm not saying it is in *all* cases) |
| 06:35 | <Hixie> | i'm skeptical, but i don't have all the data so can't comment one way or the other on your specific case |
| 06:35 | <Hixie> | generally when i've seen people make those claims though they tend to forget to account for all the factors, e.g. the opportunity cost of working on drm |
| 06:36 | <zewt> | what? |
| 06:36 | <zewt> | (i know the cost to us in implementing the drm, since i did it all myself--took 3-4 weeks) |
| 06:37 | <Hixie> | 3-4 weeks total, or 3-4 weeks on the ones that got broken, or 3-4 weeks on one game that didn't get broken?L |
| 06:38 | <zewt> | as far as I know it was never broken so long as I worked there, at least (at least based on the fact that bootlegs didn't show up in the wild) |
| 06:38 | <zewt> | (forget how long; well over a year) |
| 06:38 | <Hixie> | i thought you just said "versions of our game where the encryption was broken sold significantly less than the ones where it wasn't" |
| 06:39 | <zewt> | that was a much older system (written maybe 6-7 years earlier) |
| 06:39 | <Hixie> | so 3-4 weeks per game then |
| 06:39 | <zewt> | it was much weaker and used on too many products without changing |
| 06:39 | <Hixie> | how much more would you have made if you'd spent those 3-4 weeks e.g. working on a system where they could buy the disks to put new games in for very little instead of requiring that they buy an entirely new unit? (i'm guessing as to the mechanics here since i don't know what you did exactly) |
| 06:40 | <zewt> | 3-4 weeks initially; that system was used on two products while I was there |
| 06:40 | <zewt> | we actually did have a system for in-place upgrades; the market wasn't really set up to use it, so we didn't make much use of it |
| 06:40 | <zewt> | (insert USB drive with upgrade, push button, wait a minute) |
| 06:40 | <Hixie> | but the market was set up to do it without you if they broke the drm? |
| 06:41 | <zewt> | the market is always set up to copy games for free if they can |
| 06:41 | <zewt> | (at least in some countries) |
| 06:42 | <Hixie> | not at all, e.g. valve has found that by making buying games actually easier than copying them, they sell more games than they would if they had drm |
| 06:42 | <zewt> | that's for consumers buying games online; it doesn't translate to $500+ upgrade packs for arcade games |
| 06:43 | <zewt> | (eg. many arcades can't get internet access to machines) |
| 06:43 | <Hixie> | so maybe the problem isn't that your market isn't set up for it but that you were charging rates the market wasn't ready to support without using artifical tactics like drm |
| 06:44 | <zewt> | the market isn't prepared to pay anything whatsoever, if it can get stuff for $0 (or $30 or whatever the cost of a tiny HDD is) |
| 06:44 | <Hixie> | again, valve has shown that to not be true |
| 06:44 | <Hixie> | iTunes has also shown that to not be true (for music) |
| 06:44 | <zewt> | again, steam has no comparative value to arcade machines |
| 06:45 | <zewt> | buying a song on iTunes is "push button, spend $1, get a song"; arcade owners don't spend hundreds of dollars on an upgrade on a one-click whim purchase |
| 06:45 | <Hixie> | i see no reason to believe that any particular market would be any mare special than another here |
| 06:45 | <Hixie> | again, maybe the problem is that you were charging too much to make it sustainable |
| 06:45 | <zewt> | it's completely different, because upgrading an arcade machine is a financial investment, buying a game on steam is not |
| 06:46 | <Hixie> | all purchases boil down to investments |
| 06:46 | <zewt> | not in comparable notions of the word |
| 06:46 | <Hixie> | when you buy a game on steam, you're return is going to be in entertainment per hour instead of dollars per hour |
| 06:46 | <zewt> | i buy a $40 game if I think I'll have $40 of fun with it; an arcade owner buys a $500 upgrade if he thinks he'll make $500 more money from coin drops as a result |
| 06:46 | <Hixie> | but at the end of the day, what are dollars if not a way to get entertainment? |
| 06:47 | <Hixie> | sounds the same to me |
| 06:47 | <zewt> | sounds unrelated to me |
| 06:47 | <Hixie> | whatever lets you sleep at night :-) |
| 06:48 | <hsivonen> | RDFa continues to live in a time warp where HTML and XHTML are developed separately: http://www.w3.org/News/2011.html#entry-9301 |
| 06:48 | <zewt> | our engine was almost all released as open-source, so I have no trouble sleeping at night :) |
| 06:49 | <zewt> | http://sourceforge.net/projects/stepmania/ |
| 07:19 | <roc> | there are different kinds of DRM |
| 10:13 | <annevk> | thanks Hixie for picking up on the callback stuff |
| 10:13 | annevk | had given up |
| 11:13 | <annevk> | can someone explain to me what I did wrong here: |
| 11:13 | <annevk> | http://validator.nu/?doc=http%3A%2F%2Fdvcs.w3.org%2Fhg%2Fencoding%2Fraw-file%2Ftip%2FOverview.html |
| 11:14 | <annevk> | ooh, this goes for a lot on dvcs |
| 11:14 | <annevk> | maybe it says charset="utf-8" in the HTTP header and validator.nu has the same bug Gecko once had? |
| 11:20 | <hsivonen> | annevk: yeah. is it a v.nu bug or a W3C server config bug? |
| 11:26 | <annevk> | per HTTP v.nu |
| 11:27 | <annevk> | but HTTP is not defined in a pragmatic way, so "unclear" :( |
| 11:33 | <annevk> | hsivonen: ideas on how to make http://dvcs.w3.org/hg/encoding/raw-file/tip/single-octet-research.html more readable? |
| 11:33 | <annevk> | hsivonen: pull not supported before the table I guess and maybe give the "other labels" bit a heading of some sorts? |
| 11:33 | <annevk> | it needs to stay fairly compact because there's so much information |
| 11:34 | <hsivonen> | annevk: first of all, you could separate the encoding tables from the browser support data instead of interleaving them |
| 11:35 | <hsivonen> | annevk: then maybe have a table of with browsers as columns and encodings as rows and markers in the cells and cell bg colors that communicate the same info as the markers |
| 11:36 | <annevk> | ooh that sounds pretty good |
| 12:25 | smaug____ | kicks sicking |
| 12:25 | <sicking> | huh? |
| 12:26 | <Echoes2> | o_O |
| 12:26 | <smaug____> | I strongly disagree your idea that if websocket buffer is full, let's just cut it |
| 12:27 | <smaug____> | it is like "hey, we have little problem, and we don't want to handle it at all, so please re-start everything" |
| 12:28 | <sicking> | smaug____: you should check archives, this discussion has been had at least a dozen times |
| 12:28 | <smaug____> | where? |
| 12:28 | <smaug____> | I do recall this discussed few times |
| 12:28 | <sicking> | webapi list i would think |
| 12:29 | <sicking> | smaug____: the thing is, running out of buffer space should never happen. It's equivalent to OOM |
| 12:29 | <smaug____> | your point about data integrity is valid, but that just means that error handling is now forced to happen in error event listener |
| 12:29 | <sicking> | smaug____: error handling *should* happen in the error handler |
| 12:29 | <sicking> | that's what it's for |
| 12:30 | <sicking> | what else woudl you do there? |
| 12:30 | <smaug____> | er, error or close handler, whatever |
| 12:31 | <smaug____> | well, we could for example change send() so that you can't send more stuff before the previous trial has succeeded |
| 12:31 | <smaug____> | closing the connection is really overkill |
| 12:31 | <sicking> | smaug____: is it overkill to throw an uncatchable exception on OOM |
| 12:32 | <sicking> | smaug____: and that in JS. In C++ if you run out of OOM we quit firefox |
| 12:32 | <sicking> | err.. if you OOM (not run out of OOM) |
| 12:32 | <smaug____> | I don't know what OOM has to do with this |
| 12:32 | <sicking> | smaug____: the buffer is memory, running out of buffer is running out of memory |
| 12:33 | <smaug____> | yes, but you know before putting anything to the buffer that hey, there is no room there atm |
| 12:34 | <sicking> | who knows that, and how? |
| 12:35 | <smaug____> | well, in our impl, when we try to copy the data to the buffer |
| 12:35 | <smaug____> | if allocation doesn't work, there would be OOM |
| 12:35 | <sicking> | yes, the implementaiton knows that |
| 12:35 | <smaug____> | which could be reported in a meaning full way to JS |
| 12:35 | <sicking> | same thing when allocating a C++ or JS object |
| 12:36 | <sicking> | when spidermonkey is asked to allocate a JS object we know we won't be able to honor it |
| 12:36 | <sicking> | but we don't report an error in the normal fashion, we simply abort JS execution ("uncatchable exception") |
| 12:36 | <smaug____> | this is about quite a bit different case |
| 12:37 | <sicking> | we really shouldn't be running out of websocket buffer any more than running out of JS-heap |
| 12:37 | <sicking> | so i don't see how they are different |
| 12:38 | <smaug____> | you don't create JS object of size 100s of MBs |
| 12:38 | <smaug____> | there is a reason why Gecko doesn't use infallible malloc always |
| 12:39 | <hsivonen> | smaug____: as I understand it, infallible malloc is avoided when Web content can directly control the allocation size |
| 12:40 | <smaug____> | hsivonen: which is the case here |
| 12:40 | <sicking> | hsivonen: the problem is in the definition "directly" |
| 12:40 | <sicking> | there's plenty of things that we store in nsTArrays which come from web content |
| 12:41 | <hsivonen> | sicking: yeah. It's rather annoying that OOM crashes from the infallible malloc are treated as bugs. as if those crashes weren't an expected feature. though sometimes it really makes sense to "fix" those by using fallible malloc |
| 12:42 | <sicking> | hsivonen: yeah, i don't agree that those are always bugs |
| 12:42 | <sicking> | malicious content has always been able to crash any browser |
| 12:43 | <smaug____> | in this case it is quite clear that web content can easily control the buffer size. JS data is converted to UTF8, and that UTF8 data is buffered |
| 12:45 | <sicking> | smaug____: so here's an idea |
| 12:45 | <sicking> | smaug____: we could fire an event when running out-of-websocket-buffer |
| 12:45 | <sicking> | the default action of the event would be to close the connection |
| 12:46 | <sicking> | but the page can call .preventDefault and do its own error handling |
| 12:46 | <smaug____> | that sounds better :) |
| 12:46 | <sicking> | however |
| 12:46 | <sicking> | we really should only be running out of websocket buffer when running oom |
| 12:46 | <sicking> | so it'll be hard to fire an event |
| 12:46 | <smaug____> | not true |
| 12:47 | <sicking> | which part? |
| 12:47 | <smaug____> | if someone is sending jssrtring.length == 100000000 |
| 12:47 | <smaug____> | converting that to utf8 certainly would take lots of memory |
| 12:48 | <smaug____> | so if reserving memory for that utf8 OOMs, we can easily fire the event |
| 12:48 | <sicking> | true |
| 12:48 | <sicking> | but |
| 12:48 | <sicking> | if that's the concern, is it really worth adding a feature for people that sends strings that are 100MB in size? |
| 12:49 | <smaug____> | if browser/OS is really OOMing, then there isn't much to do |
| 12:49 | <smaug____> | people do send huge files |
| 12:49 | <smaug____> | they may have modified the file |
| 12:49 | <sicking> | using strings? |
| 12:49 | <smaug____> | and send arraybuffers |
| 12:49 | <sicking> | as a single arraybuffer? |
| 12:49 | <smaug____> | why not? |
| 12:50 | <sicking> | if you have that much data you should be using Blobs |
| 12:50 | <sicking> | otherwise you risk running OOM no matter what |
| 12:50 | <smaug____> | people do use XHR for file transfer |
| 12:50 | <sicking> | sure, they should send Blobs there too |
| 12:52 | <smaug____> | or could |
| 14:46 | <annevk> | can anyone think of a good way to black box test multi-byte encodings? |
| 14:46 | <annevk> | kind of seems like you should test on a per encoding basis |
| 14:47 | <zewt> | wouldn't it just be dumping a bunch of test data into HTML and examining the resulting DOM? |
| 14:47 | <wilhelm> | Which software will you test? Browsers interpreting something from the web? |
| 14:48 | <annevk> | wilhelm: yeah |
| 14:48 | <zewt> | what the test data looks like would be very encoding-specific, for the most part, i think |
| 14:48 | <annevk> | zewt: I can't really think of a magic bullet |
| 14:48 | <annevk> | zewt: right |
| 14:49 | <annevk> | I heard some horror stories from our encoding guy; not sure I want to put that much time into defining these encodings |
| 14:49 | <zewt> | hmm |
| 14:50 | <annevk> | there's a few things I could do that would improve the current situation somewhat |
| 14:50 | <zewt> | one question i'd have first off: is <span>any text</span> guaranteed in all browsers to actually parse as a span, no matter what "any text" is (assuming it doesn't contain "<") |
| 14:50 | <wilhelm> | Yes. Encoding-specific test data, look at DOM? |
| 14:50 | <annevk> | which is define the labels and such to the extent HTML does |
| 14:50 | <annevk> | so HTML no longer needs encoding specific stuff |
| 14:50 | <annevk> | and all languages can do the same for these encodings |
| 14:50 | <zewt> | for example, if you have just one initial byte of SJIS in there, does the decoder reliably break out of it and parse out the </span> |
| 14:51 | <wilhelm> | annevk: You should take a look at t/imported/kaz, by the way. |
| 14:51 | <annevk> | zewt: I think shift_jis is HTML-safe |
| 14:51 | <wilhelm> | annevk: Lots of legacy encoding tests. |
| 14:51 | <zewt> | this matters because it'd be nice to write the tests as <span id=test1>X</span> and each test as a separate span, so you can pull out each span to look precisely at that one test |
| 14:51 | <wilhelm> | Maybe it can be reused. |
| 14:51 | <wilhelm> | (Lots as in several hundred thousand.) |
| 14:51 | <zewt> | but if there are cases where (intentional, here) encoding breakage within "X" might cause the span to not be closed, it'd get messier |
| 14:53 | <annevk> | zewt: HTML has this vague note |
| 14:53 | <annevk> | "An ASCII-compatible character encoding is a single-byte or variable-length encoding in which the bytes 0x09, 0x0A, 0x0C, 0x0D, 0x20 - 0x22, 0x26, 0x27, 0x2C - 0x3F, 0x41 - 0x5A, and 0x61 - 0x7A, ignoring bytes that are the second and later bytes of multibyte sequences, all correspond to single-byte sequences that map to the same Unicode characters as those bytes in ANSI_X3.4-1968 (US-ASCII)." |
| 14:53 | <annevk> | "An ASCII-compatible character encoding is a single-byte or variable-length encoding in which the bytes 0x09, 0x0A, 0x0C, 0x0D, 0x20 - 0x22, 0x26, 0x27, 0x2C - 0x3F, 0x41 - 0x5A, and 0x61 - 0x7A, ignoring bytes that are the second and later bytes of multibyte sequences, all correspond to single-byte sequences that map to the same Unicode characters as those bytes in ANSI_X3.4-1968 (US-ASCII)." |
| 14:53 | <annevk> | oops |
| 14:53 | <Ms2ger> | wilhelm, I sure hope these are becoming public ;) |
| 14:53 | <annevk> | "This includes such encodings as Shift_JIS, HZ-GB-2312, and variants of ISO-2022, even though it is possible in these encodings for bytes like 0x70 to be part of longer sequences that are unrelated to their interpretation as ASCII. It excludes such encodings as UTF-7, UTF-16, GSM03.38, and EBCDIC variants." |
| 14:53 | <annevk> | wilhelm: I think I looked at those |
| 14:53 | <zewt> | annevk: well, the issue here is what browsers *really* do today... |
| 14:54 | <wilhelm> | Ms2ger: Indeed. But as of last week, I am no longer an Opera employee. So apart from prodding, I can't do much about it. |c: |
| 14:55 | <zewt> | though I suppose if that sort of thing breaks the test, then it'd show up fairly quickly (and once you've tracked that sort of thing down, they can be moved to their own test files) |
| 14:57 | <annevk> | I wonder how browsers will cope with > 65000 <span> elements |
| 14:58 | <zewt> | well, better off breaking tests into blocks |
| 14:58 | <Ms2ger> | Well, how do they deal with the HTML spec? |
| 14:58 | <zewt> | sticking them in spans just makes it easier to batch them, so tests aren't split across thousands of tiny files |
| 14:59 | <wilhelm> | annevk: They cope moderately well wit kaz' tests. SPARTAN, however... (c: |
| 14:59 | <zewt> | could use other ways of dealing with it, like sticking each test between ASCII framing ("XXX 1 test YYY") and picking it apart in scripts |
| 15:00 | <zewt> | (uglier, of course) |
| 15:03 | <zewt> | iso-2022 makes me sad |
| 15:05 | <zewt> | at least most crappy legacy encodings aren't *modal* |
| 15:06 | <annevk> | what does that mean in this context? |
| 15:06 | <Ms2ger> | That ISO-2022 pops up an alert, obviously |
| 15:06 | <zewt> | it has escape codes that change the meaning of future sequences |
| 15:07 | <zewt> | (modal in the sense of having multiple modes, eg. vim is a modal editor) |
| 15:08 | <Ms2ger> | Isn't the latter usage just a synonym of "horrible"? :) |
| 15:08 | <zewt> | trooooll :P |
| 15:09 | <Ms2ger> | Yeah :) |
| 15:09 | <zewt> | apparently in iso-2022 you can have *both* 1: multiple ways to encode the same codepoint and 2: multiple codepoints represented by a particular sequence |
| 15:09 | <zewt> | so it's evil in both directions |
| 15:10 | <Ms2ger> | (I troll vim and emacs just as much, though) |
| 15:10 | <zewt> | i use notepad.exe as often as vim these days, so *shrug* :P |
| 15:11 | <zewt> | "sometimes an editor's just an editor" |
| 15:11 | <annevk> | TextWrangler and nano |
| 15:11 | <Ms2ger> | gedit/jedit/nano |
| 15:11 | <annevk> | but that does sound evil |
| 15:11 | <annevk> | ooh gedit |
| 15:11 | <annevk> | when I was still on Ubuntu, I used that |
| 15:12 | <annevk> | Notepad++ in the Windows days |
| 15:12 | <annevk> | they're all more or less the same to me :) |
| 15:12 | <zewt> | i think you can trace a clear path from utf-8's design directly to iso-2022 |
| 15:12 | <zewt> | "here's iso-2022. here are a bunch of ways it sucks. let's not do any of those things" |
| 15:14 | <zewt> | data point: technically iso-2022 can remap the ASCII range; doing so would violate the abovementioned vague note |
| 15:18 | <annevk> | there's also problems with using those encodings |
| 15:18 | <annevk> | as Philip` once explained on the WHATWG list |
| 15:18 | <annevk> | "The string "숍訊昱穿" encoded as ISO-2022-KR is the bytes 0e 3c 73 63 72 69 70 74 3e. A UA that doesn't support ISO-2022-KR (e.g. Chrome, when I last checked) will decode it as Windows-1252 and get the string "<script>", which is bad." |
| 15:19 | <wilhelm> | That's beautiful. |
| 15:19 | <Ms2ger> | Yeah, that's the kind of thing Philip` would tell us about |
| 15:19 | <zewt> | hacked by chinese? |
| 15:19 | <zewt> | ... literally |
| 15:19 | <divya> | hahaha |
| 15:19 | <Ms2ger> | Koreans? |
| 15:20 | <divya> | annevk: sounds like a good intro if you were gonna write about your encodings spec |
| 15:20 | <divya> | on your blog |
| 15:20 | divya | throws hints |
| 15:23 | <annevk> | nah, my blog is reserved for those who wrote books I enjoyed :p |
| 15:24 | <Ms2ger> | Murakami? |
| 15:24 | <annevk> | I kid, mostly, I think you are right |
| 15:24 | <annevk> | Ms2ger: you wouldn't say, but I'm a big fan |
| 15:26 | <Ms2ger> | I would say, actually :) |
| 15:27 | <zewt> | same thing happens with iso-2022-jp |
| 15:29 | <zewt> | wonder how common it is for web content (does japan *really* need three legacy encodings?) |
| 15:30 | <zewt> | i'd expect it to be more common for mail (don't really know, though) |
| 15:31 | <zewt> | (three major legacy encodings, i should say--you'd get more if you start picking apart sjis, cp932, etc) |
| 15:42 | <hsivonen> | why is the Web Intents work proceeding based on Google's proposal at the W3C instead of proceeding based on Mozilla's Web Activities or Microsoft's Contracts? |
| 15:42 | <Ms2ger> | Because Google is pushing at the W3C and we don't, I guess |
| 15:47 | <hsivonen> | Ms2ger: :-( |
| 15:48 | <Ms2ger> | Most Mozillians don't seem to have a habit to get things specified |
| 15:49 | <hsivonen> | <code agents="" but="" can="" have="" historically="" implement="" implemented="" indeed="" others="" title="javascript:</code>" user=""> |
| 15:49 | <hsivonen> | awesome spec markup |
| 15:49 | <Ms2ger> | Hah |
| 15:51 | <erlehmann> | hsivonen, WTF IS THIS SHIT |
| 15:51 | <erlehmann> | i've never seen it before |
| 15:57 | <timeless> | yeah, mozillans seem to be incredibly anti standards in certain areas |
| 15:57 | <timeless> | "not going to bother spending time working with others" |
| 15:58 | <timeless> | hsivonen: where's that one? |
| 15:58 | <smaug____> | hsivonen: I thought Mozilla is working with Google to get Web Intents spec'ed |
| 15:58 | <timeless> | smaug____: not on the list |
| 15:58 | <timeless> | they might have done some hand waving about it |
| 15:58 | <smaug____> | timeless: not sure anyone else is better with standards |
| 15:58 | <timeless> | but they haven't spoken |
| 15:58 | <timeless> | smaug____: oddly microsoft is |
| 15:58 | <Ms2ger> | Well, Google isn't too good at standards |
| 15:59 | <timeless> | (and opera) |
| 15:59 | <hsivonen> | timeless: it's a recent change to the HTML spec |
| 15:59 | <Ms2ger> | But they are good at getting W3C stamps |
| 15:59 | <smaug____> | timeless: not in general |
| 15:59 | <smaug____> | timeless: they have all sorts of non-standard stuff coming |
| 15:59 | <timeless> | smaug____: in the last year or two |
| 15:59 | <hsivonen> | smaug____: Opera seem to be pretty good at standards |
| 15:59 | <smaug____> | Opera is pretty good indeed |
| 16:00 | <timeless> | smaug____: anyway, i'm not saying ms is perfect |
| 16:00 | <timeless> | but at least they're trying |
| 16:00 | <timeless> | the only thing i can point to that mozilla has done recently is requestAnimationFrame or whatever that was |
| 16:01 | <timeless> | i can point to a number of things where mozilla has diverged impls, impl experience, and no interest in helping |
| 16:01 | <Ms2ger> | (Also, browser API) |
| 16:08 | <timeless> | hsivonen: got a link for your <code> ? i'm lazy :) |
| 16:09 | <zewt> | annevk: fwiw, the only solution i can think of to that weirdness (other than everyone removing 2022 encodings) is making them not fall back--if a document is iso-2022-*, browsers that don't want to implement it should refuse to load it at all, not fall back on something else |
| 16:11 | <hsivonen> | timeless: post-process of http://html5.org/tools/web-apps-tracker?from=6874&to=6875 |
| 16:12 | <zewt> | i wish google results on the html spec would put the full-page and multipage results next to each other |
| 16:12 | <zewt> | single-page rather |
| 16:12 | <zewt> | it always ends up putting the single-page result way at the top, and i have to scan through a bunch of other noise to find the multipage result to avoid destroying my browser |
| 16:15 | <timeless> | + example is "<code title="javascript:</code>", but user agents can |
| 16:15 | <Ms2ger> | And then it goes through parser+serializer at least once |
| 16:15 | timeless | can't figure out if that markup is intentionally screwy or accidentally screwy |
| 16:16 | <annevk> | Mozilla is doing Web IDL these days |
| 16:16 | <annevk> | fwiw |
| 16:16 | <annevk> | I think that's pretty awesome |
| 16:17 | <Ms2ger> | And I guess we can claim tantek |
| 16:17 | <zewt> | is it possible for a browser that implements prescan to execute an inline script twice if the encoding has to be changed? |
| 16:17 | <annevk> | I do wish I would not have to extract feedback from bugzilla.mozilla.org every now and then... |
| 16:17 | <annevk> | zewt: yes |
| 16:17 | <zewt> | <script>alert("%")</script><META http-equiv="Content-Type" content="text/html; charset=ibm864"> |
| 16:18 | <annevk> | zewt: but you have to put the encoding declaration prolly after 1024 bytes |
| 16:18 | <annevk> | zewt: so I guess not because of the prescan, but because of the parser |
| 16:19 | <zewt> | well, it's a side-effect of the prescan |
| 16:19 | <zewt> | was just wondering if there was any magic to prevent things with side-effects from happening until the prescan finished |
| 16:20 | <annevk> | content-type header :) |
| 16:20 | <zewt> | fwiw, firefox doesn't execute the script above twice, just once (with the charset applied) |
| 16:20 | <annevk> | yes that's what I said |
| 16:21 | <annevk> | needs to be after 1024 octets |
| 16:21 | <annevk> | prescan goes over 1024 octets |
| 16:21 | <annevk> | after that the parser starts going |
| 16:21 | <annevk> | and then the parser finds the declaration, and boom |
| 16:21 | <zewt> | eh, i thought content-type metas had to be in the prescan; that's lame |
| 16:21 | <timeless> | annevk: you're not alone re extracting feedback |
| 16:22 | <timeless> | to be fair though, bugs.webkit seems to be just as annoying |
| 16:22 | <timeless> | (as a place where people leave comments that don't get upstreamed to w3) |
| 16:22 | <annevk> | zewt: I think hsivonen wanted that but I'm not sure it happened |
| 16:24 | <gsnedders> | annevk: What happens if the parser changed the encoding post pre-scan? |
| 16:24 | <zewt> | http://www.whatwg.org/specs/web-apps/current-work/multipage/parsing.html#changing-the-encoding-while-parsing happens |
| 16:25 | zewt | takes a breath and loads the singlepage version |
| 16:25 | <gsnedders> | zewt: Did you hit a sarcasm end tag? |
| 16:25 | <gsnedders> | (in the "in body" state) |
| 16:25 | <timeless> | hsivonen: seriously is that code line intentionally screwy or accidentally screwy? |
| 16:26 | <zewt> | hmm? i'm loading the singlepage version to get working references, heh |
| 16:29 | <zewt> | hmm, odd |
| 16:30 | <zewt> | <meta charset> seems to be allowed anywhere in head, whether in prescan or not (this isn't the "odd" part) |
| 16:30 | <zewt> | but the http-equiv=content-type method seems to only be mentioned in prescan |
| 16:32 | <zewt> | (the prescan seems to be designed under the assumption that if the prescan misses something, it'll always be fixed by the reparse, but that seems to only be the case for the former, not the latter?) |
| 16:48 | <annevk> | hsivonen: it was pretty difficult to make that table :( |
| 16:49 | <annevk> | hsivonen: I submitted something to www-archive now, hopefully it is of some value |
| 16:49 | <annevk> | hsivonen: http://lists.w3.org/Archives/Public/www-archive/2011Dec/att-0020/encoding-labels.html |
| 16:49 | <annevk> | hsivonen: unfortunately it does not list spec in relation to the browsers |
| 16:49 | <annevk> | hsivonen: maybe at some point |
| 16:50 | <zewt> | annevk: by the way, the references script seems broken on dom4 |
| 16:51 | <annevk> | oh shit, it excludes encodings supported by less than all four browsers |
| 16:51 | <annevk> | euh five |
| 16:51 | <annevk> | zewt: the script or the style sheet? |
| 16:52 | <zewt> | didn't look that closely, could be the css |
| 16:52 | <zewt> | don't know how that stuff is implemented |
| 16:52 | <zewt> | This interface is called HTMLCollection for historical reasons. The namedItem method returns an object for interfaces that inherit from this interface, which return other objects for historical reasons. |
| 16:52 | <Ms2ger> | It's been for a while, I think |
| 16:52 | <zewt> | ^ what interfaces inherit from HTMLCollection? hard to search for that |
| 16:53 | <Ms2ger> | HTMLAllCollection |
| 16:53 | <zewt> | (search engines are notoriously bad at searching for ": HTMLCollection") |
| 16:53 | <Ms2ger> | And various others in HTML |
| 16:54 | <zewt> | huh, I searched for it in HTML and it didn't come up (and I'm not even accidentally in case-sensitive mode); thanks |
| 17:07 | <zewt> | uhh, what? ie9 only defines window.console after the console has been opened? |
| 17:09 | <zewt> | aside from being seriously annoying and pointless, it also lets sites detect that the f12 window has been opened and go "error, browser debuggers are not allowed", heh |
| 18:06 | <dglazkov> | good morning, Whatwg! |
| 18:06 | <divya> | hai dglazkov |
| 18:07 | <dglazkov> | for your viewing pleasure: http://vimeo.com/33692624 |
| 18:25 | <annevk> | hsivonen: try http://lists.w3.org/Archives/Public/www-archive/2011Dec/att-0021/encoding-labels.html instead |
| 18:27 | <annevk> | also shows that maybe we should add certain labels |
| 18:27 | <annevk> | e.g. iso_8859-6 |
| 18:27 | <annevk> | there's a WebKit bug to that effect too (to add them for all iso- stuff) |
| 18:27 | <hsivonen> | annevk: thanks |
| 18:32 | <rillian_lime> | foolip: what do you think about (a) adding the IETF Opus audio codec to WebM and/or (b) adding a new, audio-only format using Opus as a baseline for <audio>? |
| 18:35 | <erlehmann> | rillian_lime, you can bet your gonads that will not fly with apple. |
| 18:36 | <hsivonen> | annevk: encoding stuff would suck slightly less if each encoding had exactly one label |
| 18:37 | <rillian_lime> | erlehmann: perhaps. I'm wondering if it's worth trying again. |
| 18:37 | <erlehmann> | rillian_lime, they haven't implemented support for *vorbis* even though it is in cheap chinese mp3 players. |
| 18:37 | <zewt> | hsivonen: the labels seem like the smallest problem, though, heh |
| 18:37 | <zewt> | though the huge variance in that table is pretty gross |
| 18:38 | <rillian_lime> | Opus is suffiently better for audio books that there might be some interest in adopting it as a separate format for <audio>, and it had a more "respectable" standarization process than Vorbis did |
| 18:39 | <erlehmann> | >implying its all about the process |
| 18:39 | <erlehmann> | >implying ALAC was necessary |
| 18:39 | <rillian_lime> | erlehmann: are you saying we shouldn't try again? |
| 18:40 | <erlehmann> | rillian_lime, i am not against trying. i am just saying that if apple engineers had any change of mind or command, they'd surely have come out of the woodwork and announced something. |
| 18:40 | <erlehmann> | well, actually they had a change of command. |
| 18:40 | <erlehmann> | or didn't they? |
| 18:41 | <erlehmann> | rillian_lime, also, “your multimedia codec is almost certainly patented” is a meme now. |
| 18:41 | <rillian_lime> | now? that's been a meme for years. |
| 18:41 | <erlehmann> | then it's an old meme now. |
| 18:41 | <erlehmann> | :3 |
| 18:41 | <zewt> | making the phrase "patent reform" actually mean "making patents stronger" was a genius move by whoever thought it up. heh |
| 18:43 | <rillian_lime> | anyway, I wanted to know what browser folks thought of the idea, not what they thought apple would think of the idea :/ |
| 18:44 | <rillian_lime> | zewt: a general problem with "reform" I think |
| 18:44 | <rillian_lime> | let's reform HTML! |
| 18:44 | <zewt> | (to mean what we want it to mean!) |
| 18:45 | <zewt> | i'd like to reform the money in your wallet into my wallet. sound ok? |
| 18:45 | <rillian_lime> | :) |
| 18:46 | <erlehmann> | rillian_lime, i am of the impression that any browser folks caring about the web already have wav and vorbis. those who don't let out one or both. also, since the spec is more descriptive than normative in regards to that, it makes at least some sence to think about what apple engineers would do. |
| 18:47 | <erlehmann> | sense |
| 18:58 | <annevk> | hsivonen: totally |
| 20:18 | <Velmont> | annevk: Yup, I had very little overview, and started with something known. :-) |
| 20:57 | <roc> | timeless: dbaron, bz, fantasai, heycam and tantek all spend a lot of time on spec feedback and editing |
| 20:57 | <roc> | timeless: fullscreen is a big thing that we initiated and specced (and annevk took over, bless him) |
| 20:57 | <Ms2ger> | And smaug complains a lot about specs :) |
| 20:59 | <roc> | Opus is a big spec effort |
| 21:00 | <Ms2ger> | And it's all over my newsgroups |
| 21:01 | <roc> | jonas and bent have been super-engaged evolving IndexedDB |
| 21:01 | <roc> | we have done a lot of WebGL spec work |
| 21:02 | <dbaron> | also other stuff in https://wiki.mozilla.org/Standards |
| 21:02 | <roc> | ha, there's a whole lot of stuff on that list that I'd forgotten about |
| 21:03 | <roc> | media fragments (I think we're the only browser vendor doing anything there, maybe that's not a good thing) |
| 21:03 | <Ms2ger> | Indie UI? |
| 21:04 | <hober> | Ms2ger: yes? |
| 21:05 | <Ms2ger> | What's that? |
| 21:05 | <roc> | let's not forget all the work Henri did to provide feedback to ensure the HTML parsing spec is Web-compatible |
| 21:05 | <TabAtkins> | roc: I wish we had someone doing Media Fragments work. ;_; |
| 21:05 | <hober> | Ms2ger: let me dig up a link for you |
| 21:06 | <hober> | Ms2ger: http://www.w3.org/2011/11/indie-ui-charter |
| 21:06 | <roc> | timeless: I sense you have some gripe about some specific group or project(s), in which case, let's hear it, but a blanket statement that Mozilla people aren't interested in standards is just ridiculous |
| 21:06 | <Ms2ger> | hober, that's what I was looking at |
| 21:07 | <Ms2ger> | I think |
| 21:07 | <zewt> | "indie" ui? randomly-chosen word? heh |
| 21:07 | <Ms2ger> | Yeah |
| 21:07 | <Ms2ger> | Bi-weekly telcons |
| 21:07 | <zewt> | i guess that's better than calling it "Web User Intents" ... |
| 21:08 | Ms2ger | doesn't expect much useful to come out of it, then |
| 21:10 | <TabAtkins> | ...I can only guess that it comes from INput-mode DEpendent |
| 21:10 | <TabAtkins> | Or, wait, duh, input method INDEpendent. |
| 21:10 | <zewt> | Ms2ger: well, telecons on top of list activity doesn't make a group less useful (though it definitely makes things less open) |
| 21:10 | <zewt> | i can't tell if there's a list attached to this, since half of the links point at "http://www.w3.org/2011/11/@@"; |
| 21:10 | <zewt> | (not that i'm especially interested in reading it anyway) |
| 21:10 | <Ms2ger> | IME, people spend more time on telcons and administrivia than on work |
| 21:10 | <zewt> | well i mean |
| 21:11 | <zewt> | nothing's more frustrating on spec lists than a reply that says "we talked about this in our telecon and here's the decision" |
| 21:11 | <zewt> | heh |
| 21:11 | <zewt> | (... or on any lists) |
| 21:11 | <TabAtkins> | Unfortunately, that interaction mode is easier for handling some types of things. |
| 21:12 | <zewt> | easier than lists, sometimes; easier than IRC or other realtime comms, no (not for me, ever) |
| 21:12 | <TabAtkins> | Does it make things better if the call it well-minuted and you can participate via IRC as well? |
| 21:12 | <zewt> | (well, face-to-face can be, of course, but comparing distributed comms) |
| 21:13 | <erlehmann> | i only do face-to-face with protocol or email. |
| 21:13 | <zewt> | whenever voice meetings are happening, everyone who isn't or can't actually be on the call becomes a second-class participant at best |
| 21:13 | <erlehmann> | only when i agree with someone and we have both similar targets, phone or chat becomes worthwile. |
| 21:13 | <Ms2ger> | That's true for all sync communication, though |
| 21:14 | <TabAtkins> | I find that sync comm can help resolve confusion/misunderstandings faster than async. |
| 21:14 | <zewt> | and text communications (eg. this) is a lot easier for people like me (interested parties but not implementors) to participate |
| 21:42 | <jamesr_> | i've found some w3c telecons favor abusive personalities over technical goodness |
| 21:42 | <jamesr_> | so i kind of hate them |
| 21:42 | <zewt> | they always favor loud people who talk over everyone else, heh |
| 21:42 | <jamesr_> | exactly |
| 21:42 | <zewt> | https://adblockplus.org/development-builds/allowing-acceptable-ads-in-adblock-plus aaand abp loses all of its credibility overnight |
| 21:44 | <jamesr_> | can you pay ABP to get on the acceptable list? |
| 21:45 | <zewt> | dunno, seems a thoroughly tempting thing for them to do though, heh |
| 22:10 | <Ms2ger> | Don't you love the integer constants in webrtc? |
| 22:11 | <TabAtkins> | Oh god, seriously? Man, that means I gotta yell at someone. |
| 22:11 | <Ms2ger> | Please do |
| 22:11 | <Ms2ger> | Then I don't have to |
| 22:19 | <TabAtkins> | I'm confused as to why the PeerConnection constants aren't all sequential. |
| 22:19 | <TabAtkins> | Is it meant to allow someone to compose them all into a bitfield? |
| 22:20 | <TabAtkins> | Also: Hm, I appear to have gained AC permissions in the W3C. |
| 22:21 | <TabAtkins> | Or this page is badly permissioned, and has horrible UI. |
| 22:21 | <TabAtkins> | (It thinks I'm T.V. Raman.) |
| 22:21 | <zewt> | i always have trouble finding PeerConnection-related specs; searches never find anything but lists |
| 22:22 | <TabAtkins> | The webrtc homepage has useful links. |
| 22:24 | <zewt> | what's the deal with these giganto parameter tables? what possible use are they? |
| 22:27 | <zewt> | TabAtkins: maybe the numbers map to protocol numbers, in a (somewhat strange) attempt to avoid having to translate? |
| 22:27 | <zewt> | (don't recall anything about the underlying protocol) |
| 22:27 | <TabAtkins> | Argh, I'm going to compromise my principles and send an HTML email so I can get decent ins/del-like formatting. |
| 22:27 | <TabAtkins> | zewt: I suspect that's the case. It's lazy design, though. |
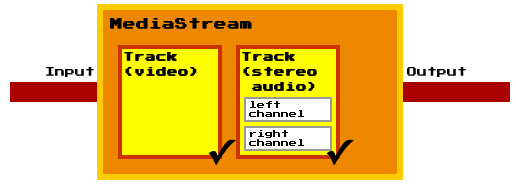
| 22:29 | <zewt> | http://dev.w3.org/2011/webrtc/editor/images/media-stream-1.png random image in spec is ... somewhat startling (and not terribly enlightening) |
| 22:30 | <TabAtkins> | Agree. Also, somewhat fuzzy, indicating poor scaling. |
| 22:30 | <TabAtkins> | Which is odd, since the check marks are well-scaled. |
| 22:30 | <zewt> | TabAtkins: it smells like this spec was made by someone who's only recently read the filesystem API spec, which is in much the same style (both the spec style, and the use of constant ints) |
| 22:31 | <Ms2ger> | TabAtkins, usually it shows AC-member-only forms as if you were the AC rep, with a note saying "you can't do this" |
| 22:31 | <TabAtkins> | zewt: The use of int constants is very common among anyone who primarily programs in C++ or Java (that is, most browser devs). |
| 22:32 | <TabAtkins> | Ms2ger: Yeah, that's usual. I *appear* to have the ability, though, to make Google leave the WebRTC group. The checkboxes and submit button are all enabled. |
| 22:32 | <Ms2ger> | Interesting |
| 22:33 | <zewt> | give it a shot, what could possibly go wrong? :P |
| 22:33 | <zewt> | what's the worst that could happen (two weeks later Google withdraws from the w3c and an asteroid strikes the planet) |
| 22:34 | <jamesr_> | a wild pack of lawyers appear! they use beatdown on TabAtkins. it's super effective! |
| 22:34 | <zewt> | TabAtkins: one would hope that anyone designing a web API would have a good deal of experience with existing APIs and current design practices, though |
| 22:34 | <TabAtkins> | zewt: One would hope, yes. |
| 22:34 | <zewt> | (for whatever vain level of "hope") |
| 22:34 | <TabAtkins> | zewt: One would be very, very disappointed. |
| 22:35 | <zewt> | TabAtkins: on the other hand, the editors list on this spec reduces one's hope |
| 22:35 | <zewt> | (nothing personal to those names; referring to the company list, except for Mozilla) |
| 22:36 | <zewt> | (i assume those constants weren't in there when hixie wrote the initial draft?) |
| 22:36 | <zewt> | (never mind the fs-api-ization of the whole thing) |
| 22:37 | <zewt> | at least where it really matters (eg. method algorithms), it hasn't gone that way |
| 22:40 | <zewt> | (i'm meaning to compare to the "file api: directories and system" spec, not File API; i suppose i should refer to the former as "file-system" or something) |
| 22:41 | <zewt> | roman numeral hostnames? heh |
| 22:42 | <TabAtkins> | All right, complaint about constants sent. |
| 22:48 | <MikeSmith> | https://twitter.com/#!/jarrednicholls/status/147804488848261120 |
| 22:48 | <MikeSmith> | "I just added support for XMLHttpRequest.responseXML to handle HTML documents http://t.co/HaRiuLoa http://t.co/wipNrLVu #WebKit" |
| 22:49 | <TabAtkins> | Yessssssss |
| 22:49 | <MikeSmith> | so already landed in Firefox and shipping in FF10 |
| 22:49 | <MikeSmith> | and now Webkit too |
| 22:49 | <MikeSmith> | annevk: ↑ |
| 22:49 | <MikeSmith> | oh |
| 22:49 | <TabAtkins> | With that in place, it's finally easy to do an easy upgrade to ajax-based navigation by swapping out sections. |
| 22:50 | <MikeSmith> | this doesn't add support for json yet, I don't think |
| 23:10 | <Hixie> | huh |
| 23:11 | <Hixie> | someone points out that the <input type=""> sections don't actually include the keyword needed to trigger them |
| 23:11 | <Hixie> | that's kinda silly of me |
| 23:11 | <Hixie> | i wonder where to put them |
| 23:12 | <Hixie> | in the heading? ("Text state (type=text) and Search state (type=search)") In the first paragraph? In examples? |
| 23:12 | <Hixie> | wouldn't be bad to add examples in general, i guess |
| 23:12 | <TabAtkins> | I like the headings. |
| 23:12 | <TabAtkins> | So you can see them in the TOC easily. |
| 23:12 | <Hixie> | yeah, that's probably reasonable |
| 23:12 | <Hixie> | curses |
| 23:13 | <TabAtkins> | Why curses? |
| 23:13 | <Hixie> | means work |
| 23:13 | <TabAtkins> | Come here and I'll pat you on the head. Specs is hard. |
| 23:13 | <Hixie> | don't i know it |
| 23:14 | <Hixie> | "(type=hidden)" or "(type="hidden")"? |
| 23:14 | <TabAtkins> | The first. |
| 23:14 | <Hixie> | k |
| 23:14 | <Hixie> | (type=hidden) or ("type=hidden") ? |
| 23:15 | <TabAtkins> | Hm. I think the first. |
| 23:15 | <Hixie> | k |
{kind=link}