| 00:12 | <styfle> | Thanks! I updated the readme and transferred it to the org: https://github.com/tc39-transfer/proposal-import-bytes |
| 17:06 | <bakkot> | queue needs to be advanced I think |
| 17:06 | <Michael Ficarra> | reminder: add your slides links to the notes |
| 17:10 | <nicolo-ribaudo> | Does anybody have the link to share here? |
| 17:11 | <nicolo-ribaudo> | Also, I still see the queue at the notetakers item |
| 17:13 | <Justin Ridgewell> | I advanced the queue |
| 17:20 | <Chris de Almeida> | if this gets stage 2, don't let us forget to assign reviewers 😇 |
| 17:25 | <ljharb> | kevin, those don't cover symbols, only strings (re tcq) |
| 17:26 | <ljharb> | but if you mean the weird API design part, yes, and it's gross |
| 17:30 | <nicolo-ribaudo> | Are there use cases for having just the number of symbols? |
| 17:31 | <Michael Ficarra> | I like the -Length functions design |
| 17:31 | <nicolo-ribaudo> | The readme has a ton of links, last time I asked to write for the various links which option they are supporting, but it has not been done, so it's difficult to actually navigate through them |
| 17:32 | <kriskowal> | I like -Length and has- as a mnemonic pattern. |
| 17:32 | <nicolo-ribaudo> | I really struggle to imagine use cases other than for:
maybe with the matrix of "include all properties, or just string properties" |
| 17:34 | <kriskowal> | MarkM wrote a summary of property enumeration for our own edification at Agoric/Endo and I captured them for posterity here https://kriskowal.com/enumerating-properties/ |
| 17:37 | <Michael Ficarra> | steal time from the other presentations? |
| 17:37 | <ljharb> | @erights Mark Miller (Agoric) MM: fwiw it does whatever you'd expect it to do on proxies, via the internal methods, just like the existing methods |
| 17:38 | <bakkot> | Ruben: assuming you mean https://github.com/tc39/proposal-object-property-count/issues/2#issuecomment-2784901702, many of those examples are devtools or otherwise not super relevant (like babel's object spread helper) |
| 17:38 | <Richard Gibson> | I don't think "whatever you'd expect" is coherent, because property keys are reported by one trap while property attributes are reported by another, so the two can disagree |
| 17:39 | <ljharb> | i mean, in terms of impact - babel's object spread helper alone being made faster is probably more beneficial to the web than many of the proposals we've advanced in the last couple years |
| 17:39 | <bakkot> | the spread operator isn't doing a count, to be clear |
| 17:39 | <ljharb> | ah, ok fair. the current spec did make a choice, iirc it's calling "ownpropertykeys" |
| 17:39 | <bakkot> | it's actually spreading enumerable symbols |
| 17:39 | <ljharb> | ah k |
| 17:39 | <bakkot> | so it isn't relevant to this proposal |
| 17:41 | <Richard Gibson> | right, but that doesn't expose enumerability |
| 17:41 | <ljharb> | it has to get the property descriptor for each key as well, yep |
| 17:42 | <ljharb> | same approach as https://tc39.es/ecma262/#sec-object.getownpropertydescriptors, iirc |
| 17:42 | <bakkot> | I still like my "just add fooLength versions of all the foo methods" suggestion, which answers this trivially |
| 17:42 | <Richard Gibson> | so the question basically comes down to: what happens when getOwnPropertyDescriptor reports nonexistence of a key that was returned from ownKeys? |
| 17:43 | <ljharb> | the same thing that Object.getOwnPropertyDescriptors does - it skips it |
| 17:43 | <Ashley Claymore> | What happens is you know you've found a proxy |
| 17:44 | <nicolo-ribaudo> | | | enmumerable | non-enumerable | all | Fyi here the checkmark is for where I'm convinced that there may be a use case (the question mark is where I'm very little convinced but more than zero). I'd like to see examples showing that the usage of the rest is so widespread that it makes more sense to design an API to explicitly support it rather than just do the difference of the other two things in the same row/column. |
| 17:44 | <ljharb> | (tbh i'm not sure why it's important what happens with a misbehaving proxy as long as it accounts for it) |
| 17:44 | <nicolo-ribaudo> | Come on matrix |
| 17:44 | <nicolo-ribaudo> | Because a 3x3 matrix with only the corners filled in is just a complete 2x2 matrix |
| 17:44 | <ljharb> | i often need all symbols |
| 17:44 | <nicolo-ribaudo> | Can you show me one code example? |
| 17:45 | <bakkot> | I have ever needed all symbols but I don't think I've ever need the number of all symbols |
| 17:45 | <ljharb> | true, the code example i was about to provide isn't getting the count, let me look more |
| 17:53 | <ljharb> | k well i can't actually find a case where i need the count of symbols and not the actual symbols themselves |
| 17:54 | <ljharb> | although if getting the count was much faster than getting the symbols themselves, i'd probably change a bunch of places to check the count first - that's a lot of "if"s tho |
| 17:57 | <Ashley Claymore> | arr.toSliced() will give you a dense array even if the original had holes |
| 17:57 | <Ashley Claymore> | oh no, not that one that my brain llm made up |
| 17:57 | <Ashley Claymore> | The other ones |
| 17:58 | <bakkot> |
doesn't give you (string + symbol) x (enumerable) though I guess I would be open to a proposal for a new way to get values for (string + symbol) x (enumerable), and then also have the |
| 18:00 | <Richard Gibson> | that method doesn't exist, but arr.toSpliced() does |
| 18:00 | <ljharb> | .slice() |
| 18:00 | <Richard Gibson> | nope, .slice() preserves holes |
| 18:00 | <ljharb> | oh oof, ok |
| 18:01 | <ljharb> | .flatMap(x => [x]) :-p |
| 18:01 | <ljharb> | so like, Reflect.ownEnumerableKeys? |
| 18:01 | <bakkot> | yeah sure |
| 18:03 | <Richard Gibson> | seeing those written out, I would prefer "count" rather than "length" |
| 18:03 | <snek> | [...array] kills holes right |
| 18:03 | <snek> | and ensures you have a real array |
| 18:03 | <snek> | all in one glorious expression |
| 18:04 | <rbuckton> | Yes, though holes are removed rather than replaced with undefined, so indices to elements change. |
| 18:04 | <Chris de Almeida> | nicolo-ribaudo: your topic is still in the queue |
| 18:04 | <Chris de Almeida> | (next) |
| 18:04 | <snek> | looks like they are replaced with undefined |
| 18:05 | <ljharb> | a glorious one that uses the much slower iterator protocol :-( |
| 18:05 | <ljharb> | Array.from() might work tho |
| 18:05 | <snek> | Array.from does it too |
| 18:05 | <snek> | both are probably better optimization targets than isSparse branches |
| 18:05 | <waldemar> | +1 on Nicolo's comment |
| 18:06 | <Richard Gibson> | .toSpliced() does not use Symbol.iterator |
| 18:06 | <ljharb> | the problem tho isn't "we don't want sparse arrays", it's "to accurately describe this object we need to know if it's sparse", so densification doesn't help |
| 18:07 | <Justin Ridgewell> | My topic: we can solve this with the previous property count proposal. |
| 18:07 | <Justin Ridgewell> | We don't need a sparse check that depends on internal engine details |
| 18:07 | <nicolo-ribaudo> | Wouldn;t [1, , 3, foo: 4] look like it's dense |
| 18:07 | <Justin Ridgewell> | A dense array has Object.keys(arr).length === arr.length |
| 18:07 | <Richard Gibson> | only if there's an "index" filter |
| 18:07 | <Justin Ridgewell> | No |
| 18:07 | <Justin Ridgewell> | Yes |
| 18:07 | <nicolo-ribaudo> | It has three properties and a length of three |
| 18:07 | <nicolo-ribaudo> | Oh ok |
| 18:08 | <Justin Ridgewell> | It has 2 index properties |
| 18:08 | <nicolo-ribaudo> | Well, Object.keys(arr).length === arr.length returns true on that |
| 18:08 | <Justin Ridgewell> | That's why we need the property count proposal |
| 18:09 | <Justin Ridgewell> | I was giving a really basic case |
| 18:09 | <Justin Ridgewell> | But we can build on the previous proposal for "sparse" checks |
| 18:09 | <nicolo-ribaudo> | My point about time-of-check vs time-of-use still stands though |
| 18:09 | <Justin Ridgewell> | Yes |
| 18:09 | <nicolo-ribaudo> | Even if you check like that |
| 18:09 | <waldemar> | {0: 0, 1: 0, 3: 0, 17: 0, length: 4} would have a length of 4 and four index-named properties |
| 18:11 | <ljharb> | but it'd not be Array.isArray. almost all these use cases are inside a context where that's already been checked |
| 18:11 | <Justin Ridgewell> | I thought the proposal only worked on Arrays |
| 18:13 | <waldemar> | That's still being debated. |
| 18:13 | <rbuckton> | I continue to wish JS had syntax and semantics for custom indexers, much like how TypedArrays are handled. This proposal brings that back to mind. |
| 18:13 | <Chris de Almeida> | we are going to go over time most likely. please indicate your preference: 🦆 - continue the meeting into the lunch break, and conclude plenary 🐓 - break for lunch, and return after to continue meeting ,then conclude |
| 18:14 | <Justin Ridgewell> | Wouldn't any handling of array-like (specifically excluding arrays here) have to be linear? |
| 18:14 | <Justin Ridgewell> | We could just implement in userland, there's no benefit of a native API |
| 18:15 | <waldemar> | Yes, it would be linear. But, given today's comments, a lot of cases on Arrays would also be linear. |
| 18:15 | <Justin Ridgewell> | Not if we use property count, since the length is 🪄 |
| 18:16 | <Justin Ridgewell> | Index keys are stored in a special array (in V8), and length is always guaranteed to be the max index's value +1. |
| 18:16 | <Justin Ridgewell> | So the check could be constant for arrays specifically |
| 18:17 | <waldemar> | So you're saying that it is possible to implement Array.isSparse in O(1) time? |
| 18:18 | <Justin Ridgewell> | In V8 at least, without depending on the element's kind internal stucture. |
| 18:18 | <Justin Ridgewell> | Don't know about the other engines, but they had to implement special ordering rules for Object.keys(), so they may have index keys stored separately. |
| 18:22 | <nicolo-ribaudo> | Only Object.keys and Object.propertyCount, passing as the second parameter a bitflag to do all the filtering 🧠 |
| 18:23 | <Richard Gibson> | now you're thinking like a 1990s DOM API 😎 |
| 18:25 | <snek> | proposal: add a one true Object.getPropertyNames which accepts this options bag: https://docs.rs/v8/latest/v8/struct.GetPropertyNamesArgs.html |
| 18:29 | <Olivier Flückiger> | no. it's O(1) to skip indices (which might or might not have holes) |
| 18:29 | <rbuckton> | Rather than using 'all' to fight defaults, why not have these APIs always include everything by default and use the presence and value of enumerable et al to control behavior, much like defineProperty (which ignores missing attributes as long as the property already exists). |
| 18:31 | <Justin Ridgewell> | This response seems like a negative of a negative? I'm not sure how to understand it. |
| 18:31 | <rbuckton> | for this API and propertyCount, have it be propertyCount(target) to count all properties, and use propertyCount(target, { enumerable: true }) to count only enumerable keys. Much like how getOwnPropertyKeys gets all own keys |
| 18:33 | <Olivier Flückiger> | We can give you the max index. but not tell you how many elements up to that index exist in the array. |
| 18:33 | <nicolo-ribaudo> | +1, maybe calling it enumerableOnly |
| 18:33 | <Justin Ridgewell> | It should be the count of the index keys array, right? |
| 18:33 | <Olivier Flückiger> | which is implicitly defined by not being a hole in the array backing store... |
| 18:34 | <bakkot> | has anyone ever enumerated a sufficiently large typed array to observe this |
| 18:34 | <Justin Ridgewell> | Does a the hole have an entry in the index keys arrays? |
| 18:35 | <Olivier Flückiger> | we don't separately store keys for arrays |
| 18:35 | <bakkot> | I don't think the thing Richard said is true |
| 18:35 | <bakkot> | Richard Gibson: https://tc39.es/ecma262/multipage/ordinary-and-exotic-objects-behaviours.html#sec-typedarray-ownpropertykeys |
| 18:36 | <bakkot> | exotic objects are allowed to have different key enumeration order than the default array-index-first behavior that ordinary objects have |
| 18:37 | <ljharb> | i agree with you; TAs already cover that |
| 18:37 | <Richard Gibson> | ack, I accept the correction |
| 18:38 | <rbuckton> | I'm a fan of just mirroring the attribute names, in the event we ever care about also supporting configurable or writable |
| 18:39 | <ljharb> | if it's called enumerable tho then it can't cover "all" |
| 18:39 | <ljharb> | only true and false |
| 18:39 | <nicolo-ribaudo> | The reason I suggested that is that enumerable: true could either be "include enumerable keys" or "include only enumerable keys" |
| 18:39 | <rbuckton> | It can cover it by being missing or undefined, just like how defineProperty handles it for existing properties. |
| 18:40 | <ljharb> | true, but it's very awkward to have a three-state boolean, and in this case the default would be true, and boolean option should always default to false when absent |
| 18:40 | <rbuckton> | i.e.:
|
| 18:40 | <ljharb> | also if we added "writable" how would it work with accessor properties, i don't think we could ever add that one |
| 18:41 | <keith_miller> | Named String and Symbol properties are mixed in JSC's Structures |
| 18:41 | <keith_miller> | That said, it's easy enough to skip over the symbols and we already have that functionality |
| 18:41 | <snek> | whether a setter is present? |
| 18:41 | <rbuckton> | If we ever wanted anything that detailed, we could use propertyCount(t, { writable: true }) + propertyCount(t, { set: true }) |
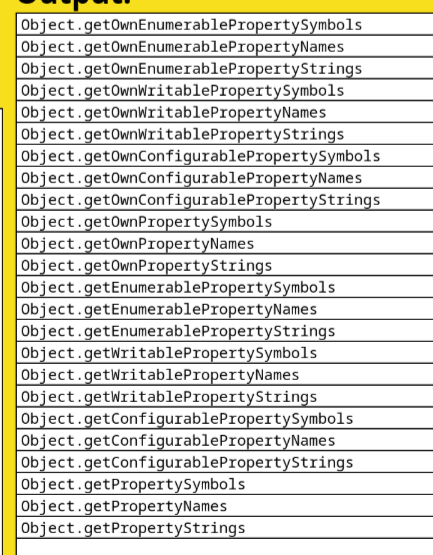
| 18:42 | <Michael Ficarra> | Object.getOwnEnumerablePropertySymbols, can we go home now? |
| 18:42 | <ljharb> | lol but i mean, if you say "true" or "false" then you're skipping all accessor properties? |
| 18:42 | <ljharb> | so the mirroring is broken because the type of set no longer matches |
| 18:42 | <nicolo-ribaudo> | I have to leave now, but I'm +1 on this array indexes proposal going to stage 1, and -1 on the first two advancing. For the first one until the use cases for the various combinations are clarified with actual examples, then it'll turn into +1 at a future meeting. For the one about isSparse I'm not convinced that it's what actually is needed to get a fast path. (cc ryzokuken as both Igalian and chair :P) |
| 18:43 | <waldemar> | What is doable in O(1)? Getting the total number of properties? Getting the number of indexed properties? Nonindexed properties? |
| 18:43 | <bakkot> | Object.symbols, surely |
| 18:44 | <rbuckton> | My concern with having a bunch of methods on Object over the property bag is that it is inflexible without the number of similar property names on Object ballooning out of control. I wouldn't look forward to scrolling through the autocomplete list for that case. An options bag keeps the API rational and flexible. |
| 18:44 | <ljharb> | and, as i argued earlier, more discoverable |
| 18:44 | <bakkot> | we already have almost the whole matrix |
| 18:44 | <Michael Ficarra> | WFM |
| 18:44 | <bakkot> | we have Object.keys, Reflect.ownKeys, Object.getOwnPropertyNames, Object.getOwnPropertySymbols |
| 18:44 | <bakkot> | these are all their own method |
| 18:44 | <Olivier Flückiger> | Probably number of nonindexed properties (but I would have to think about it) and if the array happens to have a particular internal shape, then the number of indexed propoerties. |
| 18:45 | <ljharb> | Object.symbols, but don't forget Object.symbolValues and Object.symbolEntries |
| 18:45 | <rbuckton> | Its still similar enough, IMO. |
| 18:45 | <bakkot> | any new thing in this matrix should also be its own method |
| 18:45 | <ljharb> | and if we add Object.symbols() then what about a .symbols() iterator method on Set/Map/Array? |
| 18:45 | <bakkot> | entries is not an item in this matrix; there's only one of it |
| 18:45 | <rbuckton> | And they could just be one method with options that allows for future extensibility without adding even more methods to Object. |
| 18:45 | <bakkot> | why would we want that? |
| 18:45 | <ljharb> | lol i'm just saying that we have a LOT of keys/values/entries parallels |
| 18:46 | <bakkot> | but they all already exist |
| 18:46 | <snek> | javascript i have seen your future https://gc.gy/d452a7e4-49d7-4b50-be21-ce3f6cdc0fb4.png |
| 18:46 | <ljharb> | if your argument for method over option bag is "filling in the matrix", then we have a much larger matrix to fill in |
| 18:46 | <bakkot> | no my argument is if we are filling in part of the matrix then it must be in keeping with the rest of the existing matrix |
| 18:46 | <Michael Ficarra> | you failed to predict when we add a new kind of property key in 2028 |
| 18:46 | <ljharb> | and the matrix includes keys/values/entries on Object/Set/Map/Array. |
| 18:46 | <snek> | getOwnPropertyDecimals |
| 18:47 | <bakkot> | that is a matrix but is not the one we are talking about, no |
| 18:47 | <rbuckton> | That approach doesn't scale to a larger number of permutations. |
| 18:47 | <bakkot> | it is just not relevant at all |
| 18:47 | <bakkot> | there's no more permutations |
| 18:47 | <bakkot> | if we start doing configurable vs not or whatever, we can do that as options bags |
| 18:50 | <rbuckton> | The fact that keys vs getOwnPropertyNames differentiates by enumerability is definitely non-obvious to a new developer. |
| 18:50 | <bakkot> | I agree but it is how it works |
| 18:50 | <bakkot> | we can't say "the existing methods names are not sufficiently obvious so we're going to add a new way" |
| 18:50 | <ljharb> | why can't we? |
| 18:50 | <snek> | i would personally not put filling out matrixes over like how we have learned to design better apis from the last 25 years |
| 18:50 | <Richard Gibson> | for generic property key enumeration, I think the current (incomplete) matrix is {string, symbol, both} × {enumerable, ignore-enumerability} |
| 18:51 | <bakkot> | that is a matrix but { string, symbol } x { enumerable, all } is another matrix, which has three entries, and this is the fourth entry in that matrix |
| 18:51 | <rbuckton> | That sounds like a perfectly valid reason to consider a different design for an API. |
| 18:51 | <bakkot> | the very slightest modicum of taste? |
| 18:52 | <ljharb> | taste is a subjective thing, and my taste tends to consider "deprecate the bad thing, make a much better new thing" more pleasant than "never learn from our mistakes" |
| 18:53 | <Richard Gibson> | I disagree that such a reduced matrix is relevant, but don't want to complete either for their own sake anyway |
| 18:53 | <bakkot> | it is a fine reason to consider designing new APIs in a different way, when they are not just extensions of the existing API |
| 18:53 | <bakkot> | I strongly agree that we don't want to complete either for their own sake and have said as much on several occasions |
| 18:53 | <bakkot> | however, if we are filling a matrix of functionality then it must match the existing parts of the matrix |
| 18:53 | <Michael Ficarra> | Same, where it matters a whole lot, like with avoiding coercions. This does not matter a whole lot. |
| 18:54 | <ljharb> | "matter" is also subjective :-) |
| 18:55 | <Michael Ficarra> | aesthetics is at the bottom of the mattering ladder |
| 18:55 | <rbuckton> | Shifting from a 2x2 matrix to a 3x3 matrix when there is potential to shift to an n x n matrix seems like enough of a trigger to me. |
| 18:55 | <ljharb> | PropertyReflectionFactoryBean, then |
| 18:55 | <Richard Gibson> | I strongly disagree with this, for reasons that align with statements from others above. In short, the current representation is bad and should not be extended, although reworking might be appropriate |
| 18:55 | <bakkot> | but this proposal is not shifting from a 2x2 matrix to a 3x3 matrix |
| 18:56 | <keith_miller> | Have folks actually seen these enumeration+filters show up as a meaningful point of performance overheads? I don't think I've ever seen this as a hotspot any traces from benchmarks or live sites. |
| 18:57 | <Justin Ridgewell> | Mostly comes up in development and testing |
| 18:57 | <keith_miller> | I'm sure you can make a microbenchmark but in large codebases |
| 18:57 | <ljharb> | ruben's experience in node is directly having it be very meaningful |
| 18:57 | <bakkot> | node's experience does not generalize to the web at all |
| 18:57 | <Justin Ridgewell> | I don't think this is expected in prod code |
| 18:57 | <ljharb> | sure, not claiming it does |
| 18:57 | <ljharb> | production code does value inspection quite often, in the web and in node, sometimes in failure paths but not always. |
| 18:58 | <Richard Gibson> | Agoric code enumerates object properties as part of shape verification |
| 18:58 | <keith_miller> | Sure, but failure paths are not usually ™️ hot though |
| 18:58 | <Richard Gibson> | not limited to failure paths |
| 18:58 | <ljharb> | sure, which is why i said "not always" :-) |
| 18:59 | <Justin Ridgewell> | Making tests and logging faster would be valuable for me as the dev, but unlikely to impact my users. |
| 18:59 | <bakkot> | for extremely obscure things, I can maybe buy this on a case-by-case basis, if there's some hope people might migrate off of the current representation. but Object.keys is the opposite of obscure |
| 19:00 | <Richard Gibson> | the presence of Object.keys is not obscure, but ignoring Symbol-keyed and non-enumerable properties is |
| 19:02 | <Justin Ridgewell> | I think using symbols is obscure. And making non-enumerables (outside prototype methods) |
| 19:03 | <Michael Ficarra> | 🕰️ remember to leave time if we're looking for stage advacnement |
| 19:04 | <bakkot> | like, to be clear, the proposal is:
|
| 19:04 | <bakkot> | that is extremely unpleasant to me |
| 19:04 | <bakkot> | we are not doing that |
| 19:04 | <Chris de Almeida> | tempted to break for lunch and come back.. my fear is that the calls for advancement may take more time than we think |
| 19:04 | <ljharb> | fwiw i can't come back after lunch; i'd planned on not going late |
| 19:04 | <Chris de Almeida> | though the ducks did win out easily over the chickens |
| 19:04 | <Michael Ficarra> | I am not coming back |
| 19:06 | <Michael Ficarra> | it's easy to make a call for advancement go fast FWIW |
| 19:06 | <Michael Ficarra> | "if it's not blocking, I don't want to hear it" |
| 19:06 | <Michael Ficarra> | we can do all 4 in under a minute if we do it right |
| 19:06 | <ljharb> | you think it's easy to get an entire group of language pedants to willingly not voice their opinion? O.o |
| 19:06 | <Richard Gibson> | I agree with not doing that. But an alternative is introducing a single new thing that handles all four of those. |
| 19:07 | <Michael Ficarra> | yes, admins have a mute button |
| 19:07 | <keith_miller> | To further clarify, optimizing the enumerability is somewhat difficult in the semi-optimizing tiers of an engine because it's hard to prove how the JS is going to use the result of the getOwnPropertyDescriptor object without doing a full escape analysis. |
| 19:07 | <bakkot> | How do you get all own strings? Object.getOwnPropertyNames() How do you get all own symbols? Object.getOwnPropertySymbols() How do you get enumerable own keys? Object.keys() How do you get enumerable own symbols? Object.getEveryPossibleCombination({ kind: 'symbols', enumerable: true }) this is not better |
| 19:08 | <ljharb> | in that world you'd change the answer to the first 3 to use the new method |
| 19:08 | <Michael Ficarra> | y'all are lucky I'm not a chair because I would be so much stricter than our current chairs |
| 19:08 | <ljharb> | and the first 3 would just be marked legacy |
| 19:08 | <bakkot> | if these were very very obscure you might have some hope of that |
| 19:08 | <bakkot> | Object.keys is not obscure and never will be |
| 19:08 | <ljharb> | true. the others are very obscure tho |
| 19:09 | <Richard Gibson> | but the others are |
| 19:09 | <rbuckton> | This is still an API that doesn't scale if you consider propertyCount or other APIs that would filter the results (like getNonIndexPropertyNames, etc.). From a blank slate, I would strongly have preferred an API like getPropertyNames(o, { own, enumerable, ... }) and propertyCount(o, { own, enumerable, ... }) than repeating 3-4 static methods for each output type. |
| 19:10 | <bakkot> | it scales fine, just tack "Count" on the end of all of those |
| 19:10 | <bakkot> | this is my preferred solution |
| 19:11 | <ljharb> | in a world where we trimmed dozens of methods from Temporal because browsers don't want to add a ton of methods? |
| 19:11 | <rbuckton> | i.e., getPropertyNames(o, { own: true, symbol: false }) -> getOwnPropertyNames(o), getPropertyNames(o, { own: true, enumerable: true, symbol: false }) -> keys(o), etc. |
| 19:11 | <bakkot> | I agree from a blank slate we would probably do something different but this is javascript, the slate is never blank |
| 19:12 | <ljharb> | like in the same way as browser implementation reality has basically meant "no new array prototype methods", aren't we already in the world of "minimize the number of added methods"? which would strongly push options bags as The Way to add stuff when it makes sense? |
| 19:12 | <bakkot> | to be clear I do not insist on a separate fooCount method being the solution to counting thing, just that I would be fine with that outcome |
| 19:12 | <Justin Ridgewell> | DIdn't we split this from a super-everything API a few meetings ago? |
| 19:12 | <bakkot> | we do not already have fooCount methods so we can do those however we'd like |
| 19:13 | <rbuckton> | It is, however, indicative of a preferred state. We only have ~3 methods in this category for now. this doubles that and more, and any other permutations would result in needing to switch and leave behind now 6-8 "legacy" methods. |
| 19:13 | <rbuckton> | I don't look forward to completions for Object.getOwn| expanding to a large list you have to scroll through to get the correct method. |
| 19:14 | <nicolo-ribaudo> | What was the consensus outcome, for those that left earlier? |
| 19:14 | <Chris de Almeida> | 😑 |
| 19:14 | <snek> | Object.iterateProperties().filter(x => typeof x.name === 'symbol' && x.enumerable).reduce((c, _) => c + 1, 0) |
| 19:14 | <Michael Ficarra> | I actually look forward to this |
| 19:15 | <bakkot> | "this" does not double that, "this" is literally just Object.symbols (or some other name), I am only insisting on Object.symbols specifically as the solution to the "get enumerable own symbols" |
| 19:15 | <Michael Ficarra> | there has been no request for consensus on anything yet |
| 19:16 | <nicolo-ribaudo> | Ugh good luck |
| 19:16 | <bakkot> | I have not claimed and do not believe this means we have to add a bunch of other methods as the solution to other problems |
| 19:16 | <ljharb> | that would destroy discoverability, much like how you can't meaningfully read through the list of methods on window anymore |
| 19:17 | <rbuckton> | IMO, Object.keys() is a terrible name that does not accurately describe what it does. Object.symbols() would be going down the wrong track, IMO. |
| 19:17 | <rbuckton> | I'd much rather have a more descriptive getOwnEnumerablePropertySymbols than symbols for clarity. |
| 19:18 | <ljharb> | none yet, still going |
| 19:18 | <rbuckton> | I'll admit I needed to check the documentation for keys to clarify whether it return only own keys or inherited keys. It's a terrible name. |
| 19:19 | <Richard Gibson> | I'm very much against adding a plethora of new functions. But if the only introduction here is "get enumerable own symbols", then I agree with bakkot that it must be Object.symbols. |
| 19:20 | <ljharb> | only own |
| 19:20 | <ljharb> | nothing returns inherited keys |
| 19:20 | <bakkot> | Object.keys is not a great name but it's also among the most widely used methods in the language, we are not getting away from it |
| 19:27 | <Chris de Almeida> | I meant 'elder' as in experience, not age! 😄 |
| 19:27 | <rbuckton> | True, but that doesn't mean we should continue down that path. |
| 19:31 | <kriskowal> | I’ll take a gander. Thank you. |
| 19:32 | <Chris de Almeida> | I forgot to thank our note-takers: thank you all very much! 👏👏👏👏👏👏👏 |
| 23:32 | <ljharb> | k well my matrix is taking forever to send messages, and i have to run anyways, so i'm off 👋 |
{kind=link}