| 00:02 | <drousso> | jridgewell can I assist in writing tests? |
| 00:03 | <jridgewell> | I have 0 tests... |
| 00:04 | <jridgewell> | How would you like to test? |
| 00:04 | <jridgewell> | help** |
| 00:06 | <drousso> | no idea lol |
| 00:07 | <drousso> | just thought i'd offer, given that i already have something testable ;P |
| 00:07 | <drousso> | i've never written anything test262, but am keen to learn :) |
| 00:07 | <jridgewell> | Maybe if you could make a list of the things you think we should test? |
| 00:07 | <jridgewell> | I have also never written a test262 test... |
| 00:10 | <devsnek> | aim for 100% coverage https://coveralls.io/builds/29699669/source?filename=src/runtime-semantics/AssignmentExpression.mjs |
| 00:10 | <devsnek> | unfortunately most of my parser is a dependency so i can't get good coverage data out of that |
| 00:11 | <rkirsling> | it would be super ideal if you could just be like "hey, when this holds, just do exactly what = is already doing" but given that it's a totally separate operator you basically need to do all the same tests again... :( |
| 00:12 | <devsnek> | use ai to merge `+=` tests with `||` tests |
| 00:13 | <rkirsling> | AI? In *my* parser? |
| 00:13 | <rkirsling> | ljharb: is this still somewhere on the editor group docket? https://github.com/tc39/ecma262/pull/1860 |
| 00:14 | <drousso> | jridgewell i'll see if I can come up with a list tonight |
| 00:14 | <devsnek> | drousso: are y'all able to get coverage from bytecode and stuff |
| 00:14 | <ljharb> | rkirsling: it's not, but i can add it |
| 00:14 | <drousso> | i already have a bunch of the straightforward cases either implemented or discussed in <https://webkit.org/b/209716>; |
| 00:15 | <drousso> | devsnek i don't know, i'm a noob with JSC 😅 |
| 00:15 | <drousso> | i did this work partly to try to learn more |
| 00:15 | <rkirsling> | ljharb: much obliged |
| 00:15 | <drousso> | CC keith_miller msaboff |
| 00:16 | <devsnek> | if it can't, engine262 can do `npm run coverage` for an html which might be useful |
| 00:17 | <devsnek> | you could also do `./node_modules/.bin/nyc node test/test262/test262.js test/language/whatever-logical-assignment-tests**` |
| 00:19 | <rkirsling> | lol I'm pretty sure that's just engine262 though |
| 00:19 | <devsnek> | oh yeah that's just to verify the tests |
| 00:19 | <devsnek> | to some degree |
| 00:20 | <devsnek> | it doesn't tell you if all the engines will pass :P |
| 00:20 | <devsnek> | you'd need uh |
| 00:20 | <devsnek> | test262-harness for that |
| 00:39 | <rkirsling> | how does GH still not have a crying reaction |
| 00:39 | <rkirsling> | #stifledexpressivity |
| 00:41 | <rkirsling> | ljharb: should I update myself as the presenter for the forbidden extensions PR, if you were just hesitant to make me do it? |
| 05:21 | <ljharb> | rkirsling: absolutely! no need for a PR for that change either, just push a commit :-) |
| 15:40 | <bradleymeck> | what link are we using for hallway track? |
| 15:41 | <mpcsh> | I think this - https://hub.link/bHXk2f8 |
| 15:44 | <jridgewell> | Reminder that this chat is public. |
| 15:45 | <jridgewell> | Only share links in the Reflector. |
| 15:45 | <mpcsh> | this channel is private, right? only #tc39 is public I thought |
| 15:45 | <michaelficarra> | ugh |
| 15:45 | <devsnek> | this channel is public now too |
| 15:46 | <mpcsh> | oooof. sorry y'all, I didn't know that changed. |
| 15:46 | <michaelficarra> | it is publicly viewable, not open to public contributions |
| 15:46 | <michaelficarra> | it's understandable, this is only the second meeting where that's the case |
| 15:46 | <devsnek> | ystartsev: can a new link be generated |
| 15:46 | <michaelficarra> | it's easy enough to change the hubs link if we find unwanted users |
| 15:48 | <devsnek> | i'm going to have to deep clean my laptop from this zoom install |
| 15:49 | <devsnek> | zoom added code snippets apparently |
| 15:51 | <michaelficarra> | I don't even know what that means |
| 15:51 | <devsnek> | in the text chat |
| 15:51 | <devsnek> | we might need to have a no-zoom-text-chat rule btw |
| 15:52 | <michaelficarra> | yeah, at least for the sake of my sanity |
| 15:52 | <michaelficarra> | there's already enough places to follow during a meeting |
| 15:52 | <devsnek> | well for the public discussion rule as well, unless note takers are going to be summarizing the text chat |
| 15:53 | <michaelficarra> | yes I understood |
| 15:53 | <michaelficarra> | where do I find the TCQ link? |
| 15:53 | <michaelficarra> | it's not in the channel topic and not in the Reflector issue |
| 15:54 | <devsnek> | i'm not sure |
| 15:59 | <bradleymeck> | reflector |
| 16:07 | <apaprocki> | Is someone going to post the hubs URL to the Reflector issue? |
| 16:17 | <ystartsev> | devsnek: yep |
| 16:18 | <ystartsev> | apaprocki i can generate one |
| 16:25 | <bradleymeck> | its on the reflector now |
| 16:26 | <shu> | what's the idea for the hubs, are we supposed to idle there? |
| 16:26 | <shu> | or join it during breaks? |
| 16:27 | <ystartsev> | shu: either works |
| 16:27 | <ystartsev> | i do recommend reducing the settings so that it doesnt have the fan spinning all the time |
| 16:28 | <bradleymeck> | shu: i think idling during breaks at least allows people to start conversation in the way hallway track usually works |
| 16:28 | <devsnek> | i'm planning to join it during breaks |
| 16:28 | <bradleymeck> | if you don't idle there people can't approach in a public fashion, would have to do it via DMs etc. which plenary couldn't pick up on |
| 16:29 | <ystartsev> | bradley and i are in there already if people wanna join |
| 16:30 | <devsnek> | might need some contrast work https://usercontent.irccloud-cdn.com/file/MuiR0i0G/IMG_20200331_112945.jpg |
| 16:38 | <ystartsev> | should the room be more.. fun? |
| 16:39 | <rkirsling> | if you have to ask... ;) |
| 16:39 | <rkirsling> | (just kidding, I'm still making breakfast over here) |
| 16:39 | <drousso> | what does one do if one doesn't have a VR headset? :P |
| 16:40 | <bradleymeck> | drousso: you can just use WASD controls |
| 16:40 | <drousso> | nice! |
| 16:40 | <drousso> | is there a link? |
| 16:40 | <mpcsh> | reflector |
| 16:47 | <rkirsling> | there are some fun avatars in the Newest category hehe |
| 16:49 | <devsnek> | msaboff: |
| 16:49 | <devsnek> | oh oops |
| 16:55 | <robpalme> | over the next hour, folks are likely to request access details to dial in - in all cases please go to the Reflector link 275 (posted in the IRC channel subject) |
| 17:06 | <bradleymeck> | resolution 1x1 |
| 17:06 | <devsnek> | oh wow there are three pages of people |
| 17:07 | <ljharb> | it'd be great to keep chat to IRC, instead of zoom, during plenary stuff - it's hard enough to keep track of all the existing chat venues |
| 17:07 | <rkirsling> | yes please |
| 17:10 | <ljharb> | bterlson: heads up if you want to call on somebody, as the zoom host, you can unmute them (which asks them to confirm) but it gets their attention |
| 17:10 | <ystartsev> | there is also a stream of the zoom in the hub |
| 17:11 | <ljharb> | ystartsev: ah i didn't realize that, thanks |
| 17:11 | <Bakkot> | suggestion: introduce yourself the first time you talk |
| 17:11 | <caiolima> | lol for Keith's background |
| 17:11 | <rkirsling> | Bakkot: because that worked so well at JSConf EU :P |
| 17:11 | <rkirsling> | (half kidding, I think it will work better in plenary) |
| 17:12 | <Bakkot> | I wasn't there, so I will assume it worked perfectly |
| 17:12 | <rkirsling> | you didn't watch our panel on YouTube? 😱 |
| 17:12 | <rkirsling> | I'll link it in TDZ |
| 17:13 | <Bakkot> | I don't watch videos as a rule |
| 17:13 | <rkirsling> | that's...fair |
| 17:17 | <littledan> | akirose: If you're doing the schedule, i have my constraints updated here https://github.com/tc39/agendas/blob/master/2020/03.md#schedule-constraints |
| 17:17 | <littledan> | apologies for these being so last-minute |
| 17:17 | <akirose> | ty for letting me know |
| 17:20 | <robpalme> | We have four note-takers who have generously volunteered for this session ahead of time: Rick, Philip, Mark, and Jason! |
| 17:21 | <rkirsling> | 👏 |
| 17:21 | <littledan> | to clarify: invited experts only need to sign the IPR form *once ever*. No need to sign again for this meeting. |
| 17:27 | <devsnek> | akirose: are you using side-by-side mode? |
| 17:27 | <akirose> | i have no idea what that is |
| 17:28 | <devsnek> | oh to see rob at the same time as the slides |
| 17:28 | <akirose> | i have zoom full-screened and i'm flipping between it and the agenda schedule i'm working on |
| 17:28 | <ljharb> | devsnek: i see rob in the lower right corner, floating over the shared screen |
| 17:28 | <michaelficarra> | ooohh Oracle, that should be exciting |
| 17:28 | <devsnek> | aha full screen |
| 17:30 | <Bakkot> | would love to have graal people participating more |
| 17:38 | <bradleymeck> | i wonder how the trademark thing will go if they do join |
| 17:38 | <rkirsling> | bradleymeck: see tdz |
| 17:48 | <rwaldron> | bterlson the Test262 update is not on the TCQ agenda |
| 17:48 | <bterlson> | whoops I'll add it |
| 17:48 | <bterlson> | leo? |
| 17:48 | <bterlson> | doing it? or you for old times sake? :-P |
| 17:49 | <rwaldron> | Me |
| 17:55 | <rkirsling> | I wanted to blurt out "workin' on it" re JSC but didn't know whether that was a New Topic or what lol |
| 18:15 | <shu> | akirose: MylesBorins: bterlson: for the schedule, not sure if the agenda view on tcq is up-to-date, but please schedule the incubator call chartering to be sometime on the last day |
| 18:15 | <shu> | (as noted in the schedule constraints) |
| 18:15 | <MylesBorins> | I don't think it is up to date |
| 18:15 | <akirose> | it's not done yet, but i'll post the WIP schedule on the reflector |
| 18:16 | <shu> | ah okay, great |
| 18:17 | <rkirsling> | nice speediness there jridgewell :D |
| 18:17 | <jridgewell> | The tests aren't great… |
| 18:18 | <rkirsling> | yeah but officially nonzero |
| 18:18 | <jridgewell> | drousso might help me make more tests. |
| 18:18 | <rkirsling> | 👍 |
| 18:22 | <jackworks79> | test |
| 18:22 | <devsnek> | hello jackworks79 |
| 18:23 | <jackworks79> | does here a public IRC channel now? |
| 18:24 | <michaelficarra> | jackworks79: the public can view this IRC channel and read its logs, yes |
| 18:25 | <jridgewell> | jackworks79: Only delegates can message, though |
| 18:25 | <Bakkot> | #tc39 is the one which anyone can message |
| 18:25 | <Bakkot> | (which I'd encourage using most of the time, but not for discussing ongoing meeting stuff) |
| 18:29 | <akirose> | i need to apologize— Bakkot i'm asking you to go after lunch due to a scheduling constraint, maybe i'll ask s-h-u to do his PSA next instead. |
| 18:29 | <Bakkot> | yup seems fine |
| 18:29 | <akirose> | ty |
| 18:32 | <michaelficarra> | since when have we tried to prevent people from deadlocking themselves? |
| 18:33 | <devsnek> | the deadlock is that it will never wake up |
| 18:33 | <devsnek> | nothing can wake it |
| 18:35 | <michaelficarra> | while(1); |
| 18:36 | <Bakkot> | michaelficarra since we started trying to design a memory model usable by mortals |
| 18:36 | <Bakkot> | it is way less obvious when you've accidentally gotten into a deadlock with multithreading than when you just have an infinite loop, as a rule |
| 18:36 | <michaelficarra> | this was the single-threaded case though |
| 18:37 | <devsnek> | i think the design here is that you don't know if the buffer you're given is shared or not |
| 18:37 | <devsnek> | or more that you don't want to bother checking |
| 18:38 | <jackworks79> | one of my friend is doing this thing to block the main JS thread: |
| 18:38 | <michaelficarra> | devsnek: good point |
| 18:38 | <devsnek> | jridgewell: with those logical assignment tests v |
| 18:38 | <devsnek> | https://gc.gy/53384906.png |
| 18:38 | <devsnek> | 100% coverage of the runtime semantics! |
| 18:38 | <jackworks79> | with ({}) while (Atomics.load(...) === old) // blocking on the main thread |
| 18:39 | <jridgewell> | 😉 |
| 18:41 | <jackworks79> | he said "if you won't allowing me to lock (Atomics.wait) on the main thread, I'll use a more hacky and stupid (while loop to check spin lock) to lock the main thread" |
| 18:41 | <devsnek> | someone's audio is dying |
| 18:42 | <apaprocki> | I muted brian |
| 18:42 | <msaboff> | ty |
| 18:42 | <apaprocki> | somehow I wound up with host privs so I used them :P |
| 18:42 | <msaboff> | drunk with power |
| 18:44 | <bradleymeck> | jackworks79: correct, but thats a spin lock instead of a full on sleep |
| 18:46 | <mathiasbynens> | 0 is the new NaN, folks |
| 18:46 | <jackworks79> | (he is making a remote sync DOM so he need to force block on the main thread to wait for the result from a remote DOM env) |
| 18:47 | <devsnek> | Symbol.for('es.no.waiters') |
| 18:47 | <Bakkot> | what an excellent way to burn users' battery |
| 18:48 | <devsnek> | should use an evented model |
| 18:49 | <jridgewell> | It's really difficult to provide an sync API over an async thread |
| 18:49 | <jridgewell> | So, making it evented would just break the user's code |
| 18:50 | <jridgewell> | AMP has the same issue with WorkerDOM |
| 18:50 | <jackworks79> | yeah, in workers can use Atomics.wait to block the thread and make it fake sync |
| 18:50 | <devsnek> | make amp v2 |
| 18:51 | <mathiasbynens> | can y'all give more of a heads-up when you move agenda items around? previously it was communicated that named groups would happen before lunch |
| 18:51 | <brad4d> | I love that the "frozen" slide is constantly moving |
| 18:52 | <bradleymeck> | We also are looking at this wait behavior for instrumenting CJS in Node |
| 18:52 | <bradleymeck> | but we don't have [[CanWait]] set to false for anything |
| 18:52 | <michaelficarra> | brad4d: it's snowflakes though |
| 18:53 | <devsnek> | RIP v8 8.2 |
| 20:17 | <devsnek> | 👀 https://gc.gy/53390815.png |
| 20:17 | <devsnek> | https://gc.gy/53390839.png |
| 20:22 | <rkirsling> | agree with mathiasbynens 👍 |
| 20:24 | <rkirsling> | the whole `var y = { \u0066or: x } = { for: 42 };` is legal thing makes me cry too |
| 20:24 | <devsnek> | \u0066 in chat |
| 20:25 | <mathiasbynens> | Bakkot: you didn't mention that in non-u regexps, there's a more interesting case for /\u{FOO}/ if FOO consists of 0-9 only e.g. `123456`: then, it matches the literal character `u` repeated `123456` times. |
| 20:25 | <rkirsling> | (JSC has a ton of outstanding test262 failures about keywords-with-escapes as identifiers) |
| 20:25 | <mathiasbynens> | (#funfact but didn't want to waste committee time) |
| 20:25 | <devsnek> | non-unicode regex has a lot of scary stuff |
| 20:25 | <rbuckton> | I'd like to go on record as being opposed to allowing non-IdentifierNames in named groups, as they conflict with some RegExp related proposals I'm putting together. |
| 20:26 | <devsnek> | gibson042: can't the programs be expressed with \u{} |
| 20:26 | <littledan> | I'm not convinced that Waldemar's asciifier should be a goal... it's possible to write, but would just be slightly more complicated |
| 20:27 | <rbuckton> | (since it sounds like my question won't make it before the queue is cut off) |
| 20:27 | <littledan> | so I don't understand why the goal needs to include that the asciifier is so simple |
| 20:28 | <mathiasbynens> | I maintain such an asciifier... |
| 20:28 | <devsnek> | what is an asciifier |
| 20:28 | <akirose> | if you quit and re-join you have you re-add your full name 🤦🏻♀️ |
| 20:28 | <devsnek> | turning things outside ascii range into escapes? |
| 20:28 | <rkirsling> | akirose: yeah I can't figure out how to correct this :-/ |
| 20:29 | <shu> | mathiasbynens: waldemar's contention is that you can't convert a non-unicode regex into a unicode regex in general |
| 20:29 | <shu> | mathiasbynens: i don't know enough about regexps to say, is that actually true? |
| 20:29 | <akirose> | i had to find my own face in the gallery and choose "rename" from the context menu |
| 20:29 | <jackworks79> | I 口 Unicode |
| 20:30 | <mathiasbynens> | gibson042: can you give an example? |
| 20:31 | <mathiasbynens> | aah this is what i was missing earlier. we could totally make \u{...} work specifically for group names. i missed that gibson042 wouldn't want that |
| 20:32 | <rbuckton> | The reason `\u{1d49c}` isn't supported without the `u` flag is for back compat, however there's no back-compat concern to allow them without the `u` flag in a named capture group, as named capture groups were new syntax so there is no back-compat hazard. |
| 20:32 | <robpalme> | please really consider if you must be on the queue - we have to end this topic in 6 mins |
| 20:32 | <mathiasbynens> | rbuckton: exactly |
| 20:32 | <michaelficarra> | I don't think this is getting resolved in the next 10 minutes |
| 20:33 | <rbuckton> | The main reason *not* to allow them would be confusion due to inconsistency. |
| 20:33 | <michaelficarra> | jackworks: your pseduo-tofu bothers me so much more than real tofu |
| 20:33 | <mathiasbynens> | there's gonna be inconsistency in any case. we have to pick which inconsistency we want to live with |
| 20:33 | <devsnek> | are humans going to be confused by this though |
| 20:33 | <devsnek> | this is all tooling output |
| 20:33 | <mathiasbynens> | i think the inconsistency between pattern + match.groups.IDENTIFIER is what matters most |
| 20:34 | <rkirsling> | michaelficarra: lol I thought this too 😂 |
| 20:34 | <devsnek> | +1 to mathias |
| 20:36 | <jridgewell> | Then we could just allow any key name? |
| 20:37 | <jackworks79> | use ['for'] syntax any key name is already allowed imo 🤣 |
| 20:38 | <akirose> | 2 minute warning |
| 20:41 | <ljharb> | gibson042: isn't that what you objected to? |
| 20:41 | <gibson042> | what is the "this" here? |
| 20:42 | <rkirsling> | I get the urgency to resolve this matter but it feels really rushed given the temp of the room |
| 20:42 | <gibson042> | I think \u{…} should have identical treatment in a non-Unicode regex regardless of its use for matching vs. capture-group naming |
| 20:42 | <rwaldron> | akirose I would like to participate in "Make SharedArrayBuffer optional", but I also have to go at 5pm (hard stop, child care) |
| 20:42 | <msaboff> | We could come back to it with a longer time box, but it seems to be blocking to adopting ES 2020 |
| 20:42 | <gibson042> | i.e., equivalence with "u{…}" |
| 20:42 | <rwaldron> | If shu doesn't mind, could we do that tomorrow? |
| 20:43 | <shu> | i'm flexible for my items |
| 20:43 | <rwaldron> | shu I appreciate that |
| 20:43 | <ljharb> | gibson042: right, what kevin and waldemar were suggesting is, that `\u{1234}` would mean *that character* in both u and non-u regexes, not a literal "u{1234}", if i understand correctly |
| 20:44 | <ljharb> | gibson042: and i thought your position was, that in a non-u regex, `\u{1234}` must mean `u{1234}` |
| 20:44 | <shu> | i don't think we're talking about \u{nnn} at all...? |
| 20:44 | <rwaldron> | akirose shu the only other item that I want to participate in is "Atomics.waitAsync error rejection PR", but presumably that wont be reached until tomorrow or Thursday anyway |
| 20:44 | <gibson042> | ah, I think you have misunderstood Waldemar at least |
| 20:44 | <ljharb> | ah k |
| 20:44 | <ljharb> | i'm asking about the current slide |
| 20:44 | <shu> | aren't we talking about the surrogate pair syntax only? |
| 20:44 | <shu> | rwaldron: yeah, if at all, it's a late addition so i expect it to be at the end of the meeting |
| 20:44 | <ljharb> | shu: the question's the same tho |
| 20:44 | <msaboff> | In all of this, there is the other part of capture group names, the first "character" needs to have the Identifier_Start property and subsequent "characters" have the propert Identifier_Continue. |
| 20:44 | <shu> | ljharb: it is? |
| 20:44 | <ljharb> | in a non-u regex, `\u` means `u` |
| 20:44 | <rwaldron> | shu that's my expectation as well |
| 20:45 | <michaelficarra> | there's still a bunch of people who didn't fix their display name |
| 20:45 | <ljharb> | my understanding of gibson042's position was that that should remain true in named capture groups |
| 20:45 | <ljharb> | shu: ^ |
| 20:45 | <ljharb> | and my understanding of waldemar and kevin's preference was to make it be an actual character escape in non-u regexes (as well, ofc, as in u regexes) |
| 20:45 | <ljharb> | did i misunderstand? |
| 20:47 | <gibson042> | in order to represent in ASCII a regular expression with a non-BMP capture group name, it is necessary to allow *at least one of* `/(?<\ud835\udc9c>.)/` with surrogate-pair semantics or `/(?<\u{1d49c}>.)/` with code point semantics. I am against the latter because of inconsistency with \u{1d49c} in non-Unicode regexes outside of capture groups. |
| 20:47 | <gibson042> | and I believe that is also Waldemar's position |
| 20:47 | <ljharb> | ahhh ok |
| 20:47 | <ljharb> | so you want the non-curly surrogate pair syntax to mean "the char" but you want the curly form to be illegal (in a non-u regex)? |
| 20:47 | <gibson042> | I'm less sure about Kevin, but I think that matches as well |
| 20:47 | <devsnek> | why is ?<...> not always the ID_Identifier semantics |
| 20:48 | <devsnek> | er |
| 20:48 | <devsnek> | ID_... semantics |
| 20:48 | <ljharb> | gibson042: did my paraphrase make sense? |
| 20:48 | <devsnek> | i think i agree with shane that the thing in the arrows should always be an identifier |
| 20:49 | <rkirsling> | akirose: well put |
| 20:50 | <keith_miller> | I'm with Shane on this one I think it should just be an identifier prooduction |
| 20:50 | <keith_miller> | IIUC |
| 20:50 | <devsnek> | that would allow \u{} |
| 20:50 | <keith_miller> | correct |
| 20:51 | <devsnek> | 👍🏻 |
| 20:51 | <ljharb> | keith_miller: even in a non-unicode regex? |
| 20:51 | <devsnek> | yes |
| 20:51 | <jridgewell> | I still don't understand Waldemar's ASCIIfier |
| 20:51 | <keith_miller> | It's not observable there? |
| 20:51 | <rbuckton> | My internet connection just died, I will try to rejoin shortly. |
| 20:51 | <jridgewell> | You must be aware of the RegExp context |
| 20:51 | <msaboff> | I think that identifier production should be the same for both non-Unicode and Unicode RegExp's. |
| 20:51 | <keith_miller> | because it's not actually used in part of the regexp |
| 20:51 | <keith_miller> | ljharb:^ |
| 20:51 | <jridgewell> | Because if you naively changed the pretty a until a `\u{CODE}` in a non-unicode regex, it'd break the regex. |
| 20:52 | <keith_miller> | It's essentially a comment? |
| 20:52 | <ljharb> | keith_miller: ah ok, so the context is different for you between "the regex pattern itself" and "the annotation of the capture group" |
| 20:52 | <ljharb> | gibson042: thoughts on ^ ? |
| 20:52 | <jridgewell> | And if we allow any "name" there, why not allow _any_ name? |
| 20:52 | <devsnek> | i think shane put it nicely with the template example |
| 20:52 | <Bakkot> | jridgewell you can just change it to the pretty A into the two surrogate halves and it will work in both cases |
| 20:52 | <devsnek> | ${...} is like (<...> |
| 20:52 | <keith_miller> | ljharb: yeah |
| 20:52 | <devsnek> | er (?<...> |
| 20:53 | <Bakkot> | jridgewell the main reason not to allow any name is because it can conflict with numeric (non-named) matches, which isn't currently terrible but gets weird with some potential other features |
| 20:53 | <jridgewell> | Bringing up Waldemar's funny behavior `\u123\u456*` isn't the same as `\u{12345}*` |
| 20:53 | <msaboff> | ljharb I agree with keith_miller. Capture group names should be treated separately to the RegExp's pattern |
| 20:53 | <jridgewell> | So naive ASCIIfier is always needs to parse the regex. |
| 20:53 | <Bakkot> | shane, are you in IRC? I don't know your handle |
| 20:53 | <devsnek> | sffc: |
| 20:53 | <jridgewell> | It's just not possible to do otherwise. |
| 20:54 | <Bakkot> | jridgewell but `\u123\u456*` is the same as `A*` |
| 20:54 | <Bakkot> | in both unicode and non-unicode regexes |
| 20:54 | <Bakkot> | (I think...) |
| 20:54 | <gibson042> | I am against `/(?<\u{1d49c}>\u{1d49c})/` returning a group named "𝒜" with value "u{1d49c}", which is what the "apply code point semantics specifically when naming capture groups" implies |
| 20:54 | <jridgewell> | Be we can use the unicode codepoint anymore |
| 20:54 | <ljharb> | gibson042: ok - the thing you're against seems to be what a number of people are settling on |
| 20:54 | <devsnek> | i am okay with the example gibson042 just sent |
| 20:55 | <sffc> | hi. ok, so I understand the desire to represent regexes as strings, in which case the thing inside (?<...>) is interpreted as a string. In that situation, though, then (?<0>) should produce a capture group named with the string "0". |
| 20:55 | <Bakkot> | gibson042 there's a mandatory `>` after the group name, so you can't have that particular case |
| 20:55 | <gibson042> | having different semantics for "\u{…}" sequences based on where they appear in the regex is just too much cognitive burden for too little gain IMO |
| 20:55 | <jridgewell> | gibson042: Won't allowing the surrogate code point do exactly that? |
| 20:55 | <rkirsling> | yeah +1 to consistency about "what an identifier is" from me |
| 20:55 | <gibson042> | Bakkot: it's there |
| 20:56 | <Bakkot> | oh, sorry, I can't read |
| 20:56 | <Bakkot> | yup |
| 20:56 | <msaboff> | Bakkot Your slides said that let \ud835\udc9c; is not valid, but let \u{1d49c}; is. Shouldn't RegExp capture names be the same? |
| 20:56 | <michaelficarra> | we're talking about IdentifierNames, right? not Identifier? |
| 20:57 | <rkirsling> | separate question: has anyone ever suggested making `let \ud835\udc9c;` valid? |
| 20:57 | <devsnek> | michaelficarra: yes |
| 20:57 | <michaelficarra> | I *really* hope we wouldn't apply ReservedWord restrictions to named capture groups |
| 20:57 | <msaboff> | That is my understandng. |
| 20:57 | <michaelficarra> | rkirsling: I'm actually not sure why that's invalid |
| 20:57 | <michaelficarra> | I can't figure it out |
| 20:58 | <Bakkot> | michaelficarra because `\ud835` is not ID_Start |
| 20:58 | <michaelficarra> | remember that `let \u0065` is valid, so why wouldn't surrogate halves be valid? |
| 20:58 | <michaelficarra> | oh really, it checks the first code unit for ID_Start? |
| 20:58 | <michaelficarra> | okay then |
| 20:59 | <rkirsling> | alright that's fair |
| 20:59 | <michaelficarra> | btw where should we having the priority discussion? |
| 20:59 | <michaelficarra> | some people felt that it was unacceptable for the spec to go out with known incoherencies, but I think it's fine |
| 21:00 | <msaboff> | Bakkot If that is the case, don't we want named capture group name syntax to be the same as identifiers? |
| 21:00 | <msaboff> | I actually think that if we allow \u{}, we should also allow \u\u |
| 21:01 | <devsnek> | that would be iffy |
| 21:01 | <devsnek> | \u\u isn't disallowed btw |
| 21:01 | <devsnek> | its just that the first one isn't a valid identifier start |
| 21:01 | <sffc> | Reading the notes, I think WH's point was that anything represented in `/.../` syntax should also be able to be represented in `new RegExp("...")` syntax |
| 21:02 | <sffc> | and vice-verse |
| 21:02 | <rwaldron> | akirose shu I have to go now, but I think this proposal is ok |
| 21:02 | <rwaldron> | See you all tomorrow. |
| 21:02 | <devsnek> | 👋🏻 |
| 21:02 | <msaboff> | I haven't looked at the spec or our parser to see if a valid first surrogate \u is followed by a valid second surrogate that it is supposed to be treaded as a single Unicode code point. |
| 21:02 | <akirose> | ty rwaldron |
| 21:03 | <devsnek> | msaboff: https://tc39.es/ecma262/#sec-identifier-names-static-semantics-early-errors |
| 21:04 | <msaboff> | Thanks, looking... |
| 21:04 | <devsnek> | the first rule |
| 21:04 | <gibson042> | it's stronger than that... anything representable in `/…/` should be representable without using any code unit outside of 0x20 through 0x7E |
| 21:04 | <devsnek> | It is a Syntax Error if the SV of UnicodeEscapeSequence is none of "$", or "_", or the UTF16Encoding of a code point matched by the UnicodeIDStart lexical grammar production. |
| 21:04 | <Bakkot> | msaboff y'alls parser has a bunch of problems with non-BMP in general |
| 21:04 | <Bakkot> | doesn't even allow `let 𝒜` |
| 21:04 | <devsnek> | we'd have to modify our grammar to perform utf16 decoding on identifiers |
| 21:04 | <devsnek> | just typing that gives me shivers |
| 21:06 | <msaboff> | devsnek That says that \uHHHH is for BMP characters only. |
| 21:07 | <devsnek> | what does |
| 21:08 | <msaboff> | The spec only allows for one escape for an IdentifierStart or IndentifierPart. That is only one \uHHHH escape and not two together |
| 21:08 | <devsnek> | right |
| 21:09 | <msaboff> | If you want a non-BMP codepoint, you have to use \u{} |
| 21:09 | <devsnek> | right |
| 21:09 | <msaboff> | Given we aren't likely to change this for identifiers, I think named capture group identifiers should follow the same rules. |
| 21:10 | <msaboff> | Thins would include non-Unicode RegExps |
| 21:10 | <devsnek> | indeed |
| 21:10 | <michaelficarra> | I think we should change it for identifiers |
| 21:11 | <Bakkot> | with the effect that `/(?<\u{1d49c}>\u{1d49c})/` returns a group named "𝒜" with value "u{1d49c}", as gibson042 pointed out above? |
| 21:11 | <Bakkot> | msaboff ^ |
| 21:11 | <sffc> | Can someone explain the argument for allowing \u\u in capturing groups? |
| 21:11 | <devsnek> | sffc: that code example that bakkot just posted |
| 21:11 | <Bakkot> | devsnek sffc I will write it out; it is not that code example |
| 21:12 | <msaboff> | Bakkot Yes it would. |
| 21:12 | <devsnek> | it isn't? |
| 21:12 | <devsnek> | i thought the entire argument was that the example shouldn't be allowed |
| 21:12 | <devsnek> | so you'd have to use surrogate pairs |
| 21:12 | <Bakkot> | devsnek oh I guess that's part of it |
| 21:12 | <Bakkot> | let me write it out. |
| 21:13 | <bradleymeck> | shu: found the comment about different alloc trade offs https://freenode.logbot.info/tc39/20200219#c3271588-c3271590 that i was curious about, just a note no action |
| 21:13 | <sffc> | I don't see what Bakkot's example has to do with `(?<\u\u>)`; the question of what to do with `(?<\u{}>)` is a separate question |
| 21:14 | <devsnek> | this makes me want to buy facerig now |
| 21:14 | <Bakkot> | sffc the major argument is, currently if you are turning a JS source text into ascii you can do that for regexes by replacing any non-BMP with two escaped surrogate halves. if we disallow `\u\u`, now you have to actually parse it. and if you can't use `(?<\u{1d49c}>` in non-unicode regexs, then you can't do the thing you are trying to do at all; some people think you should not be able to use that (this is the relevance of my |
| 21:14 | <Bakkot> | previous example). |
| 21:15 | <devsnek> | how are they just replacing everything with surrogate pairs |
| 21:15 | <devsnek> | those aren't valid identifiers |
| 21:15 | <Bakkot> | "for regexes" |
| 21:15 | <shu> | bradleymeck: yeah, that's the buffer allocated if you go through Wasm.Memory |
| 21:15 | <devsnek> | ohhh just for regexes |
| 21:15 | <shu> | bradleymeck: once you get the SAB constructor back out, that follows JS rules (no rounding, page boundaries, wahtever) |
| 21:17 | <sffc> | Bakkot: so the problem is only for non-unicode regexes. But we already don't allow Unicode identifiers as capture group names in non-unicode regexes, according to the last slide in the presentation. |
| 21:17 | <Bakkot> | the current state is incoherent. |
| 21:18 | <Bakkot> | we neither allow nor disallow; I apologize that my slides suggested otherwise. |
| 21:19 | <sffc> | It makes sense if `/(?<\u{1d49c}>\u{1d49c})/` would have the behavior you suggested earlier (returns a group named "𝒜" with value "u{1d49c}"). Maybe it's a little weird, but it's well-defined. |
| 21:19 | <msaboff> | Bakkot Would you be fine with allowing \u{} in a named capture group ID for non-unicode RegExps? |
| 21:20 | <sffc> | Alternatively, it would make sense if you just forbid all non-BMP identifiers in non-unicode RegExp capture group names, in which case your example would be a compile error. |
| 21:20 | <gibson042> | you can't do that; `/(?<𝒜>.)/` is already valid |
| 21:21 | <Bakkot> | gibson042 this feature is not widely enough used for us to worry about back compat, I think |
| 21:21 | <gibson042> | ok, fair enough |
| 21:21 | <msaboff> | I think we can separate what is valid for a capture group identifier and what is match by the RegExp |
| 21:21 | <Bakkot> | msaboff I would (actually my assumed it was uncontroversial that they should be allowed); other people have said they would object to that, though. |
| 21:22 | <Bakkot> | *actually my presentation assumed |
| 21:22 | <michaelficarra> | reminder: please add your company name to your Zoom display name |
| 21:22 | <devsnek> | private fields aren't in the spec btw |
| 21:23 | <ljharb> | right, this is about adding it to the stage 3 private fields spec |
| 21:23 | <devsnek> | mhm |
| 21:23 | <msaboff> | Bakkot And then would you also support NOT allowing \uHHHH\uHHHH as a surrogate pair as a named capture group ID. It could be valid if each escape is a valid ID start / IS part. |
| 21:24 | <devsnek> | can't we just use IdentifierName |
| 21:25 | <gibson042> | people arguing for `/(?<\u{1d49c}>.)/` to be equivalent to `/(?<𝒜>.)/` while `/\u{1d49c}/` is NOT equivalent to `/𝒜/`... what's the benefit? |
| 21:25 | <jridgewell> | `foo?.bar.#baz` => `foo == null ? undefined : foo.bar.#baz` |
| 21:25 | <Bakkot> | msaboff I lean towards the other side of that question. I think approximately zero humans ever write or read code containing unicode escapes in named capture groups, so it makes sense to make things as easy as possible for tooling responsible for generating it. Allowing escaped surrogate halves here makes it easy for tooling. |
| 21:26 | <devsnek> | gibson042: that we use a consistent identifier everywhere |
| 21:26 | <mathiasbynens> | gibson042: what would Waldemar's hypothetical ASCIIfier return for the regexp-stored-as-string '[<U+0000>-<U+10FFFF>]', with the condition that it doesn't know whether the target RegExp will have the u flag or not? |
| 21:26 | <msaboff> | I get that, but does it make sense to have different grammar rules for identifiers in the language versus named capture group identifiers? |
| 21:26 | <mathiasbynens> | gibson042: if you know you end up in a `u` regexp, you can output `/\0-\u{10FFFF}/u` and call it a day, but that pattern wouldn't work in non-`u` |
| 21:26 | <Bakkot> | mathiasbynens you can replace those with the two surrogate halves and it will preserve semantics in both cases, I am almost certain. |
| 21:27 | <mathiasbynens> | Bakkot: well no you'd break the range in the non-u case |
| 21:27 | <Bakkot> | how sure are you? |
| 21:27 | <mathiasbynens> | Bakkot: 100% |
| 21:27 | <mathiasbynens> | Bakkot: since you're now creating a range between U+0000 and highSurrogate(U+10FFFF) |
| 21:28 | <msaboff> | Bakkot I don't think so. In mathiasbynens example, the RegExp is quite different with and without /u |
| 21:28 | <Bakkot> | mathiasbynens "since you're now creating"... in the non-u case? |
| 21:28 | <mathiasbynens> | and then trailSurrogate(U+10FFFF) is a lone character in the character class... |
| 21:28 | <Bakkot> | are you sure that's not what you already had? |
| 21:28 | <Bakkot> | I think that's what you already had |
| 21:28 | <mathiasbynens> | Bakkot: it isn't, is what i'm saying |
| 21:29 | <ljharb> | gus's point here is really good. |
| 21:30 | <devsnek> | :D |
| 21:30 | jridgewell | reverts PR to original state |
| 21:30 | <devsnek> | lol |
| 21:30 | <rkirsling> | 👏 |
| 21:31 | <Bakkot> | mathiasbynens I am pretty sure that's what you already had, at least in real engines |
| 21:31 | <Bakkot> | `/^[𝒜]$/.test('\ud835')` is "true" |
| 21:32 | <devsnek> | i think bmeck suggested we should set up specifying optional chaining and member expressions using some sort of macro syntax |
| 21:32 | <mathiasbynens> | Bakkot: I'm not talking about engines? |
| 21:32 | <devsnek> | i'd be in favor of doing such a thing |
| 21:32 | <Bakkot> | mathiasbynens I think also per spec, sorry |
| 21:32 | <sffc> | I think the main question for me is how `...` in `(?<...>)` is interpreted. If it's an identifier, then `\u\u` should be disallowed. If it's a string, then `0` should be allowed. |
| 21:32 | <mathiasbynens> | Bakkot: I'm talking about neither of those things :/ |
| 21:32 | <Bakkot> | mathiasbynens sorry, I am confused then |
| 21:32 | <msaboff> | Bakkot If mathiasbynens range was written with the last codepoint in the range as two \u escapes, do you agree with what he says the range becomes? |
| 21:33 | <rkirsling> | lol, "@jridgewell pushed 0 commits." |
| 21:33 | <Bakkot> | msaboff yes, my point is that it was already that thing to start with, I'm pretty sure |
| 21:33 | <mathiasbynens> | Bakkot: waldemar described an asciifier that takes a regexp-stored-as-string and turns it into an actual piece of sourcetext representing a regexp literal, WITHOUT knowing whether that literal will get a `u` flag or not |
| 21:33 | <msaboff> | With the /u flag it is completely different. |
| 21:33 | <Bakkot> | mathiasbynens yes? |
| 21:33 | <shu> | the consensus to the optional chaining for hash names was allow everywhere, right? |
| 21:34 | <Bakkot> | msaboff it only becomes that thing in non-unicode regexes |
| 21:34 | <shu> | (i'm confused by the second sentence in the consensus in the notes) |
| 21:34 | <devsnek> | shu: yes |
| 21:34 | <jridgewell> | I think I pushed -2 commits. |
| 21:34 | <Bakkot> | in unicode regexes, it is still the single range |
| 21:34 | <msaboff> | I think we agree |
| 21:34 | <Bakkot> | let me write out the four cases here |
| 21:34 | <mathiasbynens> | Bakkot: that's my point. the asciifier already needs to either a) know whether or not it gets the u flag or b) go out of its way to produce polyglot patterns that work properly in either case |
| 21:35 | <Bakkot> | mathiasbynens can it not just unconditionally put the two surrogate halves? |
| 21:35 | <Bakkot> | that is what I am having trouble with. |
| 21:35 | <Bakkot> | if not, why not? |
| 21:35 | <Bakkot> | what case does that break, and why does it break it? |
| 21:35 | <sffc> | So is waldemar's point that both `/(?<𝒜>/` and `/(?<𝒜>/u` asciify to the same thing? |
| 21:35 | <msaboff> | I think that an asciifier must know if the u flag is present. |
| 21:35 | <sffc> | (I'm missing a `)` in those examples) |
| 21:36 | <mathiasbynens> | that would behave differently with u vs non-u |
| 21:36 | <rkirsling> | yeah, are we really saying that there's currently ALWAYS a way to write a regexp-as-string without knowing whether it's unicode? |
| 21:36 | <Bakkot> | mathiasbynens _what_ would behave differently with `u` vs non-`u`? |
| 21:36 | <rkirsling> | like, why would that invariant ever exist? |
| 21:36 | <mathiasbynens> | Bakkot: another example: `'[💩-💫]'` |
| 21:36 | <mathiasbynens> | Bakkot: what would you output that works in both `u` and non-`u`? |
| 21:37 | <Bakkot> | that's never a legal non-u regex, so you don't have to worry about it |
| 21:37 | <mathiasbynens> | Bakkot: you're changing the goalposts though, the asciifier needs to produce output that's valid for either, since it doesn't know! |
| 21:37 | <mathiasbynens> | https://mathiasbynens.be/notes/es6-unicode-regex is full of examples |
| 21:38 | <msaboff> | I think we are heading into the weeds here. Lets focus on the named capture group IDs. |
| 21:38 | <gibson042> | yes, please |
| 21:38 | <Bakkot> | mathiasbynens outputting '[\uXXX\uXXX-\uXXX\uXXX]' will preserve the semantics: in the non-u case it is (still) an error, and in the u case it is (still) a single range |
| 21:38 | <Bakkot> | so your asciifier has preserved the semantics |
| 21:38 | <Bakkot> | which is what it needed to do |
| 21:38 | <Bakkot> | (sorry, four Xs, obviously) |
| 21:39 | <sffc> | When you're not in a named capture group, your asciifyer can output `\u\u`. I think that's fine. |
| 21:39 | <ljharb> | littledan: github has a "template" feature; you don't need to fork it, you *should* click the "use this template" button |
| 21:39 | <msaboff> | Thee is the interesting case of a RegExp with a NCG ID with non-BMP characters, but I don't think that is too controversial |
| 21:39 | <mathiasbynens> | the whole asciifier argument doesn't make sense. it's possible to produce patterns that work in either case, but it needs some work. capture group IDs would not be unique |
| 21:39 | <ljharb> | littledan: as opposed to making a totally disconnected repo |
| 21:39 | <Bakkot> | mathiasbynens... what? |
| 21:40 | <littledan> | ljharb: Oh cool. Could we point people to this? |
| 21:40 | <ljharb> | littledan: it's a big green button on the template repo |
| 21:40 | <gibson042> | repeating myself: in order to represent in ASCII a regular expression with a non-BMP capture group name, it is necessary to allow *at least one of* `/(?<\ud835\udc9c>.)/` with surrogate-pair semantics or `/(?<\u{1d49c}>.)/` with code point semantics. I am against the latter because of inconsistency with \u{1d49c} in non-Unicode regexes outside of capture groups. |
| 21:40 | <ljharb> | littledan: https://github.com/tc39/template-for-proposals |
| 21:40 | <littledan> | heh yeah that's really clear |
| 21:40 | <littledan> | sorry |
| 21:40 | <Bakkot> | mathiasbynens I am confused. my point is, currently you can write a regex asciifier which preserves semantics easily. if you have to parse it and treat named capture groups and non-named-capture groups, it is now harder. do you disagree with either of those two sentences? if so, which and why? |
| 21:41 | <ljharb> | littledan: np, the feature didn't exist when i first made the template |
| 21:41 | <littledan> | hmm, should we tell people to use that button in the #create-your-proposal-repo section? |
| 21:41 | <ljharb> | ideally, but i wasn't sure the committee had consensus on recommending that template yet |
| 21:41 | <Bakkot> | gibson042 other people are in favor of allowing `/(?<\u{1d49c}>.)/`, it sounds like, and damn the inconsistency (which seems fair enough to me; no human will ever write that code so the inconsistency isn't really a problem) |
| 21:41 | <sffc> | gibson042: I don't care about the inconsistency you mention. I find it more inconsistent that we are introducing a context in which we allow surrogate pairs as identifier names. |
| 21:42 | <mathiasbynens> | Bakkot: "easily"? you got the `<U+0>-<U+10FFFF>` wrong |
| 21:42 | <msaboff> | gibson042 The problem is that \ud835\udc9c is not valid for a JS identifier but \u{1d49c} is. |
| 21:42 | <sffc> | So I'm +1 to "damn the inconsistency" |
| 21:42 | <Bakkot> | mathiasbynens I still do not understand how I got it wrong. |
| 21:42 | <mathiasbynens> | Bakkot: what would you output? |
| 21:42 | <Bakkot> | mathiasbynens please give an example of a regex where the output of my algorithm does not have the same semantics as the input. |
| 21:42 | <msaboff> | So you want different syntax for specifying an ID inthe two contexts |
| 21:43 | <Bakkot> | mathiasbynens '[\uXXXX\uXXXX-\uXXXX\uXXXX]' |
| 21:43 | <mathiasbynens> | Bakkot: what would \uXXXX\uXXXX look like for U+0000 exactly? |
| 21:43 | <Bakkot> | mathiasbynens sorry, yes, for BMP code points it would just be `\uXXXX`, of course |
| 21:43 | <Bakkot> | so, `\u0000` |
| 21:44 | <mathiasbynens> | that's not a working regexp :/ |
| 21:44 | <mathiasbynens> | "where the output of my algorithm does not have the same semantics as the input" is key |
| 21:44 | <Bakkot> | mathiasbynens _neither was the input_ |
| 21:44 | <Bakkot> | so the semantics are preserved |
| 21:44 | <mathiasbynens> | Waldemar is saying his asciifier doesn't know which output flags are used |
| 21:44 | <Bakkot> | or, wait, hang on |
| 21:45 | <Bakkot> | wait why isn't it a working regex |
| 21:45 | <mathiasbynens> | the input _is_ valid |
| 21:45 | <Bakkot> | I keep getting confused between this and the '[💩-💫]' case |
| 21:45 | <Bakkot> | mathiasbynens why isn't it a working regex |
| 21:45 | <sffc> | Do we have agreement on allowing `/(?<\u{1d49c}>\u{1d49c})/` with the inconsistency about `\u{1d49c}` being interpreted differently in the capture group versus the main regex? |
| 21:45 | <robpalme> | back in 10 mins! |
| 21:45 | <Bakkot> | sffc gibson042 explicitly objected to that |
| 21:46 | <gibson042> | as did Waldemar, and probably more strongly than me if we're being honest |
| 21:46 | <msaboff> | sffc I'm fine with that |
| 21:46 | <rkirsling> | that's a pretty strong point of contention among the committee then :( |
| 21:46 | <mathiasbynens> | Bakkot: so you'd do something like [\0-\uLEAD\uTRAIL], which creates a range between U+0000 and U+LEAD, and then adds U+TRAIL as a lone character |
| 21:46 | <Bakkot> | mathiasbynens right, which is what your input regex did. |
| 21:47 | <mathiasbynens> | Bakkot: no, the input is a string, which represents a regex, per Waldemar's description |
| 21:47 | <sffc> | The alternative from my perspective is if we allow `/(?<0>.)/` and interpret "0" as a string, such that you can do `.groups["0"]` |
| 21:47 | <Bakkot> | or rather: right, that's what it does in the non-u case, which is what the input regex did in the non-u case. in the u case it creates a single range, which is what the input regex did in the u case. |
| 21:47 | <mathiasbynens> | Bakkot: you cannot say that's what the input did, because you cannot know this without knowing whether it's `u` vs non-`u` |
| 21:47 | <mathiasbynens> | which this supposed asciifier doesn't |
| 21:48 | <mathiasbynens> | so you cannot produce a broken pattern, you have to make something that works |
| 21:48 | <Bakkot> | mathiasbynens the job of the asciifier is to preserve the semantics. that is it's only job. if the input was going to be used with `u`, the semantics are preserved. if the input was going to be used without `u`, the semantics are preserved. so the semantics are preserved either way. |
| 21:49 | <Bakkot> | do you disagree about the job of the asciifier, or do you disagree that in both branches the semantics are the same? |
| 21:49 | <msaboff> | What would an asciifier do with |
| 21:49 | <msaboff> | let s = "[\0-<U+10fff>]"; |
| 21:49 | <msaboff> | r = new RegExp(s, "u") |
| 21:49 | <mathiasbynens> | ^ |
| 21:49 | <msaboff> | Where the <U+10FFFF> is the actual character |
| 21:49 | <Bakkot> | msaboff `let s = [\u0000-\uTRAIL\uLEAD]"` |
| 21:50 | <Bakkot> | r then has the same semantics |
| 21:50 | <mathiasbynens> | it does not lol |
| 21:50 | <sffc> | Can someone address my question about whether the capture group is a string, an identifier, or something special? My understanding is that if we go with what gibson042 and waldemar prefer, then we're introducing a new context where surrogate pairs are allowed as identifiers, but other strings are not. |
| 21:51 | <msaboff> | sffc: it (should be) an identifier |
| 21:51 | <mathiasbynens> | Bakkot: oh you meant a leading quote there |
| 21:51 | <gibson042> | mathiasbynens: Bakkot's point is that for both Unicode and non-Unicode regular expressions, `[\0-\ud835\udc9c]` is equivalent to `[\0-𝒜]` so that contextual awareness is irrelevant |
| 21:52 | <Bakkot> | mathiasbynens yes, leading quote, of course |
| 21:52 | <Bakkot> | yeah what gibson042 said |
| 21:52 | <mathiasbynens> | ok the disconnect is, i've been thinking of an asciifier that's like a JS function that accepts a string |
| 21:53 | <mathiasbynens> | whereas you see it as a tool operating on the source code |
| 21:53 | <sffc> | gibson042: if the capture group name is an identifier, then how do you justify the inconsistency of allowing `\u\u` in this context but not in a `let \u\u` context? |
| 21:54 | <gibson042> | I'd prefer it in both, but would justify the inconsistency by pointing out that this is an encoding inside a literal |
| 21:54 | <mathiasbynens> | if that's what you're doing, you could just transform any such group names globally, right? |
| 21:54 | <mathiasbynens> | much like variable name minification |
| 21:54 | <mathiasbynens> | but not without changing potentially observable semantics, sure |
| 21:55 | <gibson042> | and the prohibition against non-IdentifierNames could in principle be relaxed without changing my position |
| 21:55 | <sffc> | gibson042: ok, so we agree that we have an inconsistency with both outcomes. |
| 21:55 | <keith_miller> | to be fair even the asciifier would have observable semantics :P |
| 21:55 | <mathiasbynens> | keith_miller: right... |
| 21:55 | <msaboff> | The rule in https://tc39.es/ecma262/#prod-RegExpIdentifierName resolves to RegExpIdentifierStart folowed by RegExpIdentifierPart, but they have the same productions as IdentifierStart and IdentifierPart |
| 21:55 | <jridgewell> | `/[\0-\ud835\udc9c]/u` is not equivalent to `/[\0-𝒜]/u` |
| 21:55 | <keith_miller> | changes |
| 21:56 | <keith_miller> | because you changed the length of the file |
| 21:56 | <mathiasbynens> | and .source and .toString() etc. |
| 21:56 | <Bakkot> | jridgewell how sure of that claim are you |
| 21:56 | <gibson042> | sffc: it's an inconsistency of the same sort that allows `\n` but not raw U+000A in string literals |
| 21:56 | <jridgewell> | I just tested in Chrome |
| 21:56 | <Bakkot> | jridgewell what test did you run? |
| 21:56 | <gibson042> | jridgewell: for what input do you get different results? |
| 21:56 | <ljharb> | keith_miller: that's not really observable in JS tho |
| 21:56 | <jridgewell> | Nope, never mind, I forgot to change it. |
| 21:57 | <jridgewell> | I hit up twice. 😳 |
| 21:57 | <keith_miller> | I meant function length |
| 21:57 | <keith_miller> | ljharb:^ |
| 21:57 | <keith_miller> | sorry |
| 21:58 | <sffc> | gibson042 What is the behavior of `/(?<\ud835\udc9c>.)/` in your preference? Does it throw? |
| 21:58 | <mathiasbynens> | ljharb: function tostring, and source + toString on the regexp too |
| 21:58 | <gibson042> | sffc: no, it is equivalent to `/(?<𝒜>.)/` |
| 21:58 | <ljharb> | keith_miller: ah true |
| 21:59 | <ljharb> | mathiasbynens: also true |
| 21:59 | <gibson042> | it is how you express non-BMP capture group names without using non-ASCII source |
| 21:59 | <sffc> | gibson042: right, so you consider `/(?<𝒜>.)/` a valid regex that produces a group name of "𝒜"? |
| 21:59 | <Bakkot> | mathiasbynens what did you mean by "transform any such group names globally"? |
| 21:59 | <gibson042> | just like `/(\ud835\udc9c/` is how you express non-BMP matches without using non-ASCII source |
| 22:00 | <gibson042> | yes |
| 22:00 | <gibson042> | err, just like `/\ud835\udc9c/` is how you express non-BMP matches without using non-ASCII source |
| 22:01 | <sffc> | Bakkot: what do you think about allowing non-IdentifierNames in the regex capture group name, as gibson042 suggested would be compatible with his position? |
| 22:01 | <mathiasbynens> | Bakkot: like if the tool sees a group named `𝒜` it could rename that to `__renamed_1` and give `match.groups.𝒜` the same treatment |
| 22:01 | <Bakkot> | mathiasbynens sure, but `x = match.groups; x.𝒜` is harder |
| 22:02 | <mathiasbynens> | Bakkot: yeah |
| 22:02 | <Bakkot> | and by "harder" I mean "uncomputable" |
| 22:02 | <msaboff> | I think we are letting this asciifier argument have too much sway. Do we think this is a major use case? |
| 22:02 | <Bakkot> | sffc I would not want to allow capture group names which, when considered as code points, are not identifiers |
| 22:03 | <Bakkot> | msaboff in honesty I think it's pretty much the only use case. |
| 22:03 | <Bakkot> | msaboff that is, I don't think a human is ever going to write unicode escape sequences in group names. it's always going to be tools. |
| 22:03 | <Bakkot> | so, my preference is to make life easy for tools. |
| 22:04 | <michaelficarra> | so just allow \u{} everywhere |
| 22:04 | <michaelficarra> | if that's your only goal |
| 22:04 | <mathiasbynens> | michaelficarra: we can't do that in non-u regexps OUTSIDE of named groups, but within named groups yesssssssssssssss I'm all for it |
| 22:04 | <msaboff> | I don't know how prevalent of a use case it is, but I believe that humans WILL write unicode escapes for group names. Not common but likely given the use of poor dev tools. |
| 22:05 | <Bakkot> | msaboff it's pretty common; I have seen multiple bespoke JS-asciification tools in use at enterprises (all broken to some extent, but we don't need to make them more broken) |
| 22:05 | <msaboff> | michaelficarra I'm for it in NCG IDs as well. |
| 22:05 | <Bakkot> | michaelficarra as mathiasbynens says, you can't do it outside of group names. so now the tools have to parse the regex, instead of blindingly replacing everything in the regex. |
| 22:05 | <devsnek> | is there not just a babel plugin |
| 22:06 | <sffc> | Bakkot: can you explain why you would not want to allow non-identifiers in capture group names? |
| 22:06 | <gibson042> | so sffc and maybe mathiasbynens are against allowing `/(?<\ud835\udc9c>.)/` because of IdentifierName, and Waldmar and I are against allowing `/(?<\u{1d49c}>.)/` because of non-/u regexp semantics |
| 22:06 | <devsnek> | actually doesn't babel shell out to a regex parser |
| 22:06 | <gibson042> | but at least one of them must be allowed in order to support all-ASCII source |
| 22:06 | <sffc> | gibson042: that's my understanding of the situation, yes |
| 22:06 | <mathiasbynens> | I just want (or would like) to be able to copy-paste 𝒜𝒜𝒜 in `/(?<𝒜𝒜𝒜>.)/` and the corresponding `match.groups.𝒜𝒜𝒜` |
| 22:06 | <mathiasbynens> | in all cases |
| 22:07 | <msaboff> | Bakkot What would an asciifier do for the "let \u{1d49c};" case? |
| 22:07 | <gibson042> | that's already ASCII, so it would leave it alone |
| 22:08 | <Bakkot> | sffc: two reasons: one is that having `>` gets weird, and the other is that having numerics like `0` gets weird |
| 22:08 | <msaboff> | Okay, then what does an asciifier do for "let 𝒜;"? Won't it also convert it to "let \u{1d49c};"? |
| 22:08 | <msaboff> | If so, it can't do that without context. |
| 22:08 | <michaelficarra> | Bakkot mathiasbynens: sorry yes that's what I meant by "everwhere"; "regardless of u flag, inside NCGs" |
| 22:08 | <gibson042> | yes, it would have to |
| 22:09 | <msaboff> | So the only weird context is in the pattern part of a RegExp? |
| 22:09 | <gibson042> | unless we allow surrogate pairs wherever \u{…} is allowed, an asciifier must parse |
| 22:09 | <Bakkot> | must tokenize |
| 22:09 | <Bakkot> | doesn't have to do a full parse |
| 22:09 | <msaboff> | gibson042 I think that is a breaking change for nomral identifiers. |
| 22:09 | <Bakkot> | (except as necesary for tokenization) |
| 22:10 | <devsnek> | is there any possible (?< in regex that isn't a group name |
| 22:10 | <gibson042> | Bakkot: +1 |
| 22:10 | <Bakkot> | devsnek: `\(?<` |
| 22:10 | <devsnek> | ok excluding escapes |
| 22:10 | <Bakkot> | '[(?<]' |
| 22:10 | <msaboff> | I don't think so besides the escape. |
| 22:11 | <devsnek> | Bakkot: wouldn't that require a parse |
| 22:11 | <devsnek> | not just tokenize |
| 22:11 | <devsnek> | to know you're inside a capture group |
| 22:11 | <devsnek> | er |
| 22:11 | <devsnek> | character set |
| 22:12 | <devsnek> | whatever you call brackets |
| 22:12 | <mathiasbynens> | character class |
| 22:12 | <mathiasbynens> | hmm interesting |
| 22:13 | <Bakkot> | devsnek why? |
| 22:13 | <msaboff> | What should an asciifier do with: |
| 22:13 | <msaboff> | let first = "\0"; |
| 22:13 | <msaboff> | let last = "𝒜"; |
| 22:14 | <devsnek> | cuz you have to know whether you're parsing a group name or not |
| 22:14 | <devsnek> | theoretically |
| 22:14 | <msaboff> | let r = new RegExp("[" + first + "-" + last + "]") |
| 22:14 | <Bakkot> | devsnek: my desired state is, we end up such that you can replace any non-bmp in any regex (or string) with two escaped surrogates |
| 22:14 | <Bakkot> | msaboff you can also safely replace non-BMP code points in strings with two escaped surrogate halves |
| 22:15 | <devsnek> | i mean if we went with "whatever identifiers do" |
| 22:15 | <Bakkot> | devsnek oh, yes. that's my point; that's what I am hoping to avoid. |
| 22:15 | <gibson042> | it's also worth noting that `let \u0061\u0061` *is* valid, but `let \ud835\udc9c` is not simply because code unit U+D835 is not treated as part of a surrogate pair |
| 22:15 | <gibson042> | Bakkot: I agree |
| 22:16 | <msaboff> | That doesn't work for let r = new RegExp("(?<" + last + ">.)"); |
| 22:16 | <Bakkot> | msaboff how does it not? |
| 22:17 | <sffc> | If the asciifyer isn't able to have different behavior based on whether you are in a capture group or whether you are in a Unicode vs non-Unicode regex, then you need to expand to `\u\u`. Are those two restrictions required for the asciifyer? |
| 22:17 | <mathiasbynens> | let last = '\uD835\uDC9C'; // which is === '𝒜' |
| 22:17 | <msaboff> | I doubt that the two surrogate escapes are ID_Start and ID_Continue |
| 22:17 | <gibson042> | exactly |
| 22:17 | <mathiasbynens> | there won't be any escapes by the time you put it into the RegExp at runtime |
| 22:19 | <Bakkot> | sffc in practice, most asciifiers I see in the wild are bespoke and at least a little bit broken because they are not aware of all the absurd edge cases in JS. I am hopeful we can minimize new sharp edges. |
| 22:19 | <gibson042> | if `let \ud835\udc9c` were interpreted analogously to `"\ud835\udc9c"`, with the two escapes recognized as a single code point, then an asciifier could always replace non-ASCII code points with \u…\u… surrogate pairs |
| 22:19 | <sffc> | gibson042: non-Unicode regexes already have strange behavior when you embed Unicode characters. We're making the behavior no less strange. |
| 22:20 | <mathiasbynens> | in general, it seems bad to expose the concept of surrogates in more places |
| 22:20 | <gibson042> | we're not talking about changing the semantics of non-Unicode regexes with non-ASCII characters |
| 22:20 | <sffc> | +1 mathiasbynens |
| 22:20 | <gibson042> | I actually disagree with that, but it's a bit of a tangent anyway |
| 22:20 | <Bakkot> | sffc we are making the behavior harder for tools to get right, and no harder for humans to get right |
| 22:21 | <sffc> | gibson042: asciifyers aside, what should `/(?<\u{1d49c}>.)/` do in your opinion? |
| 22:23 | <gibson042> | it should be recognized as equivalent to `/(?<u{1d49c}>.)/`, i.e. an attempt to create a regex with a capture group named "u{1d49c}" |
| 22:23 | <Bakkot> | oof |
| 22:23 | <Bakkot> | I do not like that option |
| 22:23 | <gibson042> | which is currently invalid because group names must be IdentifierNames |
| 22:24 | <gibson042> | just like `/\u{1d49c}/` matches only "u{1d49c}" |
| 22:24 | <mathiasbynens> | named captures should have been `u`-only |
| 22:24 | <gibson042> | IOW, "\u{" has no special semantics in non-Unicode regular expressions |
| 22:25 | <Bakkot> | so the effective answer is, it should be an error, right? |
| 22:25 | <gibson042> | yes |
| 22:25 | <Bakkot> | ok good that's not so bad then |
| 22:26 | <devsnek> | mathias +1 |
| 22:26 | <gibson042> | and the spec machinery would be essentially "UTF16Decode, then require the result to conform with IdentifierName" |
| 22:27 | <devsnek> | i'd rather push proper unicode escapes into old regex than push old escapes into identifiers |
| 22:27 | <gibson042> | but you *can't* push them all the way in |
| 22:28 | <mathiasbynens> | devsnek: would be amazing if that was web compatible :o |
| 22:28 | <michaelficarra> | devsnek: they already exist in identifiers, they're just arguably handled wrong |
| 22:28 | <devsnek> | i meant in the group name |
| 22:28 | <devsnek> | not generally |
| 22:28 | <michaelficarra> | oh :-( |
| 22:28 | <devsnek> | lol |
| 22:28 | <mathiasbynens> | devsnek: ah yes, 100% agree |
| 22:28 | <devsnek> | tfw you confuse three people all at once |
| 22:28 | <michaelficarra> | in different ways |
| 22:29 | <keith_miller> | shu: Out of curiosity how did this API come up? |
| 22:29 | <keith_miller> | Was it from talking to graphics peoples? |
| 22:30 | <mathiasbynens> | gibson042: sorry for being a broken record, but why is that inconsistency (of \u{...} being allowed in named groups, but not elsewhere, in non-u regexps) too much for you? |
| 22:30 | <rkirsling> | ^ and is this an objection and not just a dispreference? |
| 22:31 | <mathiasbynens> | gibson042: i don't understand how that apparently outweighs the `/(?<𝒜𝒜𝒜>.)/u` && `match.groups.𝒜𝒜𝒜` consistency, which seems much more common |
| 22:31 | <Bakkot> | mathiasbynens: wait, what inconsistency |
| 22:32 | <Bakkot> | has anyone suggested `/(?<𝒜𝒜𝒜>.)/u` && `match.groups.𝒜𝒜𝒜` not work? |
| 22:32 | <mathiasbynens> | no |
| 22:32 | <mathiasbynens> | in plenary when it was suggested that we could make \u{...} work in group names within non-u RegExps |
| 22:32 | <Bakkot> | ah |
| 22:33 | <Bakkot> | (I am fine with that fwiw) |
| 22:33 | <Bakkot> | mathiasbynens: also, same question for you: why is the inconsistency of `\u\u` being allowed in named group names, but not in identifiers outside of literals, too much for you? |
| 22:33 | <mathiasbynens> | gibson042 said that'd be inconsistent with \u{} elsewhere in non-u RegExps (which is true) |
| 22:34 | <mathiasbynens> | Bakkot: the way i see it, we have to choose between the two, and so we should choose based on which pattern is more common |
| 22:34 | <gibson042> | It's too much because it adds *even more* complexity to an already overwhelming part of the language, and does so for very little benefit IMO. This is a strong dispreference, but I (though not necessarily Waldemar) would yield to supermajority. |
| 22:34 | <Bakkot> | mathiasbynens: why do you see it that we have to choose between the two? |
| 22:35 | <Bakkot> | mathiasbynens: my preference is to allow both (in both kind of regexes), as we do in strings and `u` regexs |
| 22:35 | <gibson042> | sffc and maybe mathiasbynens are against allowing `/(?<\ud835\udc9c>.)/` because of IdentifierName, and Waldmar and I are against allowing `/(?<\u{1d49c}>.)/` because of non-Unicode regexp semantics... but at least one of them must be allowed in order to support all-ASCII source |
| 22:35 | <Bakkot> | this makes life easiest for tooling authors and creates in expectation zero problems for any other humans, I would guess |
| 22:36 | <mathiasbynens> | what gibson said ^ |
| 22:36 | <Bakkot> | ugh |
| 22:36 | <mathiasbynens> | did i get that wrong? |
| 22:36 | <Bakkot> | yeah I think that's correct |
| 22:36 | <Bakkot> | I would like us to think first about what the actual effects of our decisions on future humans will be |
| 22:36 | <mathiasbynens> | and i agree on "zero problems for humans" |
| 22:36 | <mathiasbynens> | i just don't like to make the language uglier by allowing surrogates in more places |
| 22:37 | <Bakkot> | I appreciate that preference, I just think it should be outweighed by the relatively substantial likelihood that this decision leads to someone shipping broken code to real users as a result of tooling which is not aware of this edge case |
| 22:37 | <mathiasbynens> | i would hope (perhaps naively) that future humans always use the `u` flag |
| 22:37 | <Bakkot> | some will, many won't |
| 22:37 | <gibson042> | isn't it worse to have `\ud835\udc9c` sometimes be two code points and sometimes one? |
| 22:39 | <shu> | keith_miller: oh, no, not from the graphics folks |
| 22:39 | <mathiasbynens> | gibson042: hmm? |
| 22:39 | <keith_miller> | Interesting, where did it come up? |
| 22:40 | <gibson042> | regarding "i just don't like to make the language uglier by allowing surrogates in more places", I think it's worse to have more places where `\ud835\udc9c` represents two code points rather than one |
| 22:41 | <ljharb> | benjamn: wait, import.meta inherits from Module.prototype in node?? |
| 22:41 | <ljharb> | benjamn: or, you might want it to |
| 22:41 | <shu> | keith_miller: surma brought it up in working with bitmaps pulling out the A's instead of the RGB's, i think is the direct motivating example |
| 22:41 | <keith_miller> | got it |
| 22:41 | <benjamn> | ljharb: no, but Module.prototype was a useful feature of CommonJS |
| 22:41 | <Bakkot> | gibson042: if it's forbidden it doesn't really represent anything |
| 22:41 | <shu> | keith_miller: and indeed, the plan for RGBs was to make 3 views for each channel |
| 22:42 | <gibson042> | because `/(?<\u0061\u0061>.)/` is valid now and will presumably remain valid |
| 22:42 | <mathiasbynens> | gibson042: i don't follow. how does allowing \{...} in non-u RegExp group names increase the number of cases where `\ud835\udc9c` represents 2 code points? |
| 22:42 | <shu> | keith_miller: there's a category mismatch for me for the graphics use cases needing more expressivity -- simple strides exist in other languages and enjoy use, despite lacking the extra expressivity |
| 22:43 | <Bakkot> | gibson042: that is neither valid nor invalid now (per spec), and could be made invalid without breaking anyone (I suspect) |
| 22:43 | <shu> | keith_miller: so maybe the high-order bit here is actually how much implementation burden is there, given that this is intended to be a smallish, incremental ergonomic win |
| 22:44 | <mathiasbynens> | Bakkot: hm, that would be another deviation from Identifier though |
| 22:44 | <gibson042> | right. So rejecting `/(?<\ud835\udc9c>.)/` can only be on the basis of treating it as two code points |
| 22:44 | <shu> | keith_miller: that is, i'm pushing back against the framing that satisfying all graphics use cases is a pre-req |
| 22:45 | <Bakkot> | mathiasbynens \ud835\udc9c is not legal in identifiers, is it? |
| 22:45 | <gibson042> | which it is not in the same regex outside of naming a group |
| 22:45 | <mathiasbynens> | Bakkot: no |
| 22:45 | <Bakkot> | mathiasbynens wait which "no" |
| 22:45 | <Bakkot> | "no, it is not legal" or "no, you're mistaken, it is legal" |
| 22:45 | <mathiasbynens> | Bakkot: escaped surrogate pairs in identifiers == not valid |
| 22:45 | <gibson042> | `\ud835\udc9c` is not a valid IdentifierName because it is interpreted as two code units, neither of which are in a valid class |
| 22:46 | <wsdferdksl> | You can already access a non-BMP property using foo["\ud835\udc9c"]. |
| 22:46 | <keith_miller> | shu: I'd roughly agree with that assessment but I phrase it as the cost is roughly known/fixed but there may be enough use cases to justify it |
| 22:46 | <mathiasbynens> | (it's v late and i've been v difficult here, apologies and cheers for bearing with me so far) |
| 22:46 | <gibson042> | err, two code *points* |
| 22:46 | <shu> | keith_miller: yeah, point taken |
| 22:46 | <gibson042> | if it were interpreted as a surrogate pair for a single code point, then it would be a valid identifier |
| 22:46 | <wsdferdksl> | RegExes should work like strings |
| 22:46 | <keith_miller> | I'm not trying to say you have to solve all use cases only that there are still a lot of use cases that are not very ergonomic anyway |
| 22:47 | <gibson042> | which is what happens inside strings and inside regular expression literals outside of naming capture groups |
| 22:47 | <keith_miller> | with this api* |
| 22:47 | <shu> | keith_miller: right, so it comes down to how big is the set of use cases that would be made ergonomic, and how much work do we have to do for it |
| 22:47 | <msaboff> | I just checked and the current spec only allows unicode escapes in NGC Identifiers for Unicode. And it allows both \uXXXX\uXXXX and \u{XXXXX} for NCG identifiers. |
| 22:47 | <keith_miller> | yeah |
| 22:47 | <keith_miller> | I think we're on the same page |
| 22:47 | <shu> | keith_miller: which are both pretty valid; all the use cases on the explainer now are graphics, and if graphics folks are like "lol no" then that's just bad motivation. if we can't find better ones then yeah, just do it in user code |
| 22:48 | <mathiasbynens> | wsdferdksl: regexes have different concepts of what constitutes a "character" depending on the `u` flag, so strings/regexps don't map nicely |
| 22:48 | <Bakkot> | msaboff: the current spec has an early error for "the SV of RegExpUnicodeEscapeSequence", which is not an operation which is defined |
| 22:48 | <wsdferdksl> | I'm talking about non-u regexes |
| 22:48 | <mathiasbynens> | msaboff: sorry, what is NCG? |
| 22:48 | <Bakkot> | named capture group |
| 22:48 | <mathiasbynens> | ah duh |
| 22:49 | <wsdferdksl> | Both those and strings work with 16-bit chunks |
| 22:49 | <msaboff> | Named Capture Group |
| 22:49 | <gibson042> | regexes of both kinds recognize surrogate pairs as single code points outside of naming capture groups |
| 22:49 | <wsdferdksl> | No |
| 22:49 | <mathiasbynens> | no, look at atoms |
| 22:49 | <Bakkot> | character classes too |
| 22:49 | <msaboff> | gibson042 in practice pretty much in reality no |
| 22:49 | <mathiasbynens> | gibson042: e.g. \uLEAD\TRAIL{2} |
| 22:50 | <mathiasbynens> | https://mathiasbynens.be/notes/es6-unicode-regex has some examples |
| 22:51 | <gibson042> | this is veering into semantics now; non-Unicode regexes operate on UTF-16 code units |
| 22:52 | <keith_miller> | lol |
| 22:52 | <Bakkot> | wsdferdksl mathiasbynens gibson042: I don't think we're likely to resolve this today. are you all OK with the committee approving the current spec, including this oversight, as the candidate for 2020, and trying to resolve this later? |
| 22:52 | <wsdferdksl> | No |
| 22:52 | <wsdferdksl> | We should resolve this |
| 22:52 | <gibson042> | I am, since it's not new anyway |
| 22:52 | <mathiasbynens> | Bakkot: I see no rush tbh. I'd rather resolve it properly |
| 22:53 | <Bakkot> | wsdferdksl: given that we don't appear to be close to consensus, how can we resolve it? |
| 22:53 | <Bakkot> | I guess we could call a formal vote for this question |
| 22:53 | <wsdferdksl> | There is only one solution that works for ASCIIfiers, and it's not difficult to do. |
| 22:53 | <mathiasbynens> | let's keep the spec as-is until we can get proper consensus (which doesn't have to be in this meeting imho) |
| 22:53 | <msaboff> | Bakkot: Is the "SV value of RegExpUnicodeEscapeSequence" confusing in the context of a Unicode RegExp? |
| 22:53 | <mathiasbynens> | wsdferdksl: there are two solutions: we could make \u{...} work in NCG in non-u regexps |
| 22:53 | <Bakkot> | msaboff It's not defined at all, yes |
| 22:54 | <Bakkot> | that's why this issue comes up |
| 22:54 | <wsdferdksl> | I don't see why we don't have consensus. It's not like people are going to be writing this kind of stuff. |
| 22:54 | <Bakkot> | well, we don't |
| 22:54 | <wsdferdksl> | Why not? |
| 22:54 | <Bakkot> | people feel strongly about consistency with identifiers, mostly |
| 22:55 | <wsdferdksl> | How is that relevant? |
| 22:55 | <wsdferdksl> | It's not like people are going to be writing this kind of stuff. |
| 22:55 | <michaelficarra> | wsdferdksl: is this your first meeting? |
| 22:55 | <mathiasbynens> | wsdferdksl: why don't we make \u{...} work _only_ in NCG in non-u regexps? that way we don't expose the unfortunate concept of surrogates to more places in the language |
| 22:56 | <gibson042> | "it adds *even more* complexity to an already overwhelming part of the language, and does so for very little benefit IMO" |
| 22:56 | <wsdferdksl> | That would be gratuitously confusing. Once again, it's not like folks are going to be writing this stuff by hand. |
| 22:56 | <gibson042> | I'm stepping out for a bit, be back later |
| 22:57 | <mathiasbynens> | gibson042: can't you say the same thing about allowing individually-escaped paired surrogates in groups? |
| 22:58 | <mathiasbynens> | i'm heading off, should've gone to bed hours ago. thanks for bearing with me y'all. and Bakkot, I really appreciate your work on trying to fix this spec bug, one way or another -- thanks! |
| 22:58 | <Bakkot> | mathiasbynens thanks for engaging; sleep well |
| 23:00 | <msaboff> | Bakkot How do you reconcile that with "SV of UnicodeEscapeSequence"? The only difference compared to RegExpUnicodeEscapeSequence is that RegExpUnicodeEscapeSequence includes \uXXXX\uXXXX. |
| 23:01 | <bradleymeck> | xs uses freeze |
| 23:01 | <sffc> | Regexes are confusing. This is an edge case. My preference is to make `/(?<\u{1d49c}>.)/ == /(?<𝒜>.)/`. I think it's more important to have consistency with language syntax than consistency in behavior. If someone is surprised by the behavior, we have a reason for it. |
| 23:01 | <Bakkot> | msaboff: "SV" is an operation which is not defined for RegExpUnicodeEscapeSequence |
| 23:02 | <Bakkot> | but it is defined for UnicodeEscapeSequence |
| 23:02 | <Bakkot> | wsdferdksl: to be concrete, of the following four regular expressions literals, which do you think ought to be legal? /(?<\ud835\udc9c.)/ /(?<\u{1d49c}>.)/ /(?<\ud835\udc9c.)/u /(?<\u{1d49c}>.)/u |
| 23:03 | <robpalme> | 4 min break! |
| 23:03 | <devsnek> | btw https://arai-a.github.io/ecma262-compare |
| 23:03 | <wsdferdksl> | Bakkot: 0, 2, and 3. |
| 23:03 | <msaboff> | Bakkot Maybe the fastest path to victory is defining "SV of RegExpUnicodeEscapeSequence" |
| 23:04 | <wsdferdksl> | The rationale being that's those three out of the four are "legal" if you don't enclose the escapes inside (?<>). |
| 23:04 | <Bakkot> | msaboff: yeah, but there's normative implications and we have to get people to agree on the normative behavior |
| 23:04 | <devsnek> | ljharb: bradleymeck: https://nodejs.org/api/vm.html#vm_constructor_new_vm_sourcetextmodule_code_options |
| 23:04 | <devsnek> | i just remembered this is a thing |
| 23:05 | <bradleymeck> | non-stage 4 features, in my runtime :gasp: |
| 23:05 | <devsnek> | we can deprecate it |
| 23:05 | <devsnek> | actually we don't even need to do that |
| 23:05 | <devsnek> | its still experimental |
| 23:05 | <Bakkot> | wsdferdksl: would you be OK with /(?<\u{1d49c}>.)/ being legal? I would prefer it to be legal just for simplicity of tooling, personally |
| 23:05 | <msaboff> | Bakkot: do you think that any implementation is doing something different than the obvious? |
| 23:05 | <Bakkot> | msaboff yup |
| 23:06 | <Bakkot> | both you and chrome are |
| 23:06 | <wsdferdksl> | It's a bit more complex, but I wouldn't object to that, if the other three were also legal. |
| 23:06 | <msaboff> | Let me look at your slides again... |
| 23:06 | <Bakkot> | msaboff in particular, the "obvious" thing would not depend on the presence of the `u` flag, but JSC and V8 both do |
| 23:07 | <robpalme> | ok break time is over! |
| 23:07 | <wsdferdksl> | It wouldn't simplify the tooling because you can't use \u{} outside of (?<>) |
| 23:08 | <Bakkot> | wsdferdksl it depends on the tooling. I could imagine tooling which parses regexes and re-serializes them, and being able to use the same serialization logic for group names for both `u` and non-`u` regexs is slightly simpler. |
| 23:08 | <Bakkot> | but yes it's a very small win |
| 23:09 | <msaboff> | But the spec requires the u flag to get to the RegExpUnicodeEscapeSequence production. I think we comply in light of the u flag. Not that a patch landed last night in JSC that deals with this. |
| 23:09 | <benjamn> | does anyone know the rationale for using the m suffix for decimals? (as in .2m) |
| 23:09 | <devsnek> | as opposed to? |
| 23:09 | <benjamn> | haha, yes, it seems pretty arbitrary |
| 23:09 | <Bakkot> | msaboff the spec does not require the flag, in my reading? |
| 23:09 | <benjamn> | .2d? |
| 23:10 | <wsdferdksl> | 0x34d |
| 23:10 | <devsnek> | f means float, i means imaginary, etc |
| 23:10 | <benjamn> | oh sure, probably shouldn't be a-f |
| 23:10 | <benjamn> | why does m mean decimal though? |
| 23:10 | <devsnek> | that i don't know |
| 23:10 | <benjamn> | is it like two n's, smushed together? |
| 23:10 | <benjamn> | like a fraction? |
| 23:10 | <Bakkot> | deciMal |
| 23:10 | <shu> | you can't spell decimal without m |
| 23:10 | <rkirsling> | https://github.com/tc39/proposal-decimal/#why-are-literals-m-why-not-d |
| 23:10 | <benjamn> | shu: true that |
| 23:11 | <rbuckton> | _M_oney |
| 23:11 | <devsnek> | lol |
| 23:11 | <shu> | oooo |
| 23:11 | <devsnek> | that's how the twitter teachers will teach it 100% |
| 23:12 | <msaboff> | https://tc39.es/ecma262/#prod-RegExpUnicodeEscapeSequence has the U suffix and all rules that evaluate to it require U to be true. |
| 23:12 | <benjamn> | yes! I love the idea of #{ numerator, denominator } |
| 23:13 | <Bakkot> | msaboff the `[U]` suffix means it's a parameter, not a requirement |
| 23:13 | <msaboff> | The +U means it must be true |
| 23:13 | <devsnek> | benjamn: in a decimal type n/d is just that |
| 23:13 | <rbuckton> | Rationale for C#'s use of `m` (tldr; it was the next best letter in `decimal`): https://stackoverflow.com/a/977562 |
| 23:14 | <Bakkot> | msaboff which +U? |
| 23:14 | <rkirsling> | definitely better `m` than `i` or `l` |
| 23:14 | <sffc> | suggestion for decimal: `#{ mantissa, scale }` where mantissa is a BigInt |
| 23:14 | <devsnek> | what is scale |
| 23:14 | <benjamn> | devsnek: oh yes, I'm not suggesting that tuples would automatically serve all the decimal use cases |
| 23:14 | <sffc> | scale is a power of 10 |
| 23:14 | <devsnek> | oh exponent ok |
| 23:14 | <sffc> | `#{ 123n, -2 }` is 1.23 |
| 23:15 | <msaboff> | Every RHS rule for https://tc39.es/ecma262/#prod-RegExpUnicodeEscapeSequence |
| 23:15 | <devsnek> | 1.23m is 1.23 |
| 23:15 | <Bakkot> | msaboff: `[~U] u Hex4Digits` |
| 23:15 | <Bakkot> | so not every RHS rule |
| 23:16 | <msaboff> | That is not valid for NCG Identifiers. |
| 23:16 | <Bakkot> | How not? |
| 23:16 | <Bakkot> | GroupName is `GroupName[U] :: < RegExpIdentifierName[?U] >` |
| 23:17 | <Bakkot> | and then `RegExpIdentifierName[U] :: RegExpIdentifierStart[?U]` -> `RegExpIdentifierStart[U] :: \RegExpUnicodeEscapeSequence[?U]` |
| 23:18 | <msaboff> | In your mind, how does the character value definition for RegExpUnicodeEscapeSequence in https://tc39.es/ecma262/#sec-patterns-static-semantics-character-value answer the SV question? |
| 23:19 | <benjamn> | rbuckton: oh wow, I did not expect "the [first good] letter in decimal" to be such a persuasive argument |
| 23:19 | <Bakkot> | https://tc39.es/ecma262/#sec-patterns-static-semantics-character-value gives semantics for CharacterValue for every RHS that RegExpUnicodeEscapeSequence produces |
| 23:19 | <benjamn> | but d, e, c, and i are all quite problematic… so yeah |
| 23:20 | <msaboff> | Only the \uHexDIgits is valid to NCG ids in non-u RegExps |
| 23:20 | <michaelficarra> | sffc: that sounds a lot like a reduced form of Rationals |
| 23:20 | <rbuckton> | in C#: `d`-double,`e`-exponent, `c`-char, `i`-integer, `l`-long. Only other option would have been `a` |
| 23:21 | <msaboff> | Therefore we (currently) can't have a non-BMP character in a NCG id for non-u RegExps. Agree? |
| 23:21 | <rbuckton> | I'm currently pursuing a struct/value-type proposal with syntax for operator overloading. |
| 23:22 | <msaboff> | And we (currently) can have non-BMP codepoints in NCG ids for u flagged RegExps. |
| 23:22 | <devsnek> | can we get a tc39-regex channel |
| 23:22 | <devsnek> | (/s) |
| 23:22 | <msaboff> | So your slide #10 is conforming. |
| 23:22 | <Bakkot> | msaboff we can have a non-BMP character in a NCG id as two `\uHex4Digits`. or rather, the spec does not say whether or not we can ahve that. |
| 23:25 | <msaboff> | The way I read the spec is we must interpret two `\uHex4Digits` as two individual codepoints for non-unicode RegExp NGC ids. The must each be appropriate ID characters depending on their position. |
| 23:25 | <msaboff> | They might be dangling surrogates, but that would be a syntax error as they wouldn't be ID codepoints. |
| 23:26 | <michaelficarra> | msaboff: that's how I originally expected non-u regexps to work |
| 23:26 | <Bakkot> | The "must each be appropriate ID characters depending on their position" bit is the part where the current specification does not provide an answer. |
| 23:26 | <Bakkot> | but, yes, that would be the smallest delta from the current specification (and is what my current PR does) |
| 23:27 | <msaboff> | First position IDStart and following codepoints IDContinue |
| 23:27 | <rbuckton> | I think we need an official "stage 1" proposal repo to investigate operator overloading in all of its various forms, and as a single place to collect the various requirements and concerns. |
| 23:27 | <devsnek> | https://github.com/tc39/proposal-operator-overloading |
| 23:28 | <drousso> | ^ thanks :) |
| 23:28 | <devsnek> | i'm really not a fan of that proposal though |
| 23:28 | <msaboff> | Bakkot I think the current spec DOES provide the answer for the non u flag NCG id case. |
| 23:28 | <rbuckton> | devsnek: yes and no. That proposal is currently very specific to the constructor-based overloading approach. I've already expressed concern over this approach from a static analysis/tooling perspective. |
| 23:29 | <devsnek> | if js had operator overloading i'd want it to be all dynamic and whatnot |
| 23:29 | <ljharb> | at stage 1, proposals are about solving problems |
| 23:29 | <Bakkot> | msaboff: it doesn't tell you what "SV of UnicodeEscapeSequence" is, so you can't tell if it satisfies "the UTF16Encoding of a code point matched by the UnicodeIDStart lexical grammar production" |
| 23:29 | <msaboff> | I may disagree with what is says and be sympathetic to what you want, but that is different than how I read the current spec. |
| 23:30 | <msaboff> | What does the end of section https://tc39.es/ecma262/#sec-static-semantics-sv say to you about "SV of UnicodeEscapeSequence |
| 23:31 | <Bakkot> | msaboff: sorry, my previous message should read "it doesn't tell you what the SV of RegExpUnicodeEscapeSequence is" |
| 23:31 | <Bakkot> | msaboff: the relevant rule is "Early Errors: RegExpIdentifierStart[U]::\RegExpUnicodeEscapeSequence[?U] It is a Syntax Error if the SV of RegExpUnicodeEscapeSequence is none of "$", or "_", or the UTF16Encoding of a code point matched by the UnicodeIDStart lexical grammar production." |
| 23:31 | <ystartsev> | It feels like we are being pulled off topic a bit |
| 23:31 | <ystartsev> | (comment regarding discussion in the video) |
| 23:33 | <devsnek> | mfw 1n is not equal to 1 |
| 23:33 | <shu> | did someone remove my queue item? |
| 23:33 | <devsnek> | why do they have relational equality but not absolute equality |
| 23:34 | <Bakkot> | devsnek: `===` does not do type coercion |
| 23:34 | <msaboff> | Bakkot: Back to what I said earlier, I think that is what the end of https://tc39.es/ecma262/#sec-patterns-static-semantics-character-value describes. (Even though it talks about the CharacterValue, which is a String with one code point.) |
| 23:34 | <devsnek> | Bakkot: i'm not saying type coercion is needed |
| 23:34 | <Bakkot> | msaboff: that defines CharacterValue, not SV |
| 23:35 | <devsnek> | 1n and 1 both exactly represent the mathematical value 1 |
| 23:35 | <Bakkot> | my point is that "SV of RegExpUnicodeEscapeSequence" is not defined |
| 23:35 | <Bakkot> | yes, the smallest delta would be to use CharacterValue instead; that's what my current PR does |
| 23:35 | <Bakkot> | but it does not, currently, use CharacterValue instead |
| 23:36 | <msaboff> | IMHO, SV is the obvious string with a single CharacterValue. |
| 23:36 | <msaboff> | If we added such a rule, would that be suficient? |
| 23:37 | <Bakkot> | Yes, the problem is that the absence of semantics here means that such a decision would be normative |
| 23:37 | <Bakkot> | which is why I brought it to committee |
| 23:37 | <Bakkot> | and then people had opinions about which semantics to choose |
| 23:39 | <Bakkot> | msaboff: although, that said, that decision would mean it was impossible to render `/(?<𝒜>.)/` as ascii |
| 23:39 | <msaboff> | Make your PR "the SV of RegExpUnicodeEscapeSequence is the one character string of the CharacterValue of RegExpUnicodeEscapeSequence." and make it normative. |
| 23:39 | <Bakkot> | which also does seem legitimately bad |
| 23:40 | <msaboff> | That is a separate change to the RegExp section. |
| 23:40 | <keith_miller> | akirose: Can we post the meeting agenda for June? I meant to put https://github.com/tc39/ecma262/pull/1912 on the agenda but I thought PRs were automatic... I don't want to forget about it lol |
| 23:40 | <ljharb> | keith_miller: i'll do that |
| 23:41 | <keith_miller> | great thanks! |
| 23:41 | <msaboff> | Bakkot You need to change how RegExpIdentifierStart and RegExpIdentifierPart are defined |
| 23:41 | <Bakkot> | yeah |
| 23:41 | <Bakkot> | I am reasonably sure I can spec any possible semantics here if we can agree on the semantics |
| 23:41 | <Bakkot> | I just want os to agree on one thing |
| 23:42 | <robpalme> | we may finish at 17:09 if this runs for the full 30 minute slot |
| 23:43 | <devsnek> | 🎉 |
| 23:44 | <ystartsev> | ljharb: i may be interested in helping |
| 23:44 | <rkirsling> | how exciting |
| 23:45 | <devsnek> | i may be interested in commenting on the github issues |
| 23:46 | <benjamn> | am I correct in assuming `a ??= b ??= c` would mean `a ?? (a = (b ?? (b = c)))`? |
| 23:46 | <rkirsling> | devsnek: I might be interested in the complement of that |
| 23:46 | <devsnek> | that's how you open the js portal |
| 23:47 | <rkirsling> | benjamn: yep looks right |
| 23:47 | <rkirsling> | (just without the double-evaluations) |
| 23:47 | <benjamn> | rkirsling: ahh good point |
| 23:47 | <ystartsev> | i think it would be `a = a ?? b ?? c` ? |
| 23:47 | <devsnek> | no |
| 23:47 | <devsnek> | assignment chains return the most right-hand side |
| 23:48 | <devsnek> | s/return/use/ |
| 23:48 | <ystartsev> | ah ok |
| 23:48 | <devsnek> | `let _v = c; b ??= _v; a ??= _v;` |
| 23:48 | <jridgewell> | benjamn: I believe you are correct |
| 23:49 | <benjamn> | devsnek: is there a way to avoid evaluating c in that, if a or b is already defined? |
| 23:49 | <jridgewell> | https://babeljs.io/repl/#?browsers=&build=&builtIns=false&spec=false&loose=false&code_lz=IYAg_GC8IEblIDGQ&debug=false&forceAllTransforms=false&shippedProposals=false&circleciRepo=&evaluate=false&fileSize=false&timeTravel=false&sourceType=module&lineWrap=true&presets=stage-1&prettier=false&targets=&version=7.9.0&externalPlugins= |
| 23:50 | <jridgewell> | I don't believe `b` is set if `a` short-circuits |
| 23:50 | <devsnek> | benjamn: oh you're right it doesn |
| 23:50 | <devsnek> | doesn't evaluate the right hand side |
| 23:50 | <jridgewell> | Yah |
| 23:50 | <devsnek> | i forgot about that |
| 23:50 | <bradleymeck> | time pressure isn't good |
| 23:51 | <benjamn> | jridgewell: that reduces to |
| 23:51 | <benjamn> | (sorry premature send) |
| 23:52 | <jridgewell> | `a != null ? a : a = b != null ? _b : b = c;` |
| 23:53 | <benjamn> | yes |
| 23:53 | <jridgewell> | (s/_b/b/) |
| 23:53 | <benjamn> | if null there means nullish (including undefined) |
| 23:53 | <jridgewell> | Yes |
| 23:53 | <ljharb> | ystartsev: awesome, thanks! i'll post an issue shortly and tag you |
| 23:53 | <ystartsev> | ljharb: great thanks |
| 23:54 | <devsnek> | https://engine262.js.org/#gist=b972418f6ec2e52a7c9c711eda60a446 |
| 23:55 | <benjamn> | devsnek: cool that's what I would hope |
| 23:55 | <benjamn> | chained logical assignment seems entirely… logical |
| 23:55 | <ljharb> | keith_miller: june agenda is pushed, feel free to commit directly to it |
| 23:55 | <devsnek> | except when the assignment target is const /s |
| 23:55 | <rkirsling> | oh shit that didn't get brought up did it |
| 23:56 | <rkirsling> | or did I just look away and miss it? |
| 23:56 | <devsnek> | i don't remember it happening |
| 23:56 | <ljharb> | rkirsling: it didn't, no |
| 23:56 | <rkirsling> | 😬 |
| 23:56 | <rkirsling> | like |
| 23:56 | <rkirsling> | I don't expect it to change consensus |
| 23:56 | <rkirsling> | but it deserves public mention |
| 23:57 | <rkirsling> | I should've thought to bring it up myself |
| 23:57 | <drousso> | ...oops |
| 23:57 | <drousso> | yeah same |
| 23:57 | <littledan> | if we don't ship a spec, the latest spec will still have the bug |
| 23:57 | <ljharb> | littledan: put that on the queue |
| 23:57 | <rkirsling> | ^ |
| 23:57 | <devsnek> | ^ |
| 23:58 | <littledan> | eh I'm fine just leaving it here; the day's almost over |
{kind=link}
{kind=link}
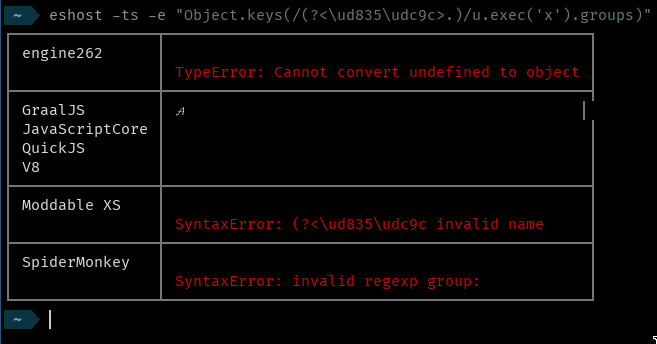{kind=link}
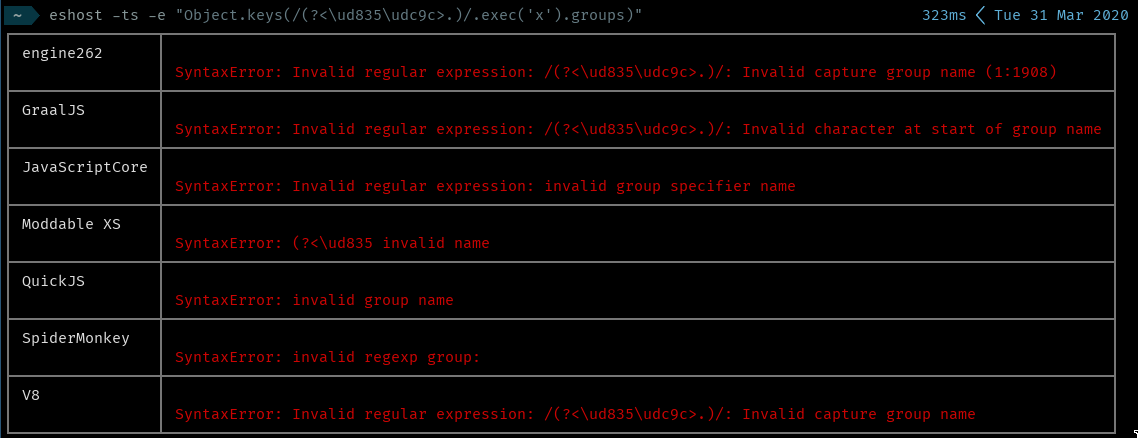{kind=link}