| 00:00 | <bewest> | best way to combat spam is to never crawl it to begin with |
| 04:46 | Hixie | sends his reply to the 76 e-mails in his "INBOX.input-for-whatwg-box-of-sand" folder |
| 04:47 | <Hixie> | annevk: i got a bounce to your mail address: |
| 04:47 | <Hixie> | <fora⊙an>: mail for annevankesteren.nl loops back to myself |
| 04:51 | <Hixie> | ok, what's next.? |
| 04:51 | <Hixie> | <datatemplate>, <font>, class=? |
| 04:52 | <Lachy> | what's <datatemplate>? |
| 04:52 | <Hixie> | an idea hyatt and i came up with this afternoon |
| 04:53 | <othermaciej> | my personal requests would be DOMTokenList.toggle() and defining behavior for NaN and +/- Inf for canvas methods that take floats |
| 04:53 | <Hixie> | so class="" then <canvas> |
| 04:53 | <Hixie> | Lachy: basically, xul templates for html, as a replacement for wf2 repetition blocks |
| 04:53 | <othermaciej> | actually any refinements/cleanups to <canvas> would be great for WebKit currently |
| 04:54 | <Hixie> | k i'll look at <canvas> next then |
| 04:55 | <Lachy> | Hixie, Thunderbird thinks your "Sandboxing ideas" email is a scam! :-) (because it contains a URL with an IP address) |
| 04:55 | <Hixie> | hh |
| 04:55 | <Hixie> | hah even |
| 04:55 | <Hixie> | wait, it does? |
| 04:55 | <Hixie> | which one? |
| 04:55 | <Lachy> | <http://209.85.129.104/custom?q=cache:0s8ftW8HviQJ:en.wikipedia.org/wiki/Web_Hypertext_Application_Technology_Working_Group>; |
| 04:56 | <Hixie> | oh |
| 04:56 | <othermaciej> | predefined classes have been a point of controversy |
| 04:57 | <Lachy> | yeah, using an _ prefix will resolve the comlaints about clashing |
| 04:57 | <Hixie> | a _ prefix looks dumb |
| 04:57 | <Hixie> | i'm tempted to yank the whole idea |
| 04:57 | <othermaciej> | Hixie: I have a different idea for a sandboxing model but it requires a parsing hack of some sort for HTML (but not XML) |
| 04:57 | <Lachy> | fair enough |
| 04:58 | <Hixie> | othermaciej: oh? |
| 04:58 | <Hixie> | othermaciej: so long as you clearly define the problem you're solving first... |
| 04:58 | <Hixie> | othermaciej: 90% of the proposals were "i have this idea for sandboxing" without even saying what they were trying to solve |
| 04:58 | <othermaciej> | Hixie: I know what problem I'm trying to solve |
| 04:58 | <othermaciej> | I should probably write it up in email |
| 04:59 | <Hixie> | i mean, fixing things without knowing what you're trying to solve is bad enough, but doing that when the issue is a security issue is just stupid |
| 04:59 | Hixie | grumbles |
| 04:59 | <Hixie> | othermaciej: cool |
| 04:59 | <Hixie> | othermaciej: be sure to read the stuff i wrote at the bottom of the mail |
| 04:59 | <othermaciej> | the problem is allowing sites to embed user-generated content and preventing script, without relying on their checks for script or plugins or the like exactly matching what the UA does |
| 04:59 | <Hixie> | othermaciej: i listed a bunch of things i considered |
| 04:59 | <othermaciej> | yeah, gonna read it first |
| 04:59 | <Hixie> | as well as the attack vectors they fail |
| 05:01 | <othermaciej> | my idea would not remove the need for server-side processing for legacy UAs, but it would allow better security in UAs that implement the feature without breaking legacy UAs |
| 05:03 | <Hixie> | oh look, only 143 e-mails pending for <canvas> |
| 05:03 | <othermaciej> | hmm actually I think your MD5 idea may be more workable than you think |
| 05:04 | <othermaciej> | (although MD5 would not be the best choice of hash) |
| 05:04 | <Hixie> | yeah i just used md5 cos it was easy for me to generate the hashes |
| 05:05 | <othermaciej> | you compute hash incrementally while parsing, and stop at the first instance of </sandbox> where the hash so far matches the open tag |
| 05:05 | <othermaciej> | so there's no DOS attack |
| 05:05 | <Hixie> | that's doomed |
| 05:06 | <Hixie> | you just need to find ONE case where foo</sandbox> has the same hash as foo |
| 05:06 | <othermaciej> | I don't think a brute force attack is feasible, since you need not just an arbitrary collision, but self-prefix collision |
| 05:06 | <Hixie> | er, what i just wrote isn't quite right |
| 05:06 | <Hixie> | but yes |
| 05:07 | <othermaciej> | no, you need one where foo</sandbox>attack-payload has the same hash as foo |
| 05:07 | <Hixie> | the point is, you can generate these up the wazoo |
| 05:07 | <Hixie> | right |
| 05:07 | <Hixie> | it's not like your collision has to be a tough one to find |
| 05:07 | <othermaciej> | I don't think anyone knows how to generate a hash collision for even MD5, meeting those constraints |
| 05:07 | <Hixie> | you need foo</sandbox>bar-baz to collide with foo</sandbox>, where both "foo" and "baz" can be completely controlled |
| 05:08 | <othermaciej> | where foo and foo + FIXED-SUFFIX collide |
| 05:08 | <othermaciej> | actually you need it to collide with just "foo" |
| 05:08 | <Hixie> | er right |
| 05:08 | <othermaciej> | hmm |
| 05:08 | <Hixie> | so "foo" has to collide with "foo"+x+"bar" where foo and bar are arbitrary |
| 05:09 | <Hixie> | and you only ever need to find ONE collision for EVERYONE to be compromised |
| 05:09 | <othermaciej> | I'll have to do the math to see if it's computationally feasible even for a relatively strong hash like SHA-256 or SHA-512 |
| 05:09 | <othermaciej> | having both client and server checks is still likely stronger than only a server check |
| 05:09 | <othermaciej> | since then you have to compromise both |
| 05:09 | <Hixie> | when you do that, bear in mind there are upwards of 100,000,000 machines at the disposal of the bad guys to do the work to find the collision |
| 05:09 | <othermaciej> | that would require your hash to also pass server-side sniffing |
| 05:10 | <Hixie> | you know that in due course people will rely on the UAs |
| 05:10 | <Hixie> | wow, a lot of these <canvas> comments are about painting text to the canvas |
| 05:13 | <othermaciej> | so given your estimate of 2^30 machines, to break SHA-512 you'd still need each machine to generate and compute the hash of on average 2^482 random payloads |
| 05:13 | <Hixie> | how do you figure? |
| 05:14 | <othermaciej> | because there are 2^512 different possible SHA-512 hash values |
| 05:14 | <othermaciej> | and there's no known way to generate a collision faster than brute force |
| 05:14 | <othermaciej> | (let alone a collision with chosen plaintext embedded) |
| 05:14 | <othermaciej> | if each compromised machine could generate and hash one message per plack time... |
| 05:14 | <Hixie> | you're not looking for one hash value |
| 05:15 | <othermaciej> | it would take 2^438 seconds to break |
| 05:15 | <Hixie> | you're doing a birthday paradox attack here |
| 05:15 | <Hixie> | it'll be way lower than that |
| 05:15 | <othermaciej> | it's not the case that any hash will do, you need a known plaintext embedded |
| 05:16 | <othermaciej> | you can't use a random collision pair to generate a collision pair with your attack vector embedded |
| 05:16 | <othermaciej> | where one of the pair is a prefix of the other |
| 05:17 | <Hixie> | still seems dodgy to me |
| 05:17 | <othermaciej> | but let's assume a birthday attack will do, arguendo |
| 05:18 | <othermaciej> | birthday attack for N outputs requires 1.2 * sqrt(N) steps on average |
| 05:18 | <othermaciej> | I don't believe a birthday attack is efficiently parallelizable |
| 05:20 | <Hixie> | it's a simple map-reduce, where the map is to generate the hashes given arbitrary input prefixes and suffixes, and the reduce is looking for pairs |
| 05:20 | <othermaciej> | but that would be 2^256 time units, over 2^30 machines generating one per planck time, 2^182 seconds |
| 05:20 | <Hixie> | fair enough |
| 05:21 | <othermaciej> | approximately 10^54 sec |
| 05:21 | <Hixie> | that's a long time |
| 05:21 | <othermaciej> | age of the universe is about 10^17 seconds |
| 05:22 | <Hixie> | fair enough |
| 05:22 | <othermaciej> | I believe you'd need more machines than atoms in the universe, each testing one possibility per planck time, to do it in under the age of the universe |
| 05:22 | <Hixie> | so the question becomes, is calculating the hash one byte or character at a time a perf hit? |
| 05:22 | <othermaciej> | no, I'm wrong, one machine per atom in the galaxy might do it |
| 05:25 | <othermaciej> | one byte at a time might be, but you only need to do the computation when you hit </sandbox>, otherwise you can feed it to the hasher one block at a time (for whatever its block size is) |
| 05:25 | Hixie | finds a problem with SHA-512 |
| 05:25 | <Hixie> | this is what the markup would look like to embed nothing: |
| 05:25 | <Hixie> | <sandbox hash=cf83e135 7eefb8bd f1542850 d66d8007 d620e405 0b5715dc 83f4a921 d36ce9ce 47d0d13c 5d85f2b0 ff8318d2 877eec2f 63b931bd 47417a81 a538327a f927da3e"></sandbox> |
| 05:25 | <Hixie> | that's long. |
| 05:26 | <Hixie> | ah yes, very true |
| 05:27 | <othermaciej> | sha-512 block size is 1024 bits, so 128 characters |
| 05:27 | <othermaciej> | you could fit </sandbox> 12 times in a block if you wanted to maximally hurt parsing speed |
| 05:27 | <othermaciej> | it would probably be something of a speed hit |
| 05:27 | <Hixie> | if you want to DOS there are plenty of ways to do it |
| 05:28 | <Hixie> | that's not really the concern |
| 05:29 | <othermaciej> | using a digital signature might be more effective w/ a smaller hash, since that increases the requirements on the hash, but then the feature would require a public/private keypair to use |
| 05:29 | <othermaciej> | *increases the requirements on the collision |
| 05:33 | <jruderman> | i think it would be saner for sites to switch to tag+attribute whitelists |
| 05:33 | <Hixie> | tag+attribute+value whitelists |
| 05:34 | <deltab> | what if the contained HTML is modified in transit? for instance, PHP adding session IDs to links, or a proxy automatically adding links or translating? |
| 05:34 | <othermaciej> | it doe seem like whitelists obviate the need for this, though you need to in that case parse and re-serialize the content |
| 05:34 | <othermaciej> | *does |
| 05:34 | <Hixie> | deltab: then everything from the <sandbox> to the end of the page gets hidden |
| 05:34 | <jruderman> | othermaciej: yeah |
| 05:35 | <jruderman> | what is <sandbox> supposed to mean? if it's just "no scripts" it leaves spoofing with abs pos open |
| 05:35 | <othermaciej> | now how can we convince myspace to switch to parse-whitelist-reserialize? |
| 05:36 | <jruderman> | othermaciej: by boycotting them |
| 05:36 | <Hixie> | hah |
| 05:36 | <Hixie> | good luck with that |
| 05:36 | <Hixie> | the people you need to have boycott them are the most impressionable and least security-conscious part of society |
| 05:36 | othermaciej | considers the unique challenges of writing a security treatise for 13-year-olds |
| 05:36 | <jruderman> | we'll start by having geeks boycott them |
| 05:37 | <jruderman> | (i'm joking) |
| 05:40 | <Hixie> | so the problems i see with <sandbox> are that the markup becomes really ugly looking (long hash), the page becomes extremely brittle (even minor changes to the markup can cause the entire rest of the page to become unusable), and that, if it just kills scripts, it doesn't solve a whole bunch of problems like phishing (with forms and css), embedding things like flash which have their own scripting problems, and linking to pages that themselves aren't sandboxes (e.g |
| 05:41 | <othermaciej> | it would have to restrict CSS, form controls, and plugins |
| 05:41 | <othermaciej> | which would possibly make it less than useful |
| 05:42 | <othermaciej> | the iframe solution could get away with not restricting CSS or plugins but does have the ugly markup problem |
| 05:42 | <Hixie> | yeah |
| 05:43 | <Hixie> | maybe we need a way of taking the <iframe>'s contents and putting them in the iframe |
| 05:43 | <Hixie> | <iframe sandbox><p>Hello!</iframe> |
| 05:43 | <Hixie> | (then the contents can't contain the string "</iframe") |
| 05:44 | <othermaciej> | yeah that has the same early close issue |
| 05:45 | <othermaciej> | so btw the idea I had for <sandbox> would not be vulnerable to creating an offline hash collision |
| 05:45 | <othermaciej> | it basically comes down to having a funky close tag syntax |
| 05:45 | <Hixie> | <sandbox tag="ntehoi"> </sandbox tag="ntehoi"> ? |
| 05:45 | <othermaciej> | <sandbox tag="long-random-string-generated-each-time-by-server"> ... </sandbox tag="long-random-string-generated-each-time-by-server"> |
| 05:45 | <othermaciej> | yeah |
| 05:45 | <Hixie> | i considered that. figured people wouldn't like that kind of screwing with the parser. i guess i didn't end up putting it in the mail. |
| 05:45 | <othermaciej> | I believe this would fall back as desired in legacy UAs |
| 05:46 | <Hixie> | yeah |
| 05:46 | <Hixie> | in terms of the parsing |
| 05:47 | Hixie | notes this is the second conversation i've had today with apple employees where they have suggested the parser be hacked to support new stuff :-P |
| 05:47 | <Hixie> | you guys should hear what the other vendors say when i suggest parser changes |
| 05:47 | <Hixie> | sheesh |
| 05:48 | <othermaciej> | what was the other one? |
| 05:48 | <othermaciej> | I guess their parsers are even scarier than ours |
| 05:48 | <Hixie> | hyatt was suggesting a new parse mode for the <datatemplate> idea |
| 05:48 | <Hixie> | probably will take that idea |
| 05:49 | <Hixie> | once i've dealt with the 83 e-mails about <canvas> that aren't asking for text output functions |
| 05:49 | <Hixie> | on another note, fips180-2 is a remarkably well-written spec |
| 05:49 | <Hixie> | (the sha spec) |
| 05:51 | <othermaciej> | cryptographers know how to be precise |
| 05:51 | <Hixie> | apparently |
| 05:53 | <Hixie> | hm, a request for dashed lines. |
| 05:53 | <Hixie> | in canvas. |
| 05:56 | Hixie | says no based on the lack of demand |
| 05:59 | jruderman | wonders if it's dangerous to say "no based on lack of demand" |
| 05:59 | <jruderman> | are his friends suddenly going to all demand it? |
| 05:59 | <Hixie> | i say "no" to almost everything |
| 05:59 | <othermaciej> | having dashed lines requires the means to define a dash pattern |
| 05:59 | <Hixie> | it's one of the things i wish other spec authors would do :-) |
| 06:00 | Hixie | looks at svg |
| 06:00 | <othermaciej> | they say yes to things that they afterwords can't explain the use case for |
| 06:00 | <othermaciej> | *afterwards |
| 06:02 | <jruderman> | if they can remember a use case, they include it in the "tiny" profile, right? |
| 06:04 | <othermaciej> | no, the "tiny" profile includes things where they can't |
| 06:04 | <othermaciej> | like the network API |
| 06:04 | <Hixie> | the network API has lots of use cases |
| 06:04 | <Hixie> | they just don't match the API... |
| 06:04 | <othermaciej> | someone asked if a different network API satisfied the same use cases, and they couldn't name what the use cases were |
| 06:05 | <Hixie> | oh hah |
| 06:05 | <Hixie> | that's funny as heck |
| 06:05 | <Hixie> | anyway gotta go home |
| 06:05 | <othermaciej> | laters |
| 06:06 | <Hixie> | while i'm cycling home, consideer: should isPointInPath(x, y) convert x,y to the CTM before comparing it to the path? or should it convert the path via the CTM? or neither? and why? |
| 06:06 | <Hixie> | later |
| 08:15 | <annevk> | Hixie, yes, that address is made dead by my hosting provider... |
| 08:15 | annevk | will at some point switch to dreamhost for that domain |
| 08:17 | <jruderman> | annevk: if i remove a <link> element that's a titled stylesheet from a document and then put it back in (perhaps by removing the entire head and then putting the entire head back in), is it treated as a "new" stylesheet that goes through the algorithm for determining whether it's enabled, or does it remember whether it was enabled from before? |
| 08:18 | <jruderman> | annevk: i'd kinda prefer it remembering, because i like it when removing a node from a document and putting it back doesn't cause any visual changes |
| 08:18 | <jruderman> | annevk: but i figured your spec should say and it doesn't seem to say |
| 08:18 | <annevk> | I think it would be "new" |
| 08:18 | <annevk> | you might have made some changes in between or such |
| 08:18 | <jruderman> | hmm |
| 08:18 | <annevk> | but yeah, the spec doesn't say |
| 08:19 | annevk | has too many specs to edit :( |
| 08:19 | <jruderman> | yeah, making changes to the <link> node while it's out of the document that would complicate things |
| 08:19 | <annevk> | and then there's public-html... I should stop reading that |
| 08:19 | <jruderman> | hehe |
| 08:19 | <jruderman> | +1 |
| 08:20 | <jruderman> | ok, i'll just update my "remove node, put it back, see if there are any visual changes" testing thingie to skip files that have scripts tweaking .disabled |
| 08:20 | <othermaciej> | which spec is this? |
| 08:21 | <jruderman> | http://dev.w3.org/cvsweb/~checkout~/csswg/cssom/Overview.html?rev=1.35#dynamically (i'm not sure how to link to that spec properly) |
| 08:22 | <othermaciej> | CSSOM rides again! |
| 08:25 | <annevk> | the "proper" link is http://dev.w3.org/cvsweb/~checkout~/csswg/cssom/Overview.html?content-type=text/html;%20charset=utf-8 |
| 08:25 | <annevk> | (without the version number but with the cruft that forces it to be UTF-8 as opposed to the default of ISO-8859-1) |
| 08:26 | <othermaciej> | annevk: looks pretty promising just based on what interfaces you put in so far |
| 08:27 | <annevk> | thanks |
| 08:35 | <Hixie> | anne, did you get the feedback from boris about that spec? |
| 08:37 | <annevk> | there's some stuff on www-style I've to look at |
| 08:37 | <annevk> | that you forwarded |
| 08:37 | <annevk> | I integrated changes to method names when they made those in Mozilla's implementation (on my recommendation), apart from that, not yet |
| 08:38 | <Hixie> | it was about changing attributes and how it affects .disabled, iirc |
| 08:38 | <Hixie> | would be nice for the mozilla guys if you could address that relatively soon, i think they're trying to implement it |
| 08:42 | <annevk> | k, on the list |
| 08:42 | annevk | wonders why the **** he doesn't receive e-mail from W3C lists |
| 08:43 | annevk | uses lists.w3.org to find about a small continued thread on XHR |
| 08:43 | <Hixie> | heh |
| 08:49 | <annevk> | http://lists.whatwg.org/pipermail/help-whatwg.org/2007-May/000040.html |
| 08:52 | <Hixie> | yeah, saw that |
| 08:53 | <Hixie> | how unfortunate for them that they didn't send it to the list that i promised to reply to all feedback for |
| 08:53 | <Lachy> | heh |
| 08:54 | <annevk> | :p |
| 08:54 | <Lachy> | just reply and say the web ontology RDF/OWL stuff is planned for HTML6 :-) |
| 08:54 | <annevk> | now you said that I'll threaten to forward it anyway if you don't include the brilliant <di> element :p |
| 08:57 | <Lachy> | does anyone know of any real world, practical use cases for RDF? (except for one of the obsolete versions of RSS) |
| 08:59 | <Hixie> | annevk: oh i wouldn't mind replying to them |
| 08:59 | annevk | was kidding there :) |
| 08:59 | <Hixie> | i mean, they didn't actually propose anything as far as i can tell |
| 08:59 | <Hixie> | and i don't understand their use case |
| 08:59 | <Hixie> | so it'd be a pretty standard "Thanks for your feedback, I don't understand exactly what problem it is you are trying to solve, could you elaborate?" |
| 09:00 | <Hixie> | anyway i should go to sleep |
| 09:00 | <Hixie> | nn all |
| 09:00 | <Lachy> | good night Hixie |
| 09:02 | <othermaciej> | I think I should find out what an "information architect" does exactly, then I will understand why you might want "an ontology" |
| 09:02 | <annevk> | night |
| 09:03 | <Lachy> | an information architect works on how to organise and structure information on a web stie to make it easy to find, use and access. |
| 09:04 | <Lachy> | I'm not sure how that helps figure out why they would want an ontology though |
| 09:05 | <annevk> | othermaciej, your comments on XHR make sense, I'll add a Conforming XML user agent |
| 09:06 | <othermaciej> | annevk: thanks |
| 09:42 | <virtuelv> | heh, http://www.456bereastreet.com/archive/200705/help_keep_accessibility_and_semantics_in_html/ |
| 09:43 | <othermaciej> | do it for the kids |
| 09:46 | <othermaciej> | I think there needs to be some pro-HTML5 advocacy action |
| 09:47 | <virtuelv> | "The new spec sounds like "If we make theft legal, crime rates will drop"" |
| 09:47 | <virtuelv> | ( http://www.456bereastreet.com/archive/200705/help_keep_accessibility_and_semantics_in_html/#comment29 ) |
| 09:48 | <virtuelv> | dunno, but I find 'helpful' suggestions like "Insist that browser vendors implement some kind of error logging for HTML, like iCab does." to be somewhat unintentionally funny |
| 09:48 | <virtuelv> | as a user, I couldn't care less |
| 09:48 | <virtuelv> | and "Insist that error handling for browsers is mentioned far away from the parts of the spec that web developers will read." |
| 09:48 | <othermaciej> | unfortunately few self-styled web standards advocates have moved beyond the smug superiority stage |
| 09:48 | <virtuelv> | no, what those people need is a best practices-document, not a spec |
| 09:49 | <virtuelv> | I almost feel like responding |
| 10:07 | <jgraham> | I liked Roger's comment "I would like draconian error handling" on a page served as text/html... |
| 10:10 | <othermaciej> | heh |
| 10:20 | <annevk> | zcorpan, no need for a reminder |
| 10:20 | <annevk> | I will leave SHOULD level requirements in tact though |
| 10:20 | <annevk> | and have noted at the start that they must follow the steps (unless otherwise noted) |
| 10:20 | <annevk> | which should cover that |
| 10:21 | <zcorpan> | annevk: ok, great |
| 10:24 | <zcorpan> | is Brad "[whatwg] Proposal: Allow block content inside label element" Fults talking through his hat? |
| 10:39 | annevk | starts receiving fragments of e-mail |
| 10:39 | annevk | updates XHR meanwhile to beat the comments he already saw in the archives! |
| 10:54 | mpt | couldn't resist commenting |
| 10:56 | <mpt> | ah, and Lachy talked about all the things I didn't, yay |
| 10:57 | annevk | thought for a moment that mpt meant commenting on XHR |
| 10:57 | <mpt> | I am (blissfully?) unaware of what XHR is |
| 10:57 | <mpt> | It sounds like some sort of security vulnerability |
| 10:58 | <annevk> | short for XMLHttpRequest |
| 11:00 | <mpt> | ah |
| 11:01 | <Lachy> | mpt, are you refering to my comment on 456bereastreet? |
| 11:01 | <mpt> | yes |
| 11:01 | <mpt> | ("all the things I didn't" was quite a lot, in retrospect;-) |
| 11:02 | <Lachy> | my comment ended up longer than the actual article :-) |
| 11:02 | <mpt> | If it's worth being wrong, it's worth being wrong in such a way that requires much longer to rebut than to state |
| 11:03 | <annevk> | HTML is quite a waste of everyone's time |
| 11:03 | <mpt> | annevk, you'll earn the right to say that *after* XML5 reaches REC |
| 11:03 | <othermaciej> | the WG or the langauge? |
| 11:04 | <Lachy> | the WG |
| 11:05 | <met_> | articles like 456bereastreet explains to mee, why is more and more spam in html wg mailing list |
| 11:06 | <Lachy> | I'm going to try and avoid posting to the list for a few days, which should help reduce the volume of mail since there won't be any arguing with me :-) |
| 11:09 | <annevk> | yeah, I'm sort of doing that too |
| 11:09 | <annevk> | mpt, heh |
| 11:10 | <annevk> | I'll wait until the chairs do something useful |
| 11:10 | <mpt> | which ones? |
| 11:10 | <othermaciej> | htmlwg chairs |
| 11:10 | <othermaciej> | Chris Wilson and Dan Connolly |
| 11:11 | <mpt> | How would that be relevant to XML5? |
| 11:11 | <othermaciej> | I don't think anyone else here is talking about XML5 |
| 11:12 | <mpt> | I said "you'll earn the right to say that *after* XML5 reaches REC", and annevk replied "I'll wait until the chairs do something useful" |
| 11:13 | <annevk> | (My reply to mpt was unrelated to the other two sentences which were.) |
| 11:13 | <annevk> | (Sorry for the confusion.) |
| 11:13 | <mpt> | oh. |
| 11:13 | <annevk> | my IRC replying is not often in sync |
| 11:23 | <Lachy> | Philip`, yt? |
| 11:46 | <jdandrea> | annevk: Wild pitch here ... WRT standardizing class values (let's say w/o scoping for a moment), would it make any sense to recognize said values _only_ when <!DOCTYPE html> is specified? |
| 11:49 | <othermaciej> | jdandrea: tehnically, what you do when that doctype is not specified is undefined (though the spec is meant to be usable in such cases) |
| 11:49 | <Dashiva> | jdandrea: Intuitively, no. That's basically the same as using a prefix, in either case no existing pages benefit |
| 11:49 | <othermaciej> | it really depends on your use case |
| 11:49 | <othermaciej> | I can see a UI use for class=search |
| 11:49 | <annevk> | jdandrea, I suggested we use that as argument to convince the non-believers |
| 11:49 | <jdandrea> | annevk: ah, ok |
| 11:49 | <othermaciej> | browsers could use it to identify a search form and have a keyboard shortcut to jump to it for instance |
| 11:49 | <jdandrea> | Dashiva: good point |
| 11:50 | <othermaciej> | but I'm not sure what the use case for class="copyright" would be |
| 11:50 | <annevk> | stylistic hook |
| 11:50 | <jdandrea> | othermaciej: understood - in fact that's what we did at my former employer - we even used (drum roll please) ... copyright ... and search ... |
| 11:50 | <annevk> | finding and maybe exposing copyright information for the site |
| 11:51 | <othermaciej> | stylistic hook can exist w/ no help from the spec |
| 11:51 | <jdandrea> | annevk: yes, we used it primarily as a stylistic hook. We also standardized various bits of markup ("containers" if you will) using class names, sometimes on paragraphs, or divs, and so on. |
| 11:51 | <othermaciej> | unless you imagine UAs would hav a default style for it |
| 11:52 | <othermaciej> | I'm not sure about finding copyright info, would that be a browser feature, or something search engines do? |
| 11:52 | <jdandrea> | So in that sense it was for authors - to give them a point of reference when editing other people's markup. |
| 11:52 | <othermaciej> | would class="copyright" do better than heuristics? |
| 11:52 | <othermaciej> | can heuristics check validity of the found data? |
| 11:52 | <othermaciej> | etc |
| 11:52 | jdandrea | thinks about heuristics ... |
| 11:52 | <othermaciej> | (like checking for the string "Copyright" |
| 11:52 | <othermaciej> | ) |
| 11:52 | <jdandrea> | Wouldn't finding © (or the numeric equiv) - exactly ... |
| 11:53 | <annevk> | heuristics is not exactly language neutral |
| 11:53 | <othermaciej> | proper copyright notices have a pretty standard textual form and can readily be identified without markup |
| 11:53 | <annevk> | well, it complicates that |
| 11:53 | <jdandrea> | I might not use the word Copyright though. |
| 11:53 | <jdandrea> | (Copyleft?) |
| 11:53 | <annevk> | but that goes for currently used class names too, I suppose |
| 11:53 | <jdandrea> | CC? |
| 11:53 | <othermaciej> | actually, the standard for how to note a copyright is international |
| 11:54 | <annevk> | the ©? |
| 11:56 | <jdandrea> | Or is CC more of a "License" than a copyright (hmm, license ... :) ) |
| 11:56 | <jdandrea> | <a rel="license" href="http://creativecommons.org/licenses/by/3.0/">; |
| 11:56 | <jdandrea> | (spotted within http://creativecommons.org/about/licenses ) |
| 12:06 | <othermaciej> | creative commons licenses are a type of license |
| 12:06 | <othermaciej> | a copyright notice may mention a license |
| 12:06 | <othermaciej> | but they are not really the same thing |
| 12:06 | <jdandrea> | aye |
| 12:06 | <jdandrea> | but they can be mentioned within a copyright - ack |
| 12:07 | <jdandrea> | s/ack/ack'd/ |
| 12:12 | <annevk> | 'Molly Asks You: HTML, hasLayout and The Meaning of “Framework”' you'd think working for MSFT she would get the answer to the second one pretty easily... |
| 12:14 | <annevk> | oh, I should've read the comments |
| 12:14 | <annevk> | she hasn't found the person who knows yet :) |
| 12:15 | <mpt> | The Flickr photo is fantastic though |
| 12:17 | <Lachy> | I think I gave a reasonably accurate answer for the hasLayout question |
| 12:17 | <Lachy> | mpt, what flickr photo? |
| 12:18 | <Lachy> | ah, found it in the comments |
| 12:18 | <annevk> | http://flickr.com/photos/retrocactus/489377466/ |
| 12:27 | <Dashiva> | some of the browser vendors have no interest whatsoever in doing anything to make the lives of developers easier (...) pandering to people who can't be bothered to learn how to write HTML properly |
| 12:28 | <Dashiva> | Would be nice if people tried to at least wait with contradicting themselves until the next paragraph |
| 12:29 | <Lachy> | where did that quote come from? |
| 12:29 | <mpt> | Perhaps they mean, "the kind of developers who fetishize validity" |
| 12:32 | <Lachy> | I don't know what could possibly make lives of developers easier, than by being more lenient in what they accept |
| 12:33 | <mpt> | oh, there's lots of things |
| 12:33 | <Lachy> | it makes thier lives too easy, which is why they can get away with mistakes |
| 12:33 | <mpt> | parsimony |
| 12:33 | <mpt> | clarity |
| 12:33 | <mpt> | tools |
| 12:33 | <Lachy> | tools that do what authors want can be provided regardless of what browsers support |
| 12:34 | <Dashiva> | Lachy: It's from the author comment on http://www.456bereastreet.com/archive/200705/browsers_will_treat_all_versions_of_html_as_html_5/ |
| 12:34 | <mpt> | Sorry, I confused "than by" with "other than" |
| 12:35 | <Lachy> | ah, no woder I couldn't find it on the maling list :-) |
| 12:38 | <Lachy> | I spoke to Roger on MSN about the issues he has. I think it's just a matter of making people feel more welcomed into the group, watching the tone of our emails, and and trying to clearly explain why some things have to be done the way they are |
| 12:38 | <Lachy> | anyway, I gotta go, back later |
| 13:07 | <annevk> | We need something alongside RFC2119 that defines common web spec terminology |
| 13:07 | <annevk> | such as ascii case-insensitive, case-insensitive, link, etc. |
| 13:08 | <annevk> | (not my idea, btw) |
| 13:22 | annevk2 | totally missed Ian's e-mail on sandboxing between all the other stuff |
| 13:22 | <annevk2> | or maybe I just received it later |
| 13:33 | <Philip`> | Incremental SHA-512 sounds quite unpleasantly slow - you'd have to do a computation (with 80 rounds of stuff) on 1024 bits for every byte you parse, because you can't incrementally compute the 1024-bit blocks. I guess you could fix that by copying rsync and having a cheap incremental checksum (e.g. CRC32) to find a probable end position, and use the strong checksum to verify it, which wouldn't be much harder for people writing server-side code. |
| 13:33 | <Philip`> | Lachy: Good morning |
| 13:33 | <annevk2> | having some new attributes on <iframe> seems sort of sane |
| 13:33 | <annevk2> | but it doesn't appear to be entirely backwards compatible |
| 13:34 | <annevk2> | besides that, if implementation have bugs... |
| 13:34 | <Philip`> | <iframe src="data:..."> isn't compatible with IE6/IE7 at all, so it doesn't seem very useful from that perspective |
| 13:36 | <Philip`> | (See e.g. http://canvex.lazyilluminati.com/misc/copyright.html and someone complaining it didn't work in IE) |
| 13:37 | <annevk2> | well, that it's incompatible is actually a good thing here, I think |
| 13:38 | <annevk2> | oops |
| 13:38 | <annevk2> | if backcompat is not a requirement having <sandbox src=>download something better</sandbox> might be better |
| 13:39 | <Philip`> | Apparently it's incompatible in a way that makes download boxes pop up when you try visiting the site in IE7, which means you'd have to do browser-sniffing in order to degrade less ungracefully |
| 13:40 | <annevk2> | i see |
| 13:40 | <Philip`> | though I guess you could also do <iframe src="getadvert.cgi" let-style-through></iframe> and then it'd work alright - it's only the data: that's a problem |
| 13:41 | <annevk2> | yeah, except you don't want the script to access the parent doc |
| 13:44 | <Lachy> | Philip`, can you send me the code you used to run those surveys for the class attribute, and brief instructions on how to use it? |
| 13:45 | <Lachy> | I've got html5lib, just the additional code |
| 13:46 | <annevk2> | maybe that should go into p/html5/ as well? |
| 13:46 | <annevk2> | in some survey directory? |
| 13:48 | <Philip`> | I don't think it'd be entirely trivial to send, since some of it involved manually editing the database to work around broken pages, and the current version ignores a fifth of the pages since they don't serialise to well-formed XML; but I'd be willing to fix it up so the whole process works straightforwardly |
| 13:50 | <Lachy> | yeah, sure, whatever you can do to make it easier to run surveys when we need to |
| 13:50 | <annevk2> | someone should just sit down for a few days and write the C version of html5lib |
| 13:51 | <annevk2> | (someone with actual knowledge of C; I believe it would take me much longer) |
| 13:51 | <annevk2> | then we no longer need silly XML parsers for speed afterwards I hope... |
| 13:53 | <Philip`> | What data structure would the C version parse into? Should it fit onto the end of something like libxml2 so you can use the standard APIs and wrappers and extra features (like XPath and whatever)? |
| 13:54 | <annevk2> | yeah |
| 13:55 | <annevk2> | and hopefully easily usable from Python too... |
| 14:02 | <met_> | annevk2 what about IronPython? and compile html5lib into .NET? |
| 14:03 | <annevk2> | That stuff should speed it up, but I don't think it would do as doing all the hard work in C |
| 14:03 | met_ | tried to run html5lib under IronPython and it partlyworks |
| 14:03 | <virtuelv> | http://www.intertwingly.net/blog/2007/05/08/Dont-Break-The-Web |
| 14:03 | <virtuelv> | What's up with the html4 example being valid? |
| 14:05 | <annevk2> | Doesn't <body> require some children? |
| 14:05 | <annevk2> | Doesn't have much to do with breaking the web though |
| 14:06 | <met_> | <html><body /></html> looks nice 8-) |
| 14:06 | <met_> | even with onload="writeSomeBodyContent()"' |
| 14:07 | <annevk2> | oh wait |
| 14:07 | <annevk2> | the .diff files don't show the whole file, duh |
| 14:07 | <Philip`> | It's more "making the web non-conforming" rather than "breaking the web", but seeing as the web is non-conforming anyway that doesn't seem to make much difference |
| 14:08 | annevk2 | tries to reply from a flaky network |
| 15:30 | <annevk2> | So his point is that <input size=2> should be conforming? |
| 15:30 | <annevk2> | Whatever... |
| 15:33 | <wilhelm> | I agree with that. <input name='postnummer' size='4'> makes perfect sense..(c: |
| 15:34 | <annevk2> | pattern=[0-9]{4} |
| 15:34 | <annevk2> | and maxlength=4 maybe |
| 15:34 | <Philip`> | and style="width:4em"? |
| 15:35 | <Philip`> | (but I don't know what CSS unit would match the size attribute) |
| 15:35 | <Lfe> | parsing html5lib into same data structures as libxml2 uses would be neat; then lxml might as well be used as python "frontend" |
| 15:35 | <annevk2> | maybe ch |
| 15:39 | <annevk2> | (as in, style=width:4ch} |
| 15:39 | <mpt> | ugh, Safari sniffs those diffs as HTML |
| 15:40 | <Philip`> | Looks like size = em > ch in FF3, and size < em (and ch doesn't exist) in O9 |
| 15:41 | <annevk2> | yeah, em is the font-size and ch is the average character width |
| 15:41 | <annevk2> | part of some CSS3 spec |
| 15:41 | <mpt> | I remember the Gecko hackers struggling to figure out what size= meant in IE4 so they could copy it |
| 15:42 | <Philip`> | and size > em in IE6 |
| 15:43 | <Philip`> | Oh, actually, it depends on the font |
| 15:45 | <Philip`> | ...and depends in different ways in different browsers |
| 15:45 | <Philip`> | and size=4 doesn't guarantee that four characters will fit in the box, in any of them |
| 15:45 | <Philip`> | so I guess switching to em would generally work no worse than using size |
| 15:52 | <annevk2> | Apparently there's no specification that defines what happens with <!-- in a script block |
| 15:52 | <annevk2> | bah |
| 15:52 | <mpt> | iirc it was the width of an "e" character or something weird |
| 15:52 | <mpt> | or an "a" |
| 15:53 | <Philip`> | (Links/Lynx don't do very well with CSS-sized input boxes, though) |
| 15:54 | <Lachy> | In IE, it appears that size=n is calculated as: (size=1) + n * increment |
| 15:55 | <Lachy> | where 'increment' is some yet to be determined value |
| 15:55 | mpt | goes spelunking |
| 15:55 | <mpt> | I think it's the width of an "a" character in MS Sans Serif |
| 15:55 | <mpt> | or in Arial |
| 15:56 | <mpt> | at the relevant size |
| 15:59 | <Philip`> | I get a much wider box if I use size=4 and set the font to Arial compared to setting it to Verdana |
| 16:00 | <Philip`> | which doesn't actually make sense since Verdana's characters are wider than Arial's |
| 16:00 | <zcorpan> | annevk2: yeah, i found out recently too. ecmascript262 should define <!-- to be equivalent to // |
| 16:03 | <Philip`> | What happens when you use some other scripting language and put <!-- in it? |
| 16:03 | <mpt> | https://bugzilla.mozilla.org/show_bug.cgi?id=25657 is somewhat relevant |
| 16:04 | <Philip`> | (VBScript, PerlScript, etc) |
| 16:05 | <zcorpan> | Philip`: if <!-- is a one-liner comment in those languages (like in JS) then it's a one-liner comment... otherwise it's a syntax error or means something else? |
| 16:05 | <annevk2> | zcorpan, is that actually how <!-- works? |
| 16:05 | <zcorpan> | annevk2: yes |
| 16:06 | <annevk2> | except when it's used in some special way? |
| 16:06 | <zcorpan> | what do you mean? |
| 16:06 | <zcorpan> | it's equivalent to // |
| 16:06 | <annevk2> | sorry, what about --> ? |
| 16:06 | <zcorpan> | that's nothing |
| 16:06 | <zcorpan> | syntax error |
| 16:07 | <mpt> | "The solution for this now until a spec decides how buttons must be sized is to have buttons always size in NavQuirks mode." -- https://bugzilla.mozilla.org/show_bug.cgi?id=96630 |
| 16:07 | <zcorpan> | that's why you need to use //--> |
| 16:07 | <zcorpan> | CSS has both <!-- and --> though |
| 16:11 | mpt | can't find the money quote |
| 16:12 | <mpt> | Relatedly, size= can be somewhat semantic |
| 16:12 | <mpt> | e.g. a short account name field, a long passphrase field |
| 16:13 | <mpt> | they hint at the desired length of the input |
| 16:13 | <zcorpan> | mpt: yeah, it says the length of the *expected* input, without putting a restriction |
| 16:14 | <annevk2> | zcorpan, so <!-- alert(1) does not work? |
| 16:14 | <annevk2> | zcorpan, what about the <!-- document.write(1) --> sample in the HTML5 parsing spec? |
| 16:15 | <zcorpan> | annevk2: correct |
| 16:15 | <zcorpan> | the sample also doesn't do anything |
| 16:15 | <Philip`> | Ah, VBScript in IE does seem to treat <!-- always like ' (except when it's in a string) and also does the same for --> when on a line preceded only by whitespace |
| 16:16 | <zcorpan> | you can also use <!-- anywhere where you can use // |
| 16:16 | <zcorpan> | Philip`: cool |
| 16:16 | Philip` | wonders how it works in PerlScript where you can't even tell what's a string without being a whole Perl interpreter |
| 16:16 | <zcorpan> | didn't think any scripting language treated --> specially |
| 16:17 | annevk2 | wonders if what zcorpan says actually matches any impl |
| 16:17 | <zcorpan> | annevk2: why don't you try it :) |
| 16:17 | <zcorpan> | this is not specced anywhere |
| 16:17 | <zcorpan> | what i say is what i've found in imps |
| 16:18 | <annevk2> | for instance <script><!--\n<!--\nalert(1)\n-->\n//--></script> does not execute in Opera where it does in other browsers |
| 16:18 | <annevk2> | \n is a newline |
| 16:19 | <zcorpan> | probably because of the --> being a syntax error? |
| 16:19 | <annevk2> | I'm pretty sure Firefox has even more complicated tokenizing to make E4X sort of work for type=text/javascript |
| 16:20 | <zcorpan> | could be, i didn't test it througly |
| 16:20 | <Philip`> | Oh, that's a VBS/JS inconsistency |
| 16:20 | <zcorpan> | just did some alerts with <!-- in different places |
| 16:21 | <annevk2> | hmm |
| 16:21 | <Philip`> | "<!-- alert(1)\nalert(2)\n--> alert(3)" is a syntax error in JS, but runs the alert(2) in VBScript |
| 16:22 | <zcorpan> | iirc Hixie and mjs confirmed that <!-- was the same as // |
| 16:23 | <Philip`> | (so I guess in IE's implementation it's up to the scripting engine to fix the HTML-mangled code into something valid for their language, and they don't all quite do it the same) |
| 16:23 | <annevk> | alert(2) runs in Firefox |
| 16:23 | <annevk> | doesn't in Opera and IE7 |
| 16:23 | <annevk> | (Firefox2) |
| 16:23 | <annevk> | got to love browsers |
| 16:23 | <Philip`> | Should just make HTML comments in <script> be non-conforming :-) |
| 16:24 | <annevk> | that definitely solves the implementation problem |
| 16:24 | <annevk> | oh, wait! |
| 16:24 | <zcorpan> | leave it undefined! |
| 16:25 | <MichaelMH> | yo |
| 16:25 | <Philip`> | It could help solve the problem for future scripting languages, because those will only be supported in new browsers, and they could just not implement the <!-- stuff for those languages (because there's no content to be compatible with, and because the spec doesn't suggest it's a good thing to do) |
| 16:26 | <annevk> | argh |
| 16:28 | <MichaelMH> | yo phill, you know how you talked about creating a canvas tutorial..? |
| 16:28 | <annevk> | <!--\n<!--\nalert("PASS")\n-->\n--> |
| 16:28 | <annevk> | works in IE and Firefox |
| 16:28 | <annevk> | <!--\n<!--\nalert("PASS")\n-->x\n--> |
| 16:28 | <annevk> | works only in Firefox |
| 16:29 | <zcorpan> | annevk: you should save these tests somewhere... i think mjs were going to bug the ecmascript262 maintainers about defining <!-- |
| 16:29 | <Philip`> | MichaelMH: Indeed |
| 16:30 | <annevk> | Someone from Opera will bug the ECMA comittee |
| 16:30 | <MichaelMH> | so.. I was just thinking, today is a fine day for tutorial making |
| 16:30 | <annevk> | It's just not clear they'll accept it |
| 16:31 | <annevk> | It's also not clear what exactly needs to happen |
| 16:31 | <annevk> | but yes, how about /ecmascript/html-comments/ ? |
| 16:33 | <zcorpan> | annevk: that's a good place to put them |
| 16:34 | <MichaelMH> | I tryed to write a flash tutorial once. It was a bit ambitious and didn't really happen |
| 16:36 | Philip` | has too much work at the moment to do anything useful, unfortunately :-( |
| 16:36 | <MichaelMH> | also I lacked understanding in several key parts and didn't know the name of stuff. I think I called the color picker the magical color box |
| 16:38 | <MichaelMH> | Oh ok. I was just wondering about it. |
| 16:38 | <JonT> | Hey |
| 16:39 | <JonT> | that was a test |
| 16:39 | <MichaelMH> | I'm actually have trouble with animations. every part of the mozilla tut is quite simple and easy to follow for newbs but when it comes to the animation bit the code isnt really explained there is just two examples |
| 16:42 | <annevk> | http://tc.labs.opera.com/ecmascript/html-comments/ |
| 16:42 | <JonT> | Anne: "Not Found" |
| 16:44 | <annevk> | oh, my initial svn commit failed |
| 16:44 | <annevk> | try again |
| 16:44 | <Philip`> | MichaelMH: Is it the general animation system that's confusing (i.e. having a function to draw one frame, and using setInterval to call it repeatedly) or the bits it's doing inside the drawing function (i.e. changing some values so it draws something different each frame)? |
| 16:46 | <MichaelMH> | well, you see here http://developer.mozilla.org/en/docs/Canvas_tutorial:Basic_animations |
| 16:46 | <MichaelMH> | theres two examples and I just thought a break down of code which says whats going on would be helpful |
| 16:48 | <MichaelMH> | is it supposed to move only on refresh..? |
| 16:49 | <Philip`> | The setInterval('draw()',100); line makes it repeat the draw() function every 100ms, so it'll constantly redraw the image |
| 16:53 | Dashiva | points out the evil of 'draw()' |
| 16:53 | Philip` | points out the Edit button on the wiki ;-) |
| 16:55 | <MichaelMH> | um.. |
| 16:55 | <MichaelMH> | could somebody make like a really really simple example of like a rectangle being moving or something |
| 17:00 | <Philip`> | MichaelMH: Maybe something like <canvas id="c"></canvas><script>var t = 0; function draw() { var ctx = document.getElementById('c').getContext('2d'); t++; if (t > 100) t = 0; var x = t*2; ctx.clearRect(0, 0, 300, 150); ctx.fillRect(x,0,50,50) }; setInterval(draw, 50)</script> |
| 17:00 | <Philip`> | though it's probably better on multiple lines |
| 17:00 | Dashiva | points out "You have to login to edit pages." |
| 17:01 | <Philip`> | Dashiva: That's why I haven't bothered editing it myself :-) |
| 17:01 | <Dashiva> | : |
| 17:01 | <Dashiva> | ) |
| 17:03 | <MichaelMH> | aww brilliant phill. thank you so much |
| 17:06 | <Philip`> | <canvas id="c"></canvas><script>var t = 0; function draw() { var ctx=document.getElementById('c').getContext('2d'); t++; if (t > 100) t = 0; var x = t*2; ctx.save(); ctx.fillStyle = 'white'; ctx.globalAlpha = 0.2; ctx.fillRect(0, 0, 300, 150); ctx.restore(); ctx.fillRect(x, 0, 50, 50)} setInterval(draw, 50)</script> - motion blur |
| 17:06 | <Philip`> | ...and a bug in Opera because the white background turns (250,250,250) |
| 17:07 | <MichaelMH> | I'm a bit confused how you wrote the if statment |
| 17:08 | annevk | wonders how many issues will be resolved once Kestrel is out |
| 17:08 | <MichaelMH> | its got no curley bits |
| 17:08 | <Dashiva> | annevk: Having to be quiet about it is a drain :) |
| 17:09 | <Philip`> | MichaelMH: If you only have one statement in the block, then "if (c) s;" is equivalent to "if (c) { s; }" |
| 17:10 | <Philip`> | (but "if (c) s; t;" is equivalent to "if (c) { s; } t;") |
| 17:10 | <MichaelMH> | ah right. I was googling different ways of writing if statements but I couldnt find anything |
| 17:11 | <MichaelMH> | yeah I got that. |
| 17:11 | <Philip`> | It's probably better to keep the braces in so it's less confusing and less likely to go wrong, except when you're trying to write a web page inside the location bar and you want to save some characters |
| 17:12 | <MichaelMH> | but it takes too long. to write a whole extra character. not worth the effor |
| 17:14 | <MichaelMH> | so clear rectangle nukes the canvas? and ctx.fillRect(x,0,50,50) is the new rectangle and x is the new position? |
| 17:15 | <Philip`> | Yep, clearRect makes the area transparent |
| 17:15 | <MichaelMH> | thats wierd. cus if it is clear wouldnt It just mean nothing at all would happen |
| 17:15 | <Philip`> | and fillRect does the drawing like normal, but x is calculated from t, and t is incremented every time draw() is called |
| 17:16 | <Dashiva> | It's important to remember there are no objects on the canvas, just a lot of pixels |
| 17:16 | <Philip`> | clearRect deletes whatever is currently drawn in that area, instead of drawing a new transparent rectangle on top |
| 17:17 | <Philip`> | (You could do the latter via "ctx.fillStyle = 'transparent'; ctx.fillRect(...)", and it would do nothing at all) |
| 17:17 | <Philip`> | (...except I think Opera doesn't do 'transparent' either) |
| 17:20 | <MichaelMH> | Uh oh! Browser crashed. bad bad things happen if you forget to use clearRect |
| 17:21 | <Philip`> | Uh, that shouldn't happen |
| 17:21 | <MichaelMH> | why? |
| 17:21 | <Philip`> | Could you post an example that breaks? |
| 17:21 | <Philip`> | Browsers are never meant to crash |
| 17:22 | <MichaelMH> | yeah it just crashed again |
| 17:22 | <MichaelMH> | http://www.michaelmh.com/stuff/newbie/Mbad.html |
| 17:22 | <annevk> | Philip`, if you have a list of Opera bugs... |
| 17:23 | <MichaelMH> | it just keeps increasin the M without clearing the old one |
| 17:24 | <MichaelMH> | oh wait |
| 17:24 | <MichaelMH> | it still crashes. I must be doing something else wrong |
| 17:25 | <MichaelMH> | :S |
| 17:25 | <Philip`> | MichaelMH: Ah, it seems to just freeze Firefox rather than actually crashing |
| 17:26 | <Philip`> | The problem is that you're calling ctx.scale() in the first call to draw(), and then you're calling it again in the second draw() without having reset the context back to its original state |
| 17:26 | <Philip`> | so it's scaling larger and larger every frame, and so the drawn shape keeps getting larger and taking longer to draw |
| 17:27 | <MichaelMH> | ah ic |
| 17:27 | <Philip`> | You should call ctx.save() at the top of draw (just after getting ctx), and then ctx.restore() at the end of it, which will reset everything back to normal |
| 17:27 | <MichaelMH> | so I should set it back to ctx.scale(1,1);? |
| 17:28 | <MichaelMH> | oh ok |
| 17:28 | <Philip`> | scale() is always relative to the current scale, so scale(1,2);scale(1,2) will make it four times as large, and scale(1,1) will never do anything |
| 17:30 | <Philip`> | annevk: I've just got the list at http://canvex.lazyilluminati.com/tests/tests/results.html but they're not all legitimate bugs (since some depend on things the spec doesn't define yet) and I'm trying to add more bits, but then I'm intending to clean up the list and find the actual bugs to report |
| 17:31 | <annevk> | ok, cool |
| 17:32 | <Philip`> | (I don't know when I'll have time, but hopefully it'll be before any browser has another major release which entrenches more bugs :-) ) |
| 17:32 | <annevk> | your 2d.fillStyle.get.transparent seems to strict |
| 17:33 | <MichaelMH> | alright check out these crazy animation skills: http://www.michaelmh.com/stuff/newbie/M.html |
| 17:33 | <annevk> | rgba(0, 0, 0, 0) is not conforming where rgba(0, 0, 0, 0.0) is... |
| 17:33 | <annevk> | as long as the last argument is zero it should be ok i think |
| 17:33 | <Philip`> | annevk: I'm fairly certain the spec says it has to be 0.0 |
| 17:33 | <annevk> | that'd be a bug in the spec |
| 17:34 | <Philip`> | http://canvex.lazyilluminati.com/tests/tests/spec.html#testrefs.2d.colours.getcolour.transparent - "a U+0030 DIGIT ZERO, a U+002E FULL STOP (representing the decimal point), one or more digits in the range 0-9 (U+0030 to U+0039) representing the fractional part of the alpha value" |
| 17:34 | <Philip`> | (so I suppose I should accept 0.00 and 0.000 etc too, but that'd be silly) |
| 17:35 | <annevk> | I don't think accepting those too would be silly... |
| 17:36 | <MichaelMH> | you know what would be cool. if there was a program that you could create wysiwyg canvas stuff then export the code |
| 17:36 | <Philip`> | http://lists.whatwg.org/pipermail/whatwg-whatwg.org/2007-April/010939.html has some comments about how colours are returned |
| 17:37 | <Philip`> | (Opera, Firefox, Safari and the spec all disagree) |
| 17:38 | <Philip`> | so I don't think it would hurt at all to fix the spec, if there's a suggestion of what behaviour is best |
| 17:38 | <annevk> | returning an 4-value array makes sense to me |
| 17:38 | <annevk> | i'm pretty sure return values are parsed though |
| 17:38 | annevk | goes to ask someone |
| 17:39 | <Philip`> | I can't imagine why anyone would parse the return values - those values have to have come from the program in the first place, and then the program can do its own thing to easily access the original data instead of adding a dozen lines with regexps and stuff to parse the values |
| 17:40 | <Philip`> | (except for opera-2dgame's getPixel which you do want to parse, but I think that's not relevant here) |
| 17:41 | <Philip`> | ((or at least I want to parse getPixel, so I can use it in the tests, and I guess other people might want to too)) |
| 17:42 | <MichaelMH> | yo, you know the little bump in the corner of the M is that my fault or the browsers? |
| 17:43 | <annevk> | as far as our internal usage goes it would be fine to change it |
| 17:43 | <annevk> | people would much prefer a four-value array |
| 17:44 | <Philip`> | MichaelMH: Do you mean in the bottom left corner? |
| 17:44 | <Philip`> | Looks like it might just be too close to the edge, so it gets cut off a bit |
| 17:46 | <MichaelMH> | top left one |
| 17:48 | <Philip`> | Do you mean the tiny (less than one pixel) bit sticking out the flat top in the top left? |
| 17:49 | <Philip`> | I think that's be because you have a square lineCap, so a little bit of that square sticks out in that corner where you start/end the path |
| 17:49 | <MichaelMH> | ic. |
| 17:49 | <MichaelMH> | I'm not fussed by it. I was just wondering |
| 17:50 | <MichaelMH> | and how can something be less than a pixel |
| 17:50 | <Philip`> | Antialiasing :-) |
| 17:50 | <MichaelMH> | um ic |
| 17:51 | <Philip`> | It's never drawn as solid black - it just adds some grey to the nearest pixel |
| 17:51 | <MichaelMH> | does it? |
| 17:51 | <Philip`> | Look in Opera and zoom in, and you can see the pixels moving between different shades of grey |
| 17:52 | <Philip`> | (By the way, I think your gradient doesn't work properly in Opera - radial gradients are implemented (and specced) very inconsistently) |
| 17:57 | <Philip`> | (http://canvex.lazyilluminati.com/misc/radial/examples.html) |
| 17:59 | <Philip`> | (At least it works consistently if the start circle has radius 0 and the same centre as the end circle and you don't try to draw anything outside the end circle. Otherwise it's a bit dodgy.) |
| 19:14 | <annevk> | awesome |
| 19:14 | <annevk> | I finally implemented entities |
| 19:14 | <Dashiva> | crongratulation |
| 19:15 | <jdandrea> | huzzah |
| 19:15 | <annevk> | it even handles funny stuff like: '"test":"&test;x"' |
| 19:15 | <annevk> | the result of that is that 16 x characters |
| 19:15 | <annevk> | (as 16 is the recursion limit at the moment, I think it can be a little higher) |
| 19:16 | <Lachy> | annevk, implemented in html5lib? |
| 19:16 | <annevk> | in xml5lib |
| 19:16 | <Lachy> | cool |
| 19:16 | <annevk> | which needs to cope with XML entities which are a tad more complicated than HTML entities |
| 19:17 | <Hixie> | thought you were dropping doctypes? |
| 19:17 | <annevk> | in the end implementing it took like 10 minutes, but I've been thinking about it for a long time |
| 19:17 | <annevk> | Hixie, for conformance I think; I'm not sure if we can drop them completely |
| 19:17 | Lachy | made some test cases http://lachy.id.au/dev/markup/tests/html5/autofocus/ |
| 19:18 | Lachy | found bug in Opera :-) |
| 19:18 | <annevk> | Hixie, just dropping them would be cool as it would safe us over 42 states in the tokenizer phase :) |
| 19:18 | <annevk> | (and those states even drop some of the things that are no longer relevant such as external references etc.) |
| 19:19 | <Hixie> | ah, you want XML5 to still be used even with content that uses doctypes? |
| 19:19 | <Hixie> | interesting |
| 19:19 | <Hixie> | i guess i don't really know what problem you're trying to solve |
| 19:19 | <Lachy> | there's a lot of XML on the web that uses internal subsets, so it's kind of requred |
| 19:20 | <Hixie> | but is that xml for which we want fallback behaviour? |
| 19:20 | <annevk> | Hixie, I would like to remove namespace well-formedness, but not require yet another parser |
| 19:20 | <Hixie> | for many uses, the draconian handling of xml is mostly the whole point |
| 19:20 | <Hixie> | (e.g. for anything involving financial transactions) |
| 19:20 | <Hixie> | "remove namespace well-formedness"? |
| 19:20 | <Lachy> | for RSS, draconian is bad |
| 19:21 | <Hixie> | xml 1.0 doesn't have namespace well-formedness |
| 19:21 | <Hixie> | and rss doesn't use doctypes and internal subsets |
| 19:21 | <annevk> | Hixie, for financial transations you want to do content validation |
| 19:21 | <annevk> | Hixie, well-formedness doesn't really matter |
| 19:21 | <annevk> | (given you have a deterministic parser) |
| 19:22 | <Hixie> | depends what you're trying to do |
| 19:22 | <annevk> | XML 1.0 doesn't have namespace well-formedness? |
| 19:22 | annevk | ponders |
| 19:22 | <Hixie> | xml 1.0 doesn't have namespaces. |
| 19:22 | <Hixie> | nor does xml 1.1 for that matter. |
| 19:22 | <Lachy> | I'm not so sure if liberal parsing would be good for real XHTML. The people who like using it, generally like it for the draconian error handling |
| 19:22 | <annevk> | oh, this would be a superset for XML 1.0, 1.1, Namespaces for XML 1.0, 1.1 and RFC3023 |
| 19:23 | <annevk> | and at the moment it's mostly a research project to see how much effort it takes |
| 19:23 | <Hixie> | Lachy: yeah, for xhtml the draconian error handling is half the point |
| 19:23 | <annevk> | so far, not much |
| 19:23 | <Hixie> | annevk: ah |
| 19:23 | <annevk> | XHTML is mostly about integrating with other XML dialects in my mind |
| 19:23 | annevk | doesn't really give much about the fussy parsing rules |
| 19:24 | <Lachy> | liberal parsing would be useful for CMSs that accept XHTML markup from users, so that it could clean it up on the back end before it gets sent to the end user |
| 19:25 | <Philip`> | Is someone going to fix JSON too? I assume most implementations have draconian parsing, but the RFC allows parsers to handle non-conforming input in whatever way they fancy |
| 19:25 | <Lachy> | ... and without subjecting users to complicated error messages |
| 19:25 | <Lachy> | RFC for JSON? |
| 19:25 | <Philip`> | Lachy: Shouldn't they use HTML for that? |
| 19:25 | <annevk> | there's an RFC, yes |
| 19:26 | <Philip`> | http://www.ietf.org/rfc/rfc4627.txt |
| 19:26 | <Hixie> | JSON is another example of where i don't see the value of error handling |
| 19:26 | <Hixie> | but anyway |
| 19:26 | Hixie | goes for lunch |
| 19:26 | <Lachy> | Philip`, it depends on their needs. I want a CMS that uses XML on the back end, and can serialise to HTML on the front |
| 19:30 | <Philip`> | (By the way, it's fun how the standard JS JSON parser lets malicious JSON data modify some variables when you parse it, e.g. with {a:a++} ) |
| 19:31 | <Philip`> | Lachy: Couldn't it accept HTML from users, then parse it and serialise as XML to store and process in the back end, then serialise to HTML again later? |
| 19:31 | <Lachy> | it could, but it depends on what the users want |
| 19:32 | <Philip`> | Oh, okay - I suppose if users want liberal XHTML parsing, then support for liberal XHTML parsing would be useful |
| 19:33 | <Lachy> | the problem with using html like that, is that things like this: <p>the is <b>bold<b> but this shouldn't be</p><p>this paragraph will be bold too</p> |
| 19:33 | <Lachy> | if that were to be parsed as HTML, it would be reserialised with many more <b> elements in all subsequent blocks of text, just becuase the user typed <b> instead of </b> |
| 19:34 | <Philip`> | Ah, that makes sense |
| 19:35 | <MichaelMH> | yo.. is canvas competeing with svg? |
| 19:35 | <Lachy> | no |
| 19:36 | <Lachy> | I'm sure there's some articles somewhere that explain what each are good for |
| 19:36 | <Philip`> | Only in a small number of cases |
| 19:36 | <Philip`> | (e.g. PlotKit uses both) |
| 19:37 | <MichaelMH> | Is there any point in knowing how to use both? |
| 19:37 | <MichaelMH> | oh ic |
| 19:37 | <Philip`> | (which isn't really competition but is a situation where they overlap) |
| 19:37 | <Lachy> | in some ways, SVG is better for graphs at the moment, becuase it can include text, whereas canvas needs to have HTML positioned over the top |
| 19:38 | <Philip`> | It's kind of like PNG vs JPEG - depending on what you want, one or the other or both could be useful |
| 19:38 | <Lachy> | there are even some cases where GIF is better than PNG (though, rarely) |
| 19:38 | <MichaelMH> | for what? file size? |
| 19:39 | <MichaelMH> | will text ever be supported in canvas? |
| 19:39 | <Lachy> | yeah, spacer.gif turns out to be much smaller than the equivalent spacer.png :-) |
| 19:39 | <Lachy> | MichaelMH, maybe |
| 19:39 | <Philip`> | It seems quite a few people want text |
| 19:39 | <MichaelMH> | if text was added would it be selectable? |
| 19:39 | <Lachy> | there have even been people hack support for text into it using what they have available, so there seems tob e some use cases |
| 19:40 | <Lachy> | probably not |
| 19:40 | <Lachy> | it would be like txt in a PNG |
| 19:40 | <MichaelMH> | ah ic. |
| 19:41 | Philip` | hacked in support for text by writing that part of his page with SVG instead |
| 19:41 | <MichaelMH> | whats your site phill? |
| 19:41 | <Philip`> | (Actually, I don't think I would have used canvas text anyway because I wanted control over the font) |
| 19:42 | <Philip`> | (unless canvas text let you download a font to use...) |
| 19:42 | <Philip`> | MichaelMH: http://canvex.lazyilluminati.com/ |
| 19:42 | <MichaelMH> | maybe it would be better just to posistion text over the canvas for things like graphs |
| 19:44 | <MichaelMH> | that game looks like it took quite a wee while |
| 19:45 | <MichaelMH> | is that proper 3D? or that "2.5D" stuff? |
| 19:46 | <Philip`> | http://forums.whatwg.org/viewtopic.php?p=138#138 has a suggestion of a forthcoming proposal for drawString, though I'm not sure how much trust should be put into Vlad's schedule estimates given the 3d canvas delays :-) |
| 19:46 | <Philip`> | It's 2.5D, like Duke Nukem 3D and slightly like Doom |
| 19:47 | <Philip`> | (because true 3D is impossibly slow) |
| 19:48 | <Philip`> | (at least without a true 3D canvas :-) ) |
| 19:50 | <Philip`> | http://canvex.lazyilluminati.com/misc/photos.html - true 3D, but it won't work unless you compile the web browser yourself |
| 19:50 | <MichaelMH> | is there gonna be a 3d canvas. I remember when reading the tutorial that theres only a 2d part now but 3d may come |
| 19:51 | <Philip`> | There's some experimental work by Mozilla and Opera, both (I believe) based on the OpenGL ES API, so hopefully that'll be worked on and standardised at some point in the future |
| 19:52 | <hasather> | MichaelMH: see http://my.opera.com/WebApplications/blog/show.dml/261474 |
| 19:52 | <MichaelMH> | that would be pretty damn cool. Cant see what it would be used for other than games tho |
| 19:52 | <Philip`> | (http://lxr.mozilla.org/mozilla/source/extensions/canvas3d/public/nsICanvasRenderingContextGLES11.idl is the kind of interface it provides) |
| 19:54 | <MichaelMH> | that looks so damn cool |
| 19:54 | <Philip`> | http://canvex.lazyilluminati.com/misc/giraffes.png - that (showing a stream of Flickr photos on a rotating plain) is arguably totally pointless, but at least it's not a game and it benefits from being inside a web browser |
| 19:54 | <Philip`> | *plane |
| 19:55 | <Philip`> | (since the browser provides web access and image downloads, and a user interface) |
| 19:56 | <Philip`> | (and I really wouldn't want to try writing that as a standalone C++ application) |
| 19:56 | <jgraham> | Philip`: So why does your markup analyser thing use .toxml() anyway? |
| 19:57 | <Philip`> | jgraham: So I can parse with html5lib once, save as XML, and then repeatedly re-parse the XML to do analysis stuff without it taking as long to parse each time |
| 19:58 | <MichaelMH> | you can have a music store site with a rip off of that album flick through thing in itunes too |
| 19:58 | <jgraham> | Philip`: could you satisfy that use case by using Pickles? |
| 20:00 | jgraham | is wondering if some setup involving python, html5lib and XPath would work |
| 20:00 | <Philip`> | jgraham: It sounds like that could work; but also I'm currently 4Suite's XPath to do the analysis, for no exceptionally good reason, and serialising/parsing through XML seems the easiest way to load the tree into 4Suite |
| 20:00 | <Philip`> | (ElementTree's XPath support is far too limited to be of much use) |
| 20:01 | <MichaelMH> | this could be potentially bad.. I don't wanna go to a website in the future for it to say "Sorry this website is for people with the latest graphics cards only, people go buy one here for £££" |
| 20:01 | <jgraham> | Yeah, I've just started looking at XPath modules for python. Maybe I'll see how easy it is to produce 4suite trees from html5lib |
| 20:02 | <Philip`> | http://www.oreillynet.com/onlamp/blog/2005/01/code_respecting_xpath_xml_pyth.html points out some of the modules |
| 20:02 | <jgraham> | Does http://cheeseshop.python.org/pypi/PDIS-XPath/0.3 sound like it would cover enough XPath to meet your needs? |
| 20:02 | <Philip`> | "pure-Python" makes me worry a little bit about performance :-( |
| 20:03 | <jgraham> | Presumably most of the perf issues will come from the speed of the underlying tree |
| 20:03 | <zcorpan> | someone should figure out how headers="" is implemented in commonly used screen readers |
| 20:04 | <Philip`> | Also it sounds like it doesn't support e.g. following-sibling, which I had been using to look for //*[p/following-sibling::table] |
| 20:04 | <jgraham> | OK that's a good enough reason to look at html5lib->4suite |
| 20:05 | <Philip`> | (given that page says it's limited to self/attribute/child axes, and apparently following-sibling is an axis, whatever that means) |
| 20:05 | jgraham | finds XPath surprisingly complex |
| 20:06 | <Philip`> | It sounds like libxml2 does XPath but the Python API is rubbish, in which case it wouldn't be great |
| 20:07 | <Philip`> | ...but on that oreillynet page, someone points out lxml.etree which might be nice |
| 20:09 | <Philip`> | (I don't really know anything, I've just been messing around with whatever has short enough examples that I can copy and paste :-p ) |
| 20:10 | <rubys> | q: (for Hixie or whomever) why is input/@size deprecated? |
| 20:11 | <Hixie> | same reason <table width> is obsolete |
| 20:14 | <rubys> | Is that reason documented somewhere? |
| 20:15 | <rubys> | After a quick scan, I don't see table width mentioned at all. |
| 20:18 | <zcorpan> | Hixie: as i said earlier in here, i think <input size> is a pragmatic way or saying what the expected input length is, without putting a restriction on the input length |
| 20:20 | <zcorpan> | Hixie: so i don't think <input size> should be deprecated/removed/discouraged |
| 20:20 | <Lachy> | I wouldn't mind size being included, it's sometimes easier to use than giving each control an id or class just to set it's size in the CSS |
| 20:20 | <rubys> | alternative to id or class would be a style attribute |
| 20:21 | <jgraham> | I don't mind deprecating size as long as we get the style attribute |
| 20:21 | <zcorpan> | Lachy: i don't see it being purely presentational, i see it as a hint of the expected input length |
| 20:21 | <Hixie> | rubys: no, i don't think the reasons are documented anywhere (other than the mailing list) -- if someone wants to write a design rationale page or set of pages on the wiki, i'd be more than happy to help them |
| 20:21 | <Lachy> | zcorpan, yeah |
| 20:21 | <jgraham> | zcorpan: What type of UA would make use of that feature? |
| 20:22 | <rubys> | i would prefer to keep both size and style. To me the primary benefit of WHATWG is accepting and documenting the web as it exists rather than trying to change it. |
| 20:22 | <Lachy> | jgraham, the information would be conveyed visually to the end user by the length or the control |
| 20:22 | <zcorpan> | jgraham: visual interactive comes to mind, but speech UAs might say "expected input length: 4 characters" or something |
| 20:22 | <Philip`> | jgraham: Links and Lynx use it |
| 20:22 | <Hixie> | rubys: certainly so far there has been a lot of emphasis on making the language better at the same time, and anything that reduces media-dependent coding is imho a good thing |
| 20:23 | <Hixie> | size="" and style="" are both very media-specific |
| 20:23 | <Hixie> | an <input> element might want one size on a phone and another on the desktop, and media-specific css is where that distinction should be |
| 20:23 | <Hixie> | the markup itself, imho, shouldn't try to dictate the presentation |
| 20:23 | <Lachy> | size is the textbox equivalent to rows/cols in textarea. |
| 20:24 | <jgraham> | Philip`: Fair enough. zcorpan: In a visual graphical UA that supports CSS it has no big advantage over style and the disadvantage that the units aren't specified |
| 20:24 | <zcorpan> | Hixie: you don't think size="" can be considered a hint of the expected input length? |
| 20:24 | <jgraham> | Do speech browsers use it? |
| 20:24 | <zcorpan> | jgraham: i don't follow about the units part |
| 20:25 | <zcorpan> | jgraham: don't know if they use it, but they could use it |
| 20:25 | <jgraham> | What are the units of size? |
| 20:25 | <zcorpan> | characters |
| 20:25 | <jgraham> | How wide is a character? |
| 20:25 | <Philip`> | That's a reason to specify it, rather than to remove it |
| 20:26 | <jgraham> | Well I agree it should be specified but CSS gives you multiple choices for units |
| 20:26 | <zcorpan> | jgraham: dunno, a graphical UA would probably make it wide enough so that one character fits nicely |
| 20:26 | <zcorpan> | jgraham: or reverse engineer what IE does |
| 20:26 | <rubys> | zcorpan: good point. |
| 20:26 | <jgraham> | So one character == The width of a textbox with <input size="1"> in IE ;) |
| 20:26 | <zcorpan> | jgraham: if you want a width for presentational purposes then sure use css, i'm talking about useful hints to the user |
| 20:27 | <zcorpan> | jgraham: for the purposes of determinating how wide <input>s with a size attribute should be in graphical UAs, yes |
| 20:27 | <jgraham> | zcorpan: I'm not sure I come across that many textboxes where I want a hint of the expected length but the input doesn't fit some fixed pattern |
| 20:28 | <jgraham> | Also, the graphical size has to be well defined for rendering interop |
| 20:28 | <jgraham> | Er... you just said that. Ignore me :) |
| 20:29 | <zcorpan> | jgraham: here's one example: http://ln.hixie.ch/ |
| 20:29 | rubys | notes that input/@size is present on both google.com and ln.hixie.ch |
| 20:31 | <zcorpan> | rubys: google.com should probably use type="search" instead ;) and css |
| 20:34 | <Hixie> | zcorpan: i don't see the use case for a hint of the expected input length. what's the problem we're trying to solve? |
| 20:34 | <Hixie> | Lachy: cols actually matters, since it sets the wrap width for submission wrapping |
| 20:35 | <rubys> | In my opinion, the only way to make the web "better" is to get browser vendors to agree to no longer implement a feature, simply documenting it as deprecated or getting a conformance checker to flag it will have little benefit. |
| 20:36 | <rubys> | Not documenting the behavior will leave the status quo: vendors will reverse engineer each others behavior. |
| 20:36 | Hixie | better get cracking on putting <frameset>, <font>, <wbr>, and friends, back into html5 then |
| 20:36 | <Hixie> | documenting != part of the language |
| 20:36 | <Hixie> | e.g. the behaviour for <i><b></i></b> is now documented, but it's still non-compliant. |
| 20:36 | <Lachy> | has <font> been removed? |
| 20:37 | <Lachy> | ah, not yet |
| 20:37 | <Hixie> | Lachy: right now it's only allowed for wysiwyg editors. but that's not a stable equilibrium |
| 20:37 | <Hixie> | i'm thinking we should drop it and put style="" everywhere, i just want to find a way to do that that doesn't make pages full of <div>s with style="" conformant. |
| 20:37 | <rubys> | documented but non-compliant is a very VERY subtle distinction, and won't likely have much of an affect on the web. |
| 20:38 | <Lachy> | rubys, by that argument, we should just make everything conformant |
| 20:38 | <jgraham> | rubys: Depends on how you document it... <plaintext> is documented but non-compliant and most people don't know it even exists |
| 20:38 | <Lachy> | that would do more harm than good |
| 20:39 | <Philip`> | Even if something isn't documented in the spec, it will be documented in tutorials and examples and existing content that people copy from, so undocumenting may not have much effect on the web either |
| 20:39 | <Lachy> | at least documenting in the spec will improve interop |
| 20:40 | <rubys> | I would be in favor of marking as non-conformant things that actively are known to cause problems. <plaintext> *MIGHT* be in that category, as would nested <b> elements (the one case where <i><b></i></b>actually causes unexpected results). |
| 20:41 | <rubys> | but declaring things as non-conformant that are widely interoperable and widely used merely causes people to get annoyed and will inhibit adoption. |
| 20:41 | <zcorpan> | Hixie: the use-case is that the user can easier fill in a form if he knows approximately how much each text field expects |
| 20:42 | <Lachy> | zcorpan, that use case is already solved with CSS |
| 20:42 | <Hixie> | rubys: HTML4 already made <font> and <frameset> non-compliant ("deprecated" as they called it) while documenting it -- for authors, even, not implementors |
| 20:42 | <Hixie> | rubys: how is this different? |
| 20:42 | <Philip`> | I believe the plan is for everything to be handled the same way by new browsers (by specifying and testing and fixing), in which case nothing would be left that causes problems, and then nothing would be non-conformant |
| 20:42 | <zcorpan> | Lachy: but size="" could well be exposed in aural UAs too |
| 20:43 | <rubys> | XHTML2 went further and marked a number of elements as non-conformant, but do we (really* want to continue down that path? |
| 20:43 | <Lachy> | rubys, look at the recent argument on public-html about <b> and <i>. Can you imagine what would happen if we allowed even more presentational stuff? |
| 20:43 | <Lachy> | zcorpan, I'd be tempted to believe that if that's what they do already |
| 20:43 | <rubys> | Lachy: it is *exactly* that discussion which spawned this question. |
| 20:43 | <Lachy> | but, otherwise, it's just a hypothetical use case |
| 20:43 | <zcorpan> | Lachy: true |
| 20:44 | <rubys> | "Let's pick and chose where we want to be picky and choosy" isn't a defensible strategy. |
| 20:44 | <Lachy> | rubys, why would a discussion with people abusing us for making HTML5 a presentational language, give you the idea for adding more presentational stuff? |
| 20:45 | <Lachy> | I don't think we're being picky and choosy just where we want to be. We're including features that have actual use cases |
| 20:45 | <Lachy> | (though, I'm not totally convinced by the use case for <small>) |
| 20:46 | <rubys> | Either they are right (in which case, lets get rid of <b> and <i>) or they are wrong (in which case, let's keep input/size), but abusing the people who are asking this question (it goes both ways, after all) merely because they came up with a different balance than HTML5 isn't right either. |
| 20:46 | <Hixie> | there's a mindset problem here |
| 20:46 | <Hixie> | the whatwg isn't starting from html4 and deciding what should stay and what shouldn't |
| 20:46 | <rubys> | If it is in use on google.com's front page, no amount of specs or conformance checkers will convince browser vendors otherwise. |
| 20:47 | <Hixie> | from the start we've had a blank slate, and we're designing the language based on use cases and requirements |
| 20:47 | <Hixie> | "it's in html4" is not an argument |
| 20:47 | <Hixie> | rubys: the use of size="" on google.com's home page is far from the greatest standards compliance problem on a google site. |
| 20:47 | <rubys> | use case: a browser vendor would like to display the page found at http://google.com/. |
| 20:47 | <Lachy> | google uses a lot of old-style coding, just like a lot of other sites. I don't see how their use of size is particularly relevant |
| 20:48 | <jgraham> | I believe <i> and <b> have convincing use cases. |
| 20:48 | <Hixie> | that's a use case for specifying its behaviour, which we will do |
| 20:48 | <Hixie> | jgraham: and they're in the spec |
| 20:48 | <jgraham> | I think @size has a semi-convincing use case |
| 20:48 | <Hixie> | semi-convincing isn't good enough |
| 20:48 | <jgraham> | Hixie: I know. |
| 20:48 | <Hixie> | :-) |
| 20:48 | <jgraham> | Hixie: That's basically my point |
| 20:48 | <othermaciej> | size attribute on what? |
| 20:49 | <Lachy> | <input size=""> |
| 20:49 | <jgraham> | If @size is to be included it should have a convincing use case. If there are lots of forms where people need a hint on the length of an input that's a convincing use case |
| 20:49 | <jgraham> | (to me) |
| 20:49 | <jgraham> | But I don't think that is the case |
| 21:06 | <jgraham> | Gah. lxml.etree doesn't seem to quite work as a drop-in ElementTree replacement :( |
| 21:21 | <graouts> | hi |
| 21:21 | <graouts> | anyone out here knows what event is fired while the knob of an <input type="range"> is being dragged around? |
| 21:25 | <Hixie> | graouts: input, in theory |
| 21:26 | <graouts> | right, thanks |
| 22:27 | <Philip`> | http://erik.eae.net/archives/2007/05/04/18.42.16/ - ooh, a new ExCanvas |
| 22:37 | <Hixie> | this is a funny comment |
| 22:37 | <Hixie> | http://news.com.com/5208-1045_3-0.html?forumID=1&threadID=24527&messageID=232071&start=0 |
| 22:38 | <jgraham_> | My cluelessness meter just exploded ;) |
| 22:41 | jgraham_ | wonders how to fake doctypes and document elements in lxml |
| 23:27 | <jgraham_> | Philip`: So I have lxml working with html5lib. It's not pretty but it works |
| 23:33 | <zcorpan> | jgraham_: what is lxml? |
| 23:34 | <jgraham_> | lxml == python bindings for libxml2 |
| 23:34 | <zcorpan> | ah |
| 23:34 | <jgraham_> | It has a full(?) XPath implementation, which is nice |
| 23:35 | <zcorpan> | ok |
| 23:38 | <Hixie> | yay interoperability |
| 23:38 | <Hixie> | http://www.hixie.ch/tests/adhoc/html/canvas/021.html |
| 23:41 | <Philip`> | Looks like Firefox (2+3) and Opera (9.20) and Safari (2.0.4) all match on the left one, which surely counts as interoperability and just means the spec is wrong :-) |
| 23:42 | <Hixie> | i get one behaviour for opera and safari2, one for firefox 2 and 3, and one for safari trunk |
| 23:44 | <zcorpan> | so... which features in html5 can be considered ok for authors to use today? <canvas> is an obvious one, and various things in WF2 (in both cases possibly using a scripted fallback for ie)... perhaps getElementsByClassName with a prototype fallback for legacy UAs... anything other than that? |
| 23:45 | <Hixie> | depends what your criteria is |
| 23:45 | <zcorpan> | i will explain which features in html5 can be used today in the real world in my presentation the 23rd |
| 23:45 | <zcorpan> | and how |
| 23:47 | <Hixie> | well, things like contenteditable, designmode, drag and drop, are implemented in IE already |
| 23:48 | <zcorpan> | ah. yep. |
| 23:48 | zcorpan | makes notes |
| 23:48 | <othermaciej> | some of the elements have no API and their likely default presentation could be done solely with a stylesheet |
| 23:48 | <Hixie> | depends what you mean by usable, really |
| 23:48 | <othermaciej> | so you could use those depending on your standards |
| 23:49 | <Hixie> | more interop fun with canvas patterns: http://www.hixie.ch/tests/adhoc/html/canvas/023.html |
| 23:49 | <zcorpan> | usable as in using a new feature + whatever fallback is needed to make it degrade ok or have the same functionality in legacy UAs is simpler than current practices for solving the same problem |
| 23:50 | <Hixie> | ok, depends what you mean by "new" :-) |
| 23:50 | <zcorpan> | new as in isn't widely used by authors |
| 23:51 | <zcorpan> | e.g. i wouldn't be talking about XHR or contenteditable |
| 23:51 | <zcorpan> | but i would be talking about <canvas> |
| 23:51 | <Hixie> | ah |
| 23:52 | <zcorpan> | at first i was thinking about talking about everything that is listed in http://wiki.whatwg.org/wiki/Implementations_in_Web_browsers |
| 23:53 | <zcorpan> | but then i realised that e.g. ping="" is pretty useless since ping="" + fallback is more complicated than the current practice of HTTP redirect or just JS |
| 23:54 | <zcorpan> | and firefox doesn't have a nice UI for it yet (i think) |
| 23:54 | <Hixie> | ping="" will only become useful once widely supported, if you actually need the data you'd get from it, yes |
| 23:54 | <othermaciej> | ping would only be useful today if you were ok with no ping as the fallback |
| 23:54 | <Hixie> | right |
| 23:55 | <zcorpan> | exactly |
| 23:55 | <zcorpan> | so that's something i won't be talking about |
| 23:57 | <zcorpan> | not sure if i should explain how the repetition model works since there were discussions about redesigning it from scratch |
| 23:57 | <Hixie> | it's been redesigned. the design sits on my whiteboard as we speak. :-) |
| 23:57 | <zcorpan> | cool :) |
| 23:57 | <Dashiva> | Is it better than before? ;) |
| 23:58 | <Hixie> | yeah |
| 23:58 | <Hixie> | it's close to xul templates actually |
| 23:58 | <Hixie> | if you know those |
| 23:58 | <Hixie> | except without the rdf |
| 23:58 | <Hixie> | and with much less markup |
| 23:58 | <Hixie> | doesn't have good fallback compared to the wf2 repetition model though |
| 23:59 | <Hixie> | though i guess the wf2 repetition model fallback was somewhat academic given that it didn't work in IE |
| 23:59 | <Dashiva> | Yeah, for the more complex features it can be better to start fresh |
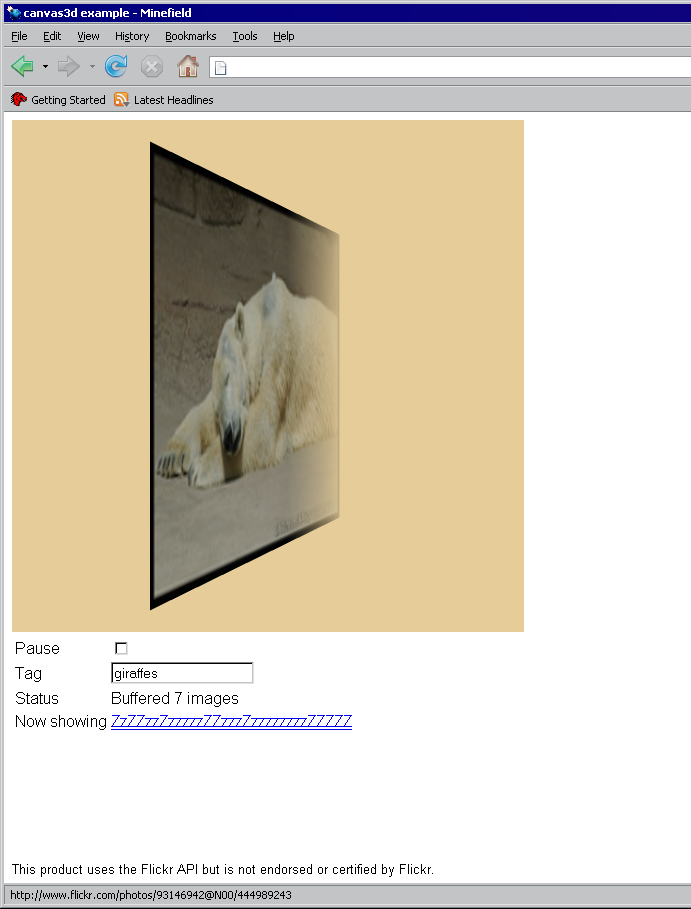{kind=link}