| 01:51 | <Philip`> | Does http://canvex.lazyilluminati.com/misc/imagedata.html crash Opera 9.5? (I can only test via Opera Mini, which just says "Internal server error", which sounds potentially worrying but not very informative) |
| 01:54 | <othermaciej> | does Opera Mini handle events? |
| 01:55 | <othermaciej> | and scripting? |
| 01:56 | <Philip`> | It seems to, as long as you don't use setInterval and don't expect it to wait for distant timeouts |
| 01:57 | <Philip`> | (i.e. it can handle scripting and events and stuff while the page is loading, for some definition of 'loading' that I haven't quite worked out, though then it justs sends a static copy to your phone) |
| 01:57 | <Philip`> | *just |
| 01:59 | <othermaciej> | so script runs at load time but not afterwards? |
| 02:00 | <Philip`> | Yes (as far as I can tell) |
| 02:01 | <othermaciej> | (I'm playing with the Opera Mini simulator) |
| 02:01 | <Philip`> | (since it basically opens the page in Opera on their servers, then at some point it decides it's got enough and transmits a non-interactive compressed snapshot, I think) |
| 02:01 | <Philip`> | (Me too, since my real phone is far too rubbish :-) ) |
| 02:03 | <Philip`> | I got it to run ~100 canvas tests in iframes on a single page, and that (eventually) worked correctly with all the scripting and loading and stuff, but it wouldn't let me correctly press the buttons to submit the test results, so I had to do that via a hard-coded timer :-( |
| 05:11 | <mpt> | "For example, don’t put a 100 x 100 image in a 10 x 10 <image> element." -- unintentionally hilarious iPhone developer docs |
| 05:21 | <mpt> | Ah, interesting: "ensure that width * height * 4 < 8 MB" ... so apparently this <image> element is for some new kind of file that has widths and heights measured in MBm⁻². |
| 05:29 | <mpt> | But hooray for this: "Don’t use JavaScript movie controls to play video on iPhone. iPhone supplies its own controls." |
| 07:51 | <om_out> | mpt: width * height * 4 bytes |
| 07:59 | <hsivonen> | Hixie: http://www.w3.org/mid/A0F10D3A-A679-4BB1-8844-684FBFDB94F6⊙if is there a way for the stack have td or th in such a position that generating implied end tags could close the scope (except for the EOF case)? |
| 08:16 | <annevk> | hehe, iPhone docs promote <image> :) |
| 08:16 | <hsivonen> | annevk: URL? |
| 08:16 | <annevk> | http://developer.apple.com/iphone/designingcontent.html |
| 08:17 | <annevk> | click on "Use Standards and Tried-and-True Design Practices" and then search |
| 08:19 | <othermaciej> | I'll report a bug |
| 08:23 | <hsivonen> | annevk: did you try to optimize redundant steps in tree building at all or did you just follow the spec to letter even if it asked you to traverse the stack more than absolutely necessary? |
| 08:24 | <annevk> | there are some small optimizations |
| 08:24 | <annevk> | but not much |
| 08:24 | <annevk> | doesn't really matter a lot in Python I've the feeling |
| 08:25 | <annevk> | well, in the beginning we tried to reduce function calls by using dictionaries instead of token objects and such and that worked pretty well |
| 08:25 | <hsivonen> | annevk: what's your take on the the ability of "generate end tags" to close the scope? |
| 08:25 | <annevk> | but now with the treebuilder abstraction we gained a lot of function calls again :( |
| 08:26 | <annevk> | http://html5lib.googlecode.com/svn/trunk/python/src/html5lib/treebuilders/_base.py search for "generateImpliedEndTags" |
| 08:27 | <annevk> | although I now see it has some XXX comment that we never hit apparently... |
| 08:27 | <hsivonen> | annevk: I was thinking of doing the exact same thing: just popping |
| 08:27 | <hsivonen> | I guess I have to send another email |
| 08:28 | <annevk> | Hixie recently added a bunch of table elements there |
| 08:28 | <annevk> | I'm not sure what that was about |
| 08:29 | <hsivonen> | annevk: I think that was about EOF |
| 08:29 | <hsivonen> | I am not sure that it is a good idea to put them in that part of the spec |
| 08:29 | <hsivonen> | annevk: does Python turn tail recursion into looping? |
| 08:30 | <annevk> | dunno |
| 08:30 | <annevk> | http://html5.org/tools/web-apps-tracker?from=964&to=965 |
| 08:31 | <annevk> | is that for <table><tbody><tr><td><p><tbody> or something? |
| 08:32 | <annevk> | doesn't seem like it, that already works |
| 08:33 | <hsivonen> | the only case where I see those mattering is the EOF case |
| 08:33 | <annevk> | example markup? |
| 08:34 | annevk | reads http://en.wikipedia.org/wiki/Tail_recursion and understands we might be able to optimize stuff a bit |
| 08:36 | <annevk> | hmm, seems only to matter if it calls itself a lot |
| 08:38 | <annevk> | hsivonen, I don't see how it matters for EOF either |
| 08:38 | <annevk> | hsivonen, you always get a single error and that can't be avoided, because </table> is never implied |
| 08:39 | <hsivonen> | annevk: good point. will you send email or shall I? |
| 08:40 | <annevk> | you're already going pretty good with your review, you do it ;) |
| 08:41 | <hsivonen> | annevk: ok |
| 08:45 | <met_> | http://www.bluishcoder.co.nz/2007/07/patch-for-video-element-support-in.html |
| 08:47 | <Hixie> | hsivonen: i don't know (re <td>s) |
| 08:48 | <hsivonen> | Hixie: that doesn't sound good ;-) |
| 08:49 | <Hixie> | the table elements were added because it seemed wrong that they not be on the list |
| 08:49 | <Hixie> | i honestly don't know if they'll ever get hit |
| 08:49 | <Hixie> | i want to say no |
| 08:49 | <Hixie> | but i'm not sure how to prove it |
| 08:50 | <Hixie> | i'll be back in about 12 hours |
| 08:50 | <Hixie> | (and possibly briefly in a few minutes) |
| 08:50 | <hsivonen> | Hixie: I'd prefer to pretend that we proved that they never get hit |
| 08:52 | <annevk> | <tbody> gets ignored outside <table>, inside <table> it is handled explicitly in each table phase |
| 08:52 | <annevk> | I wonder if the same goes for <td> and <tr> |
| 08:53 | <annevk> | I'm pretty sure they never get hit either |
| 08:53 | <annevk> | lets test that with the tests we got... |
| 08:54 | <hsivonen> | annevk: tr, td and th start tags are ignored "in body" |
| 08:54 | <annevk> | indeed |
| 08:54 | <annevk> | if I remove "td", "th", "tr" from our generate implied end tags algorithm nothing goes wrong |
| 08:55 | <annevk> | because the table phases already deal with them |
| 08:55 | <hsivonen> | annevk: the end tags seem to fall under "An end tag token not covered by the previous entries", but that seems wrong |
| 08:55 | <annevk> | only "dd", "dt", "li", "p" are important |
| 08:55 | <annevk> | actually, if I remove "p" nothing fails either... |
| 08:55 | annevk | ponders |
| 08:56 | <hsivonen> | annevk: removing p seem wrong |
| 08:56 | <hsivonen> | hmm. perhaps the An end tag token not covered by the previous entries |
| 08:56 | <hsivonen> | still does the right thing "in body" for cell ends |
| 08:56 | <annevk> | ah, the problem is that we don't count errors I suppose |
| 08:57 | <annevk> | as removing <li> also "works" |
| 08:57 | <annevk> | they are catched by the alternative algorithm that generates parse errors and therefore still generate the same tree... |
| 08:58 | <hsivonen> | IIRC, in fragment cases some "act as if" consistently produce 0 or 2 errors. I think I may have changed some of those to emit 0 or 1 errors |
| 09:20 | <annevk> | how does "If the stack of open elements has a p element in scope, then generate implied end tags, except for p elements." even make sense? |
| 09:20 | <annevk> | it says that when you encounter </p> |
| 09:21 | <annevk> | however, you will never generate an implied end tag for <dd>, <dt> or <li> or any o the table cells as they can never be between the <p> that is in scope and the current node |
| 09:29 | <annevk> | innerHTML wouldn't change anything for that either |
| 09:40 | <hsivonen> | annevk: excellent point |
| 09:41 | <hsivonen> | annevk: I'll email again. |
| 10:00 | <hsivonen> | should the list of active formatting elements be implemented as an array or as a linked list? |
| 10:01 | <hsivonen> | is it searched much more often than a node is removed from the middle? |
| 10:05 | <hsivonen> | Hixie: was you stat for "invocations of the AAA" exactly this? (that is, is the answer array?) |
| 10:06 | <hsivonen> | oh that counted cloning nodes |
| 10:06 | <hsivonen> | Hixie: did you count changing the size of the list by deleting stuff in the middle? |
| 10:12 | <hsivonen> | annevk: does the algorithm for "in body" "An end tag token not covered by the previous entries" make sense to you? |
| 10:12 | <hsivonen> | step 2.3. makes no sense to me |
| 10:14 | <annevk> | what's 2.3? |
| 10:14 | <hsivonen> | Pop all the nodes from the current node up to node, including node, then stop this algorithm. |
| 10:15 | <hsivonen> | First: Initialise node to be the current node (the bottommost node of the stack). |
| 10:15 | <hsivonen> | ok makes sense |
| 10:15 | <hsivonen> | # |
| 10:15 | <hsivonen> | If node has the same tag name as the end tag token, then: |
| 10:15 | <hsivonen> | # |
| 10:15 | <hsivonen> | Generate implied end tags. |
| 10:15 | <hsivonen> | ok, makes sense |
| 10:15 | <hsivonen> | now Pop all the nodes from the current node up to node, including node, then stop this algorithm. |
| 10:15 | <annevk> | oh, I was looking at the wrong algorithm duh |
| 10:16 | <hsivonen> | how could /node/ not already be popped or be the current node? |
| 10:16 | <hsivonen> | shouldn't that be a simple unconditional pop |
| 10:17 | <hsivonen> | umm. not unconditional but pop if the current node is /node/ |
| 10:17 | <annevk> | <foo><bar><baz></foo> |
| 10:18 | <annevk> | would pop <baz> and <bar> and <foo> |
| 10:18 | <hsivonen> | annevk: sorry for being dense, but I don't understand what step 2.3. has to do with it |
| 10:19 | <hsivonen> | annevk: isn't step 4. what causes that? |
| 10:19 | <hsivonen> | actually, step 2.1. makes no sense to me, either |
| 10:19 | <annevk> | indeed |
| 10:20 | <annevk> | I wonder how we managed to implement it :) |
| 10:21 | <hsivonen> | time to send mail again |
| 10:21 | <annevk> | we implemented what was mentioned |
| 10:22 | <annevk> | which doesn't make much sense :( |
| 10:22 | <zcorpan_> | can you provide a markup snippet that highlights the difference? |
| 10:23 | <hsivonen> | zcorpan_: the difference? |
| 10:23 | <annevk> | <foo>...</foo> is the only case that 2.1 covers |
| 10:23 | <annevk> | in which case you don't need to generate implied end tags etc. |
| 10:23 | <annevk> | you just need to pop |
| 10:23 | <zcorpan_> | ah |
| 10:23 | <zcorpan_> | indeed |
| 10:23 | <hsivonen> | lunch |
| 10:23 | <hsivonen> | then email |
| 10:53 | <annevk> | I think I'm done with public-html for the day |
| 11:03 | <hsivonen> | annevk: did you my email about the catch-all end tag case, though? did it make sense? |
| 11:12 | <annevk> | yes |
| 11:15 | <hsivonen> | ok. thanks. |
| 11:35 | <annevk> | having said that, I'm not sure the algorithm is correct |
| 11:35 | <annevk> | oh wait |
| 11:36 | <annevk> | hsivonen, it does make sense |
| 11:36 | annevk | just realized |
| 11:36 | <annevk> | hsivonen, because of step 5 |
| 11:36 | <annevk> | hsivonen, and step 4 |
| 11:36 | <annevk> | hsivonen, they change "node" |
| 11:37 | <annevk> | so say you have <dialog><dd></dialog> |
| 11:37 | <annevk> | you get to 4 |
| 11:38 | <annevk> | node becomes <dialog> |
| 11:38 | <annevk> | </dd> is implied |
| 11:38 | <annevk> | done |
| 11:38 | <annevk> | however, it's questionable whether this is correct given that current UAs don't generate implied end tags in those cases... |
| 11:42 | <hsivonen> | annevk: well, this certainly looks like something that needs another look by Hixie |
| 11:45 | <annevk> | it seems that for <foo> </foo> it doesn't make much sense |
| 11:46 | <annevk> | well, it seems that you can optimize for <foo> </foo> |
| 11:46 | <annevk> | it does make sense in a twisted way |
| 11:48 | <hsivonen> | annevk: looks like you aren't done for the day after all :-/ |
| 12:04 | <hsivonen> | I'd like to try to avoid ad hominems, but I'm intrigued that the insistence on a small improvement with great cost comes from an economist |
| 12:17 | <annevk> | that discussion is just painful |
| 12:27 | <zcorpan_> | authors provide fallback to <object>? |
| 12:28 | zcorpan_ | won't join that discussion |
| 12:33 | <annevk> | hsivonen, yeah :-/ |
| 12:33 | <annevk> | these people should join some browser development project and learn about the web a little bit |
| 12:46 | <zcorpan_> | annevk: did you check in the parser-tests thing somewhere? |
| 12:48 | <annevk> | not yet |
| 12:48 | annevk | was fixing html5lib |
| 12:48 | <zcorpan_> | ok |
| 12:48 | <annevk> | you want it checked in somewhere? |
| 12:49 | <zcorpan_> | would be nice, in case i feel like improving it |
| 12:50 | <zcorpan_> | no rush though |
| 12:54 | <annevk> | it's in the html5 project now |
| 12:54 | <annevk> | including a README that says to modify the tests from html5lib, not the ones included |
| 12:54 | <annevk> | karlUshi, seen http://html5.org/parsing-tests/testrunner.htm already? |
| 12:54 | <annevk> | karlUshi, you might like it |
| 12:55 | Philip` | wonders if anyone really cares what input like � gets parsed into |
| 12:56 | <annevk> | FFFD |
| 12:56 | <annevk> | U+FFFD |
| 12:56 | <Philip`> | Is it worth having tests for that kind of thing? (Or are there ones already?) |
| 12:56 | <Philip`> | (Firefox gets it wrong and says "F") |
| 12:57 | <Lachy> | I wonder why it does that |
| 12:57 | <annevk> | maybe a limit |
| 12:57 | <Philip`> | (and so does my non-serious not-really-implemented tokeniser) |
| 12:57 | <annevk> | we have tokenizer tests |
| 12:58 | <Philip`> | Probably by doing "int n; ... n = n*10 + (next_char - '0')" or something and not caring about overflow |
| 12:58 | <Lachy> | looks like it's a limit of 1 0000 0000 base 16 |
| 12:58 | <annevk> | Opera and IE get it right |
| 12:59 | <Philip`> | FF also parses � into #4294967295; |
| 13:00 | <annevk> | oops |
| 13:00 | Philip` | doesn't expect this is a likely place for real-world interoperability concerns |
| 13:00 | <annevk> | I suppose that explains how much time reverse engineering costs and that it isn't really worth checking what other browsers do all the time |
| 13:01 | <hsivonen> | if there's anything long about longdesc, it is the email threads |
| 13:01 | <annevk> | :p |
| 13:02 | <hsivonen> | Philip`: that's why you should have an integer overflow guard in your loop that consumes NCRs |
| 13:02 | hsivonen | has one |
| 13:02 | <Philip`> | I just have a TODO comment stuck in there :-) |
| 13:02 | <Philip`> | and I have another similar comment telling me to implement the non-numeric entity things too |
| 13:02 | <hsivonen> | Philip`: which programming language? |
| 13:03 | <hsivonen> | Philip`: Ocaml? |
| 13:03 | <Philip`> | but I'm not particularly interested in making things actually work at the moment |
| 13:03 | <Philip`> | OCaml generating C++ |
| 13:03 | <hsivonen> | cool |
| 13:03 | <Philip`> | (Also OCaml generating .dot files so I can make nice graphs of the tokeniser state transitions) |
| 13:03 | <annevk> | we solved it by having a try statement around the string to int conversion |
| 13:04 | <hsivonen> | if (value < 0) { |
| 13:04 | <hsivonen> | value = 0x110000; // Value above Unicode range but within int |
| 13:04 | <hsivonen> | // range |
| 13:04 | <hsivonen> | } |
| 13:05 | Philip` | just wants to see what's possible when you have the tokeniser algorithm as a data structure that you can process, instead of being English text or unprocessable program code |
| 13:05 | <hsivonen> | (value is signed) |
| 13:10 | <annevk> | Philip`, will you consider implementing all the other fancy stuff as well? |
| 13:10 | <annevk> | or just tokenizing? |
| 13:14 | <Philip`> | That depends on how impossible the rest of it looks :-) |
| 13:15 | <annevk> | by the time Hixie addresses hsivonen's comments nobody will have to think about it anymore :p |
| 13:15 | <Philip`> | The tokeniser is fairly straightforward, since you can just represent the whole thing as a dozen state variables and some functions that match certain states and have transitions into new states |
| 13:15 | <annevk> | now I think of it, that might make it too boring for some! |
| 13:16 | <Philip`> | (The tree construction looks more complex than that, though I haven't looked at it in any detail) |
| 13:16 | <annevk> | tree construction is actually similar |
| 13:16 | <annevk> | although currently it has this concept called insertion mode which makes it look more complicated |
| 13:16 | <annevk> | you can actually implement it as a bunch of states as well |
| 13:17 | <annevk> | the difference being that you have some other set of variables and pass tokens around instead of characters |
| 13:18 | <Philip`> | Would I be right in thinking the only way the content model flag can change outside the tokeniser is when explicitly emitting a start tag? |
| 13:19 | <annevk> | yeah |
| 13:19 | <annevk> | hsivonen, removing "td", "th" and "tr" from generate implied end tags does indeed not give any parse error differences |
| 13:20 | <annevk> | hsivonen, removing "p", however, gives 45 |
| 13:21 | <hsivonen> | Philip`: it's just that start tags "in body" have a lot of stuff to type |
| 13:22 | annevk | is amazed at Robert's ability to not understand |
| 13:28 | Philip` | reaches the bogus comment state, and finds that it totally doesn't match his way of writing the algorithm |
| 13:29 | <annevk> | markup open declaration did? |
| 13:30 | <annevk> | you should be able to implement those as functions I guess; separate from the states |
| 13:30 | <Philip`> | The problem is that it sounds like it needs to look backwards and know what happened before that state was reached |
| 13:31 | <Philip`> | The markup declaration open state is just after the bogus comment state, so I haven't got that far yet :-) |
| 13:33 | <annevk> | don't you have a character queue or something? |
| 13:34 | <annevk> | then you just make sure the right chars are on the stack before switching to the state |
| 13:36 | <hsivonen> | Philip`: you may find my impl useful to look at |
| 13:41 | <annevk> | zcorpan_, in case you missed it: http://html5.googlecode.com/svn/trunk/parser-tests/ |
| 13:44 | <zcorpan_> | annevk: saw it, cheers |
| 13:45 | <Philip`> | Oh, I think my confusion comes from e.g. "<?" transitioning to the bogus comment state after consuming the '?', whereas "<!x" transitions before consuming the 'x', and the BCS can't tell the difference |
| 13:46 | <annevk> | doesn't it say "unconsume" somewhere? |
| 13:48 | <Philip`> | Not that I can see |
| 13:48 | <Philip`> | but I can work around it by just moving the consumption around to the right places |
| 13:50 | <hsivonen> | Philip`: I think Hixie cut corners when writing the spec. I had a bug there that the unit tests revealed |
| 13:50 | <hsivonen> | Philip`: basically, you need to start filling the bogus comment buffer before you make the actual state transition |
| 13:53 | <Philip`> | "(If the comment was started by the end of the file (EOF), the token is empty.)" - isn't it also empty if the comment was started by a > character? |
| 13:54 | <Philip`> | Hmm, I'll wait until later to sort out the details and make it actually work properly and pass the tests :-) |
| 13:54 | <Philip`> | (since the current implementation is totally not executable, which makes it hard to test) |
| 14:04 | <annevk> | Philip`, yeah, then it's also empty |
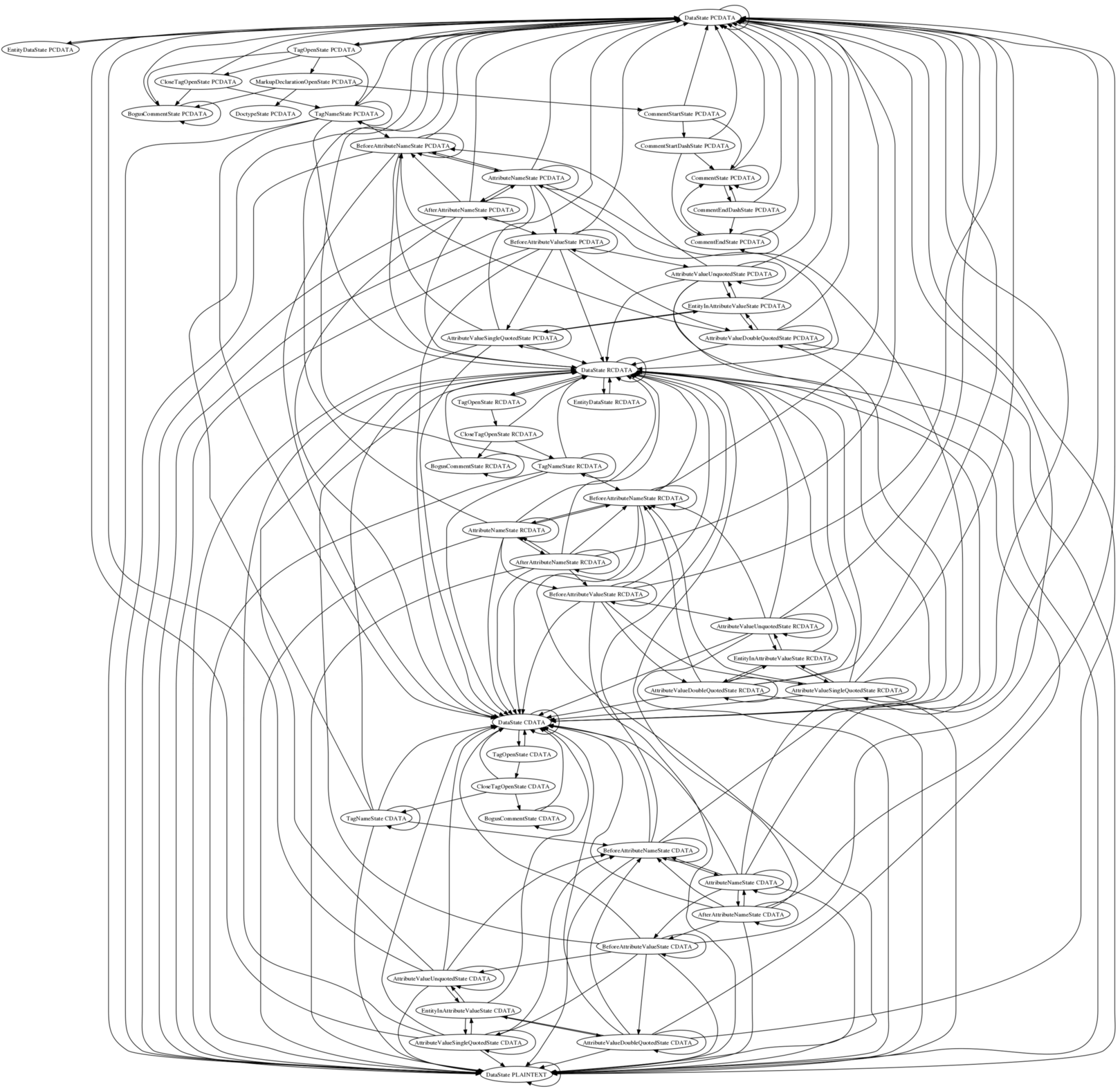
| 14:21 | <Philip`> | http://canvex.lazyilluminati.com/misc/states.png - incomplete and quite possibly with bugs, but it looks kind of interesting |
| 14:26 | Philip` | should probably skip all the EOF bits since they're not very interesting and they make the diagram too complex |
| 14:28 | <Lachy> | in the whole fallback content thread, has anyone actually given a use case for needing fallback beyond plain text? All I've seen are unsupported claims that it's needed. |
| 14:29 | <hsivonen> | Philip`: cool. the diagram makes the transitions look more complex than they actually are |
| 14:30 | <hsivonen> | Philip`: in fact there are only two transitions that break a stack assumption |
| 14:31 | <Philip`> | hsivonen: Is that two when not counting all the reconsume-EOF-in-the-data-state ones? |
| 14:31 | <hsivonen> | Lachy: if you want to get rid of longdesc and move the essay about the Union Jack or the dress of Lord Cornwallis inline |
| 14:32 | <hsivonen> | Philip`: reconsume whatever in data state works as a stack transition |
| 14:32 | <hsivonen> | (see my code :-) |
| 14:32 | <hsivonen> | Philip`: just rewind the stack to the data state |
| 14:32 | Philip` | will try to finish these bits while still untainted, and then look at the code ;-) |
| 14:33 | <Lachy> | hsivonen: that union jack example isn't particularly significant, since that description is completely inappropriate for how the flag was used. |
| 14:33 | <Philip`> | (I'm not trying to do a practical implementation - mostly I just want pretty pictures and things) |
| 14:33 | <hsivonen> | html5lib and my code are under the MIT license, it's not like looking at AT&T code :-) |
| 14:34 | <Philip`> | I currently just want to represent the algorithm as described in the spec, disregarding the implementation details that everyone else worries about :-) |
| 14:39 | <MikeSmith> | No commit-watchers mail since 28 June ... have there really been no changes, or is the list broken? |
| 14:39 | <hsivonen> | MikeSmith: Hixie is doing research. no changes |
| 14:39 | <MikeSmith> | OK |
| 14:39 | <MikeSmith> | thanks |
| 14:42 | <rubys> | annevk: you there? |
| 14:44 | <rubys> | if you get a chance, can you look into removing from tests/test_parser.py the following line "if testName == "tests5": continue # TODO"? |
| 14:45 | <hsivonen> | ouch. the catch all end tag case "in body" has a set of 69 strings to test against... |
| 14:47 | <hsivonen> | perhaps the tokens should come with a clever bitfield after all... instead of just interning |
| 14:49 | <hsivonen> | or a lex sorted array with binary search. or something... |
| 14:54 | <Philip`> | Does Java let you do binary searches for (interned) strings based on something like a pointer, rather than slowly comparing characters? |
| 14:55 | <Philip`> | (I guess that might not be possible since the GC can move things around arbitrarily and won't maintain a consistent ordering, perhaps) |
| 14:57 | <hsivonen> | Philip`: no, you only get to compare memory addresses for equality |
| 14:58 | <hsivonen> | Philip`: however, I could have a hashtable that knew that all values are interned |
| 14:59 | <hsivonen> | for the time being, I'm treating anything that goes beyond interning name and doing "foo" == name || "bar" == name || ... as a premature optimization |
| 15:02 | Philip` | wishes OCaml had better error reports than simply "Syntax error" |
| 15:12 | <Philip`> | Oh, assuming there's never an EOF doesn't make the state transitions much simpler - there's only about three cases I can see where it makes a difference |
| 15:23 | <MikeSmith> | hsivonen - is it true that currently with html5lib, given an arbitrary HTML document as source that it can construct a DOM from successfully, that DOM can't necessarily be re-serialized as well-formed XML? |
| 15:23 | <MikeSmith> | Or anybody? |
| 15:24 | <rubys> | it is rare, but true |
| 15:24 | <MikeSmith> | (I realize html5lib is not hsivonen's implementation...) |
| 15:24 | <MikeSmith> | rubys - OK |
| 15:25 | <rubys> | it is possible to have entity or attribute names that aren't simple names, it is possible for comments to have two consecutive dashes in them, it is possible for strings to contain form feeds or other values that are illegal in XML. |
| 15:25 | <MikeSmith> | ah |
| 15:26 | <Philip`> | When I tried serialising a random collection of web pages as XML, a significant number (uh, I can't remember how much, but maybe 20% or so) became ill-formed XML |
| 15:26 | <rubys> | other things (like matching up open and close tags) are taken care of by html5lib, and so are the overwhelming majority of common errors. |
| 15:26 | <rubys> | 20% surprises me. |
| 15:26 | <rubys> | are these public pages? Can you share an example? |
| 15:28 | <MikeSmith> | but hsivonen's implementation (backend of his conformance checker), by its nature, is inherently capable of producing well-formed XML? |
| 15:28 | <MikeSmith> | is that true? |
| 15:28 | <MikeSmith> | I would think it'd need to be since he has XML tools in the toolchain for it |
| 15:29 | <MikeSmith> | or maybe not |
| 15:29 | <Philip`> | I never looked at the examples in any detail, so I'm not sure what the issues were, though I remember a few were just because of <!----------> |
| 15:29 | <Philip`> | http://www.toyota.com/ is an interesting one |
| 15:29 | <Philip`> | since it has <spacer type"block" width="1" height="1"></spacer> which gets parsed as an attribute with a " in its name |
| 15:30 | <Philip`> | http://krijnhoetmer.nl/irc-logs/whatwg/20070507#l-581 - hmm, apparently it was 25% |
| 15:30 | <Philip`> | (just using the top thousand Yahoo search results for some boring word, if I remember correctly) |
| 15:31 | <rubys> | html5lib has a sanitizer that removes unsafe or unknown markup. Our goal is to make that bullet proof. |
| 15:31 | <Philip`> | I don't know how many of those issues were just caused by the html5lib toxml() being not very good |
| 15:32 | <Philip`> | (Also I think some of the issues might have been that I didn't handle character encoding properly) |
| 15:34 | <rubys> | If you are interested in producing XML, I would recommend the dom treebuilder |
| 15:38 | <Philip`> | When I was looking at those things before, I was mostly interested in analysing real HTML documents and just avoiding the slowness of repeatedly parsing with html5lib by caching them in a nicer serialised format, but it seems XML isn't very suitable for that :-( |
| 15:38 | <rubys> | what type of analysis? |
| 15:40 | <Philip`> | Mainly looking for common usage of certain elements/attributes, like in http://canvex.lazyilluminati.com/misc/copyright.html and http://canvex.lazyilluminati.com/misc/summary.html |
| 15:40 | <rubys> | your requirements are terribly unique, and I would like to work towards making a bullet proof conversion (possibly lossy in cases like spaces in attribute names) possible, and would appreciate test cases towards that end. |
| 15:40 | <Philip`> | (and theoretically any other statistics on HTML documents, except I got distracted before getting around to scaling the system up to work on a reasonable sample) |
| 15:41 | <Philip`> | ((for quite small values of 'reasonable')) |
| 15:45 | <annevk> | his requirements are very relevant for the work the HTML WG and WHATWG are doing (fwiw) |
| 15:45 | <annevk> | although they should be met by having a fast html5lib |
| 15:45 | <Philip`> | I expect I'll get back to this analysis thing at some point, and I'll see if I can extract the cases that cause problems (since I expect it would be nice to be able to use standard XML tools on random documents safely, without having to stick an HTML frontend onto them) |
| 15:46 | <rubys> | a fast html5ib ... which ultimately means a port to C |
| 15:46 | <rubys> | annevk: can you scroll back and see my question about tests5? |
| 15:46 | <annevk> | yeah, saw that |
| 15:47 | <annevk> | thought they already worked |
| 15:47 | annevk | poners |
| 15:47 | annevk | ponders* |
| 15:47 | <rubys> | that test passes, except for error checks, which you just enabled. |
| 15:47 | <rubys> | no error is produced on EOF |
| 15:47 | <Philip`> | I'm trying to write the easy part of the parsing algorithm in a language-agnostic manner, so it'll be nice if that works out :-) |
| 15:49 | <annevk> | there should be no error either |
| 15:49 | <annevk> | seems like a simple mistake in the test |
| 15:51 | <rubys> | if the tests were changed, then 'next if test_name == "tests5" # TODO' can be removed from ruby/tests/test_parser.rb too |
| 15:52 | <annevk> | yeah, did all that a few minutes ago |
| 15:53 | <rubys> | 'all that'? You changed the ruby test? |
| 15:53 | <annevk> | oh, ruby |
| 15:53 | <annevk> | sorry |
| 15:53 | <annevk> | I haven't played with ruby at all |
| 15:55 | <rubys> | I'd work on a C port, but only if we had more people who were interested in maintaining the code. This business of multiple people making changes to the Python code and Sam ports the changes won't scale much further. |
| 15:57 | <annevk> | if we have a C version we can just make Python and Ruby bindings, no? |
| 15:58 | <rubys> | that could certainly be done |
| 15:58 | <Philip`> | It's nice to have pure Python/Ruby/etc versions when people are unable/unwilling to compile and install C modules |
| 15:59 | <annevk> | can't you make some .pyc version people can just use? |
| 15:59 | annevk | isn't really up to speed with C > Python mappings and how to work with them |
| 16:00 | <Philip`> | (hence things like XML::Sax::PurePerl) |
| 16:02 | <Philip`> | I think you probably need a .dll (or .so or whatever) if you want to use a C library in Python, and that will be specific to a certain processor architecture and OS and maybe other system libraries, which is a pain when people can't compile easily |
| 16:02 | <annevk> | hmm, fair enough |
| 16:03 | <rubys> | on the other hand, 99.99% of the people would choose to use a C binding to their favorite language over a native binding. |
| 16:04 | <annevk> | http://lists.w3.org/Archives/Public/www-archive/2007Jul/0010.html ... |
| 16:05 | <annevk> | rubys, people who care one bit about performance, indeed |
| 16:06 | <annevk> | also, C bindings to an HTML5 parser should just be included by default in Python, Ruby, Java, etc. |
| 16:06 | <annevk> | well, maybe not Java |
| 16:07 | <Philip`> | Perl too :-) |
| 16:07 | <rubys> | I'd also love to see the C parser actually used by products like Opera and/or Firefox. |
| 16:07 | <rubys> | they could have their own treebuilders, of course; but the parser could be the same. |
| 16:09 | Philip` | wishes he could remember how to compute transitive closures (in a functional language) |
| 16:10 | <annevk> | from what I heard from WebKit and Firefox architecture that might be quite tricky |
| 16:11 | <rubys> | I'm not familiar with WebKit, but I have taken a peek at Firefox. Don't see why it would be tricky (I know, I know, famous last words...) |
| 16:12 | annevk | needs /ignore for e-mail clients |
| 16:13 | <annevk> | rubys, maybe it's possible, they have done it for the XML parser after all... |
| 16:15 | <rubys> | exactly... there is a part in the logic where you take in an input stream and produce a custom DOM implementation. Obviously, the input stream and DOM may vary from product to product, as would the tokenizer/parser error handing, but the logic could be pluggable. |
| 16:16 | <rubys> | Imagine how nice it would be if Safari, Firefox, and Opera used the SAME tokenizer/parser? |
| 16:16 | <annevk> | hmm, no parsing bugs to exploit! |
| 16:16 | <Philip`> | They'd probably all use slightly different versions with different bug fixes, so it wouldn't be entirely perfect |
| 16:17 | <rubys> | perfect? No. But a dramatic improvement over today. |
| 16:18 | <rubys> | And each vendor is going to have to invest some work effort towards html5 compliance. This should reduce the work for everybody. |
| 16:25 | <Philip`> | Are vendors planning to replace their existing HTML parser with a shiny new HTML5 one, or are they planning to just receive lots of bug reports and make lots of small fixes until they pass most of the tests, or are they not planning anything yet? |
| 16:31 | <annevk> | I think WebKit is planning on fixing bugs |
| 16:31 | <annevk> | they're pretty close for most cases anyway |
| 16:31 | <annevk> | dunno about other browsers |
| 16:37 | <Philip`> | Hmm, the state transition graph gets a bit big when I split out all the different content models |
| 16:53 | <Philip`> | http://canvex.lazyilluminati.com/misc/states2.png |
| 16:54 | <annevk> | ouch |
| 16:54 | <annevk> | "HTML tokenizing. More trivial than it looks." |
| 16:57 | <Philip`> | I think that's overestimating the possible transitions a little, since it assumes that whenever a tag token (either start or end) is emitted it could end up in any of the four content models |
| 16:58 | <Philip`> | At least there's the nice DataState PLAINTEXT black hole at the bottom |
| 16:58 | <annevk> | :) |
| 17:09 | <annevk> | In the Live DOM Viewer in Internet Explorer the <!> sequence causes the DOM view to turn almost blank... |
| 17:30 | <Philip`> | It looks like my state transition thing agrees with the spec's comments about "This can only happen if the content model flag is set to the PCDATA state" etc, except for the bogus comment state where you have to do lots of slightly convoluted thinking to work out that it's correct |
| 17:30 | <Philip`> | though, should the (non-bogus) comment states state that they can only happen when PCDATA, or is that obvious when left unstated? |
| 17:39 | <Philip`> | (I suppose it should also be obvious that the only state you can be in with PLAINTEXT is the data state) |
| 17:40 | <annevk> | I'm not sure why the other cases actually state it, to be honest |
| 17:40 | <annevk> | It makes it just more confusing for the cases where it's not |
| 17:46 | <zcorpan_> | annevk: it's because comments where the leading "!--" and trailing "--" don't fit, you can't read .nodeValue in ie |
| 17:46 | <zcorpan_> | annevk: i solved that by using a try/catch in dom2string |
| 17:47 | <zcorpan_> | annevk: and emitting "<!-- -->" if reading .nodeValue fails |
| 17:47 | <annevk> | k |
| 17:48 | <Philip`> | Ooh, neat, the W3C validator says <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN" "http://www.w3.org/TR/html4/strict.dtd"><title></title><table datapagesize=cheese><tr><td></table> is valid |
| 17:48 | <annevk> | hehe |
| 17:48 | <zcorpan_> | would be cool if the live dom viewer had an option to show the dom using dom2string_recursive |
| 17:50 | <zcorpan_> | Hixie: yt? |
| 17:54 | <annevk> | zcorpan_, the real feature would be to make a mashup of http://james.html5.org/parsetree.html and your script |
| 17:54 | <annevk> | zcorpan_, maybe just for the text input box |
| 19:14 | <Philip`> | The tokeniser is much easier when I don't worry about actually implementing it, since I can just add a command like AppendHyphenToCommentToken and use it without caring about what it does |
| 19:15 | <Philip`> | but I guess it'll all catch up with me when I do get around to the implementation bit :-( |
| 19:19 | <zcorpan_> | Philip`: you're writing pseudo-code? :) |
| 19:22 | <Philip`> | Yes :-) |
| 19:23 | <Philip`> | (in a form that can be transformed into real code) |
| 19:23 | <Philip`> | (but that just moves some of the work into the code that does the transformation) |
| 19:24 | <Philip`> | (but it's a good excuse to learn OCaml anyway) |
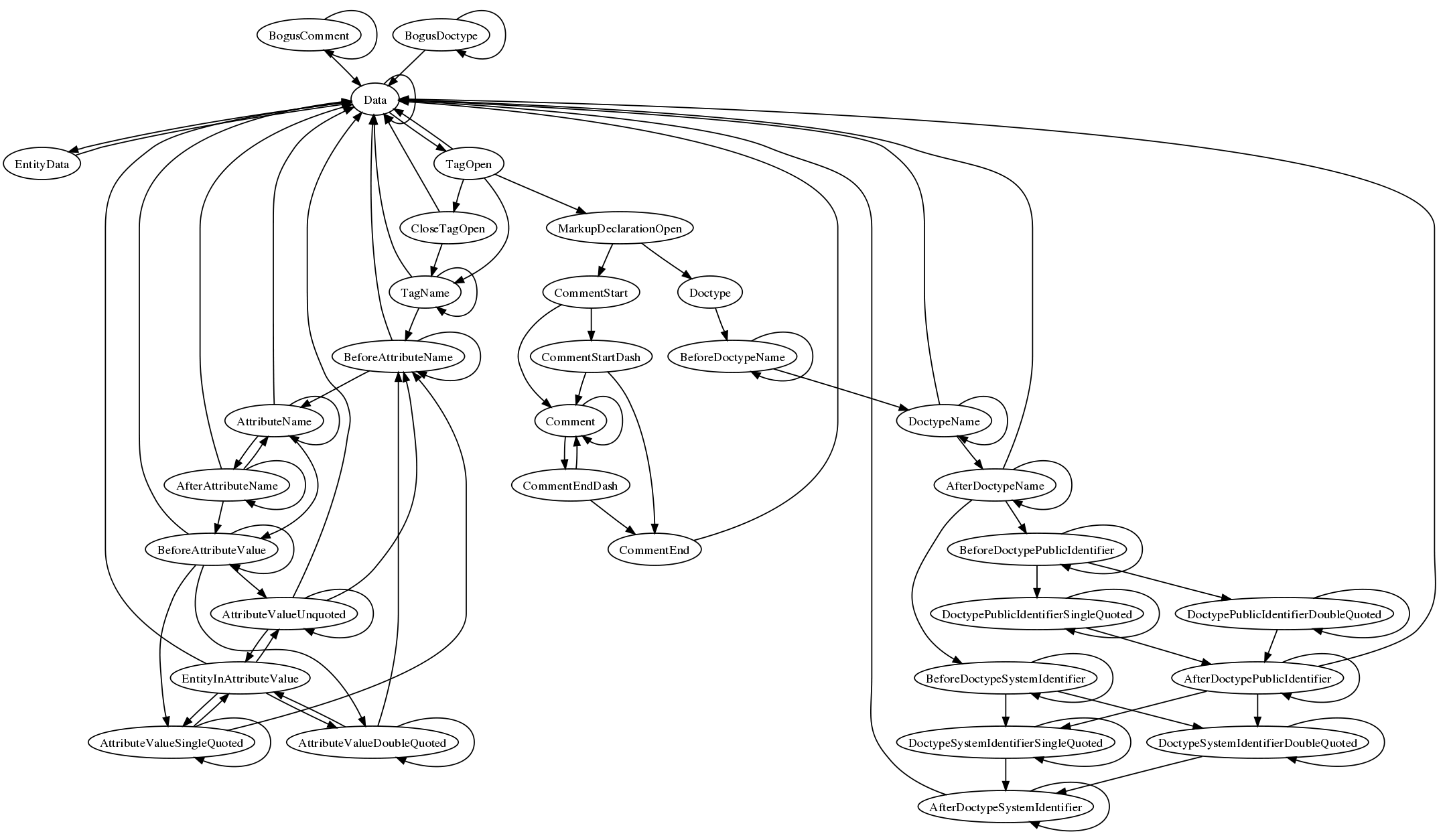
| 19:42 | <Philip`> | http://canvex.lazyilluminati.com/misc/states3.png - now with added doctype states, so I think it's got everything (and probably more bugs than before) |
| 19:43 | <Philip`> | Oops, that's still got the EOF transitions... |
| 19:44 | <Philip`> | Now it doesn't, so it's a bit prettier |
| 19:49 | <Philip`> | Actually, I should probably tell it about parse errors too, so I can see if it's much simpler for conforming content |
| 19:50 | <zcorpan_> | seems the algorithm in https://bugzilla.mozilla.org/attachment.cgi?id=188040 only has one flaw, which is before step 1: match the value against the list of color keywords |
| 19:52 | <annevk> | zcorpan_, nice interop mess |
| 19:53 | <zcorpan_> | now i'll just see which keywords are supported, and if that differs from the keywords supported in css |
| 19:59 | <Philip`> | http://canvex.lazyilluminati.com/misc/states4.png - hmm, it does look much cleaner when you don't allow parse errors |
| 20:03 | <zcorpan_> | wow. ie supports lightgrey but not lightgray. quite the opposite to all other gr(a|e)ys |
| 20:04 | <zcorpan_> | Philip`: you can't get into the bogus states if you don't allow parse errors, right? |
| 20:04 | <Philip`> | http://en.wikipedia.org/wiki/HTML_colors says lightgrey too |
| 20:07 | <zcorpan_> | could there be other keywords supported that aren't listed in css3-color ? |
| 20:07 | <Philip`> | zcorpan_: Yep - there's nothing leading into those states in the diagram, but I didn't bother stripping them out |
| 20:07 | <zcorpan_> | Philip`: ok |
| 20:08 | <Philip`> | zcorpan_: I believe I looked in IE's .exe for colour names, and it didn't have any that weren't the standard set which CSS3 and every other browser includes |
| 20:08 | <zcorpan_> | Philip`: ok. thanks |
| 20:09 | <Philip`> | Oh, that was IE3 |
| 20:10 | <Philip`> | but I don't think they've changed it since then |
| 20:10 | <Philip`> | since they just copied it from NN2 |
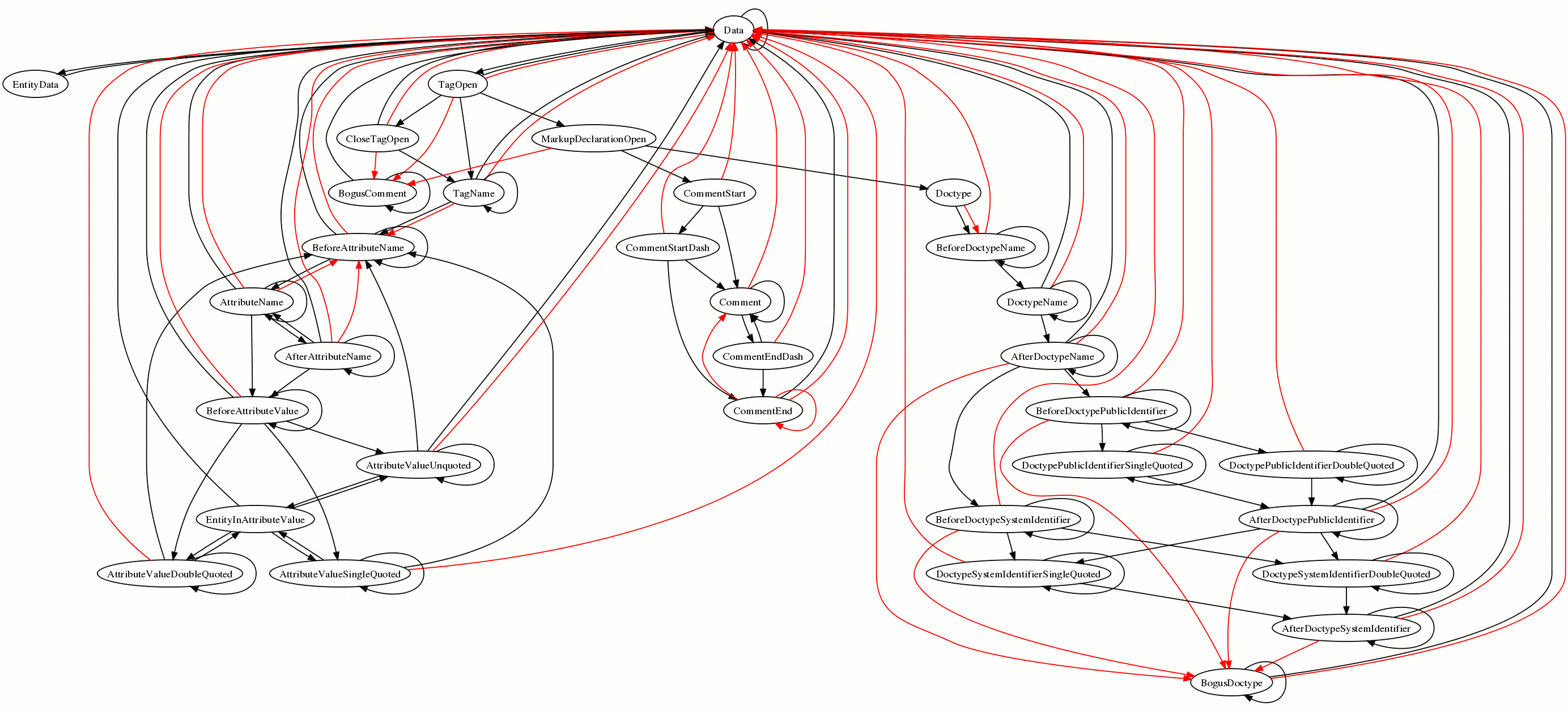
| 20:11 | <Dashiva> | Philip`: What if you colored the transition arrows depending on whether the transition requires a parse error or not? |
| 20:11 | <annevk> | might be interesting to test DarkSeaGreen |
| 20:11 | <annevk> | whether IE has the X11 or .Net impl |
| 20:11 | annevk | got that from the wikipedia page |
| 20:12 | <zcorpan_> | annevk: darkseagreen is in css3-color |
| 20:12 | <Philip`> | Dashiva: That sounds worth doing |
| 20:12 | <zcorpan_> | ah |
| 20:12 | <Philip`> | though what about transitions that can be both parse errors and not? |
| 20:13 | <Dashiva> | a third color, or both? |
| 20:14 | <Philip`> | Hmm, I'll just draw two arrows, because then I won't have to change my code :-) |
| 20:14 | <annevk> | some more arrows wouldn't hurt |
| 20:14 | <annevk> | it's not always clear what the direction is :) |
| 20:15 | <Dashiva> | Maybe put an arrowhead on the middle of the arrow too |
| 20:16 | <Philip`> | Hmph, colour PNGs are huge |
| 20:17 | <zcorpan_> | annevk: ie uses x11 |
| 20:17 | <Philip`> | http://canvex.lazyilluminati.com/misc/states5.png |
| 20:20 | <Philip`> | Hmm, I don't think I can make Graphviz draw arrow heads except at the end |
| 20:22 | <annevk> | zcorpan_, so how do you test which color is used? some color picker? |
| 20:23 | <zcorpan_> | annevk: .bgcolor returns the rgb color |
| 20:24 | <zcorpan_> | er, .bgColor |
| 20:24 | <annevk> | cool, automated testing |
| 20:26 | <zcorpan_> | http://simon.html5.org/test/html/parsing/color-attributes/keywords/ |
| 20:28 | <zcorpan_> | i haven't sent anything to the list about color attributes yet, have i |
| 20:30 | <annevk> | prolly not: http://www.google.com/search?q=inurl:whatwg-whatwg+color |
| 20:31 | Philip` | wonders if he could automatically generate tests to cover all the possible state transitions |
| 20:31 | <annevk> | in http://simon.html5.org/test/html/parsing/color-attributes/ you can change Opera to none too |
| 20:31 | <annevk> | Philip`, that'd be most useful |
| 20:32 | <annevk> | Philip`, format: http://html5lib.googlecode.com/svn/trunk/testdata/tokenizer/ pretty please :) |
| 20:32 | <zcorpan_> | annevk: ah. cool. |
| 20:33 | <annevk> | Philip`, or maybe in the tree construction format... |
| 20:33 | <annevk> | Philip`, that would prolly be useful too especially for testing browsers |
| 20:34 | <Philip`> | The tree construction format probably wouldn't work too well when I don't have a tree constructor, unless I'm missing some point... |
| 20:35 | <annevk> | ah, if you want to debug your own code, then no |
| 20:36 | <Philip`> | Ah, okay - I think it would be nice to have something I could use for just tokeniser tests |
| 20:36 | <annevk> | then use the funky json format :) |
| 20:37 | <annevk> | I wonder if that can be used in some meaningfull way on browsers too... prolly not |
| 20:37 | <Philip`> | though I don't know how to cope with the issue that the tree construction stage can affect the tokeniser's content model, when there's no tree construction stage |
| 20:37 | <annevk> | see escapeFlag.test and contentModelFlags.test |
| 20:37 | <Philip`> | Incidentally, "content model flag" is a confusing name since most flags don't have four states... |
| 20:38 | <Philip`> | Oh, right - that looks useful :-) |
| 20:41 | <Philip`> | Shouldn't the test format include attributes on end tags, since the tokeniser is meant to emit them? |
| 20:42 | <annevk> | the tokeniser doesn't emit them |
| 20:43 | <annevk> | Hixie, those stats on AAA are useful! thanks |
| 20:43 | <Philip`> | "Start and end tag tokens have a tag name and a list of attributes, each of which has a name and a value." "When an end tag token is emitted with attributes, that is a parse error." - it sounds like they are emitted |
| 20:44 | <annevk> | oh, ok |
| 20:44 | <Hixie> | annevk: which ones? |
| 20:44 | <annevk> | Hixie, the ones you pasted in IRC earlier; how many times duplication is hit etc. |
| 20:45 | <annevk> | although I'd love to see more detail :) |
| 20:45 | <Hixie> | ah yes |
| 20:45 | <Hixie> | i'll be posting more in due course |
| 21:12 | <annevk> | jgraham, I've been thinking about removing all the classes in html5parser.py |
| 21:12 | <annevk> | having said that, it hasn't been more than thinking |
| 21:13 | <annevk> | I'm not sure if we would actually gain anything from removing them and moving to a bunch of if/else statements as opposed to dictionary based method invocations |
| 21:13 | <annevk> | what we have now might actually be faster |
| 21:13 | <rubys> | why remove them then? |
| 21:13 | <jgraham> | annevk: I would image waht we have now is faster |
| 21:14 | <jgraham> | (although I would need metrics to be sure, of course) |
| 21:14 | <jgraham> | I think the time would be better spent on Chtml5lib |
| 21:14 | <annevk> | prolly |
| 21:15 | <rubys> | If I did the port, who would contribute to it? |
| 21:15 | <jgraham> | rubys: I guess it would be one way for me to finally learn C :) |
| 21:16 | <rubys> | I took a look at it, and porting it to C++ would probably take about a week. To C would be another week. |
| 21:16 | <annevk> | if I learn how to work with C on Ubuntu (besides learning to work with C in general) I would probably contribute |
| 21:16 | <jgraham> | (which is a way of saying I would love to contribute fixes but I don't feel confident in designing it) |
| 21:16 | <annevk> | not sure how much time I would invest on the python version afterwards |
| 21:16 | <rubys> | I would simply port the existing design. After it is working, it could be optimized, refactored, etc. |
| 21:17 | <bewest> | in that case why not profile the python version and move slow parts to C? |
| 21:17 | <annevk> | hmm, how are we going to handle <noscript>? |
| 21:18 | <annevk> | bewest, how is that better? |
| 21:18 | <jgraham> | That sounds great to me; I simply don't have enough C experience to know how best to implement things that are currently e.g. lists in python in C |
| 21:18 | <annevk> | we can prolly steal some ideas from Hixie's and hsivonen's impl |
| 21:18 | <bewest> | annevk: maybe it's not :/ |
| 21:18 | <rubys> | C++ has a standard library. Going to C next would mean reimplementing those concepts. |
| 21:18 | <jgraham> | bewest: It's not like there's one slow bit, it's the overhad of doing things many times |
| 21:18 | <bewest> | yeah |
| 21:18 | <jgraham> | e.g. many function calls |
| 21:19 | <Philip`> | I'd be interested to see if my C++ tokeniser implementation could actually work in practice |
| 21:19 | <jgraham> | Philip`: the O'Caml one? |
| 21:19 | <annevk> | rubys, if we're going to do it C might be better if we get more detailed control over things like the inputstream |
| 21:19 | <Philip`> | jgraham: Yes |
| 21:19 | <annevk> | Question: scripting is enabled or disabled? |
| 21:19 | <annevk> | we don't have any tests for <noscript> atm... |
| 21:20 | <Philip`> | (The C++-generating part is totally broken now, but http://canvex.lazyilluminati.com/misc/states5.png is generated from exactly the same data as the C++ tokeniser would be) |
| 21:23 | <annevk> | I'll assume that scripting is enabled for now |
| 21:23 | <annevk> | I suppose at some point we can provide a switch and enable/disable tests conditionally |
| 21:25 | <Philip`> | Could the test format be made to handle scripts modifying the input stream? |
| 21:27 | <Philip`> | You couldn't really expect parsers to all have script interpreters, but you could define that the tests can have <script>document.write("<p>")</script> (for some arbitrary JSON-encoded string) and the test harness can push those strings back into the input stream, to make sure the parser copes properly |
| 21:32 | <annevk> | at least for tree construction that's feasible |
| 21:32 | <annevk> | I was thinking of maybe offering #document-scripting-disabled at some point which provides an alternate tree and prolly also #errors-scripting-disabled |
| 21:33 | <Hixie> | just so everyone is aware and doesn't wonder if i died or something, i'm going to be on vacation for 3 weeks starting sunday |
| 21:33 | <gsnedders> | I'll make sure to ask if you've died. |
| 21:34 | <hasather> | Hixie: have fun :) |
| 21:34 | <Hixie> | i'll try! :-) |
| 21:34 | <gsnedders> | more seriously, where are you going? |
| 21:34 | <Hixie> | europe, east coast, various places around there |
| 21:35 | <Hixie> | apparently spending a lot of time in layovers at schipol |
| 21:35 | <Hixie> | which doesn't bode well for my luggage |
| 21:35 | <annevk> | yeah, it does that to you |
| 21:36 | <gsnedders> | I'm probably not getting of of the UK this summer |
| 21:36 | <jgraham> | gsnedders: Me neither (although I have been to various conferences abroad) |
| 21:37 | <gsnedders> | I'm going off down to Cambridge, but that's it. Probably going to Paris with my sister + her husband over the October holidays, though |
| 21:38 | <jgraham> | I assure you that Cambridge is lovely in every way. As long as you don't like hills. Or even slight rises. |
| 21:38 | <jgraham> | And, preferably, have a thing for tourists and punt touts |
| 21:38 | <gsnedders> | my grandmother lives in Cambridge, I've been plenty of times. Doesn't seem that hilly to someone from Scotland, though. |
| 21:39 | <gsnedders> | I should try actually punting again… |
| 21:39 | <jgraham> | It's really not that hilly. That why you can't like hills if you want to like Cambridge |
| 21:39 | jgraham | wants to move away just to get some hills |
| 21:39 | <gsnedders> | jgraham: come here! |
| 21:40 | <gsnedders> | [Fife] |
| 21:41 | <jgraham> | Fife would be nice. How are the employment opportunities though?... |
| 21:42 | <gsnedders> | No idea. I'm too young to know such things :) |
| 21:42 | <jgraham> | And I, sadly, am almost old enough to have to care :( |
| 21:43 | gsnedders | goes back to showing how young he is by looking up university entrance requirements |
| 21:43 | <Dashiva> | I feel old now |
| 21:50 | <Philip`> | You have to put up with all the students in Cambridge too :-p |
| 21:51 | <gsnedders> | hmmm… AAAAB at the min. for Higher entrance into Oxford |
| 21:51 | gsnedders | marks English as the B |
| 21:51 | <Philip`> | though I suppose they're usually outnumbered by tourists |
| 21:51 | <gsnedders> | Philip`: the terms aren't overly long at Cam/Oxf |
| 21:52 | <Philip`> | 3 * 8 weeks, with three months off for the summer vacation :-) |
| 21:52 | <gsnedders> | Philip`: which gives plenty of time for tourists to rule supreme :) |
| 21:52 | <gsnedders> | (I couldn't myself remember whether it was 8v10 or 10v12) |
| 21:53 | <Philip`> | It's nice during the exam term when they stop all the tourists coming into the colleges |
| 21:54 | <gsnedders> | I don't think I've ever been there at the time, due to school |
| 21:54 | <Philip`> | (Er, but I have no idea how many colleges do that) |
| 21:54 | <gsnedders> | (and nowadays I have exams at the same time) |
| 21:54 | <gsnedders> | Philip`: all do, IIRC |
| 21:57 | <jgraham> | Philip`: the quatity tourits+students is roughly conserved over the whole year |
| 21:58 | <Hixie> | cute, this http://triin.net/2006/06/12/Coding_practices_of_web_pages page refers to my 2005-12 study |
| 21:59 | <Hixie> | wow, the numbers he gets are very similar to the numbers i got in that study |
| 21:59 | <Hixie> | ncie |
| 21:59 | <Hixie> | nice |
| 21:59 | <Hixie> | (comparing http://code.google.com/webstats/2005-12/pages.html to http://triin.net/2006/06/12/HTML) |
| 22:00 | <Hixie> | even the oddities are present in both studies |
| 22:00 | <Hixie> | that's awesome |
| 22:11 | <hsivonen> | MikeSmith: my Java impl has configurable XML 1.0 compat |
| 22:13 | <hsivonen> | MikeSmith: for various features you can choose to be conforming to HTML5 (and potentially violate XML 1.0), not to violate XML 1.0 by treating violations as fatal errors or not violate XML 1.0 by being non-conforming to HTML 5 and making infoset-altering coercions |
| 22:15 | <hsivonen> | rubys: it might be a good idea to do an independent implementation in C. I believe Mike Day has already started one. I chose to do an independent implementation in Java using only test cases from html5lib in order to make a library that makes the most of Java instead of trying to map Pythonic stuff to Java |
| 22:23 | <MikeSmith> | hsivonen - thanks for the info |
| 22:29 | <hsivonen> | MikeSmith: to elaborate a bit: the SAX interface makes it possible for me to violate the interface contract in a way that exposes all of HTML5 in a way that may violate XML 1.0. The XOM interface, by design, won't allow it. When using a DOM impl meant for XML, some of the violation may not pass, either. |
| 22:30 | <hsivonen> | MikeSmith: so the non-XML stuff will be available through SAX (which I'm treating as the native interface) and custom DOM impls if someone cares to make one |
| 22:34 | <rubys> | hsivonen: the Ruby implementation is meant to make the most of Ruby, and diverges in a number of significant ways. |
| 22:34 | <rubys> | I did use the Python implementation as a starting point, but only as that, and only because it saved me some time. |
| 22:35 | <hsivonen> | rubys: ok. anyway, I suggest pinging Mike Day to avoid duplicating what he has already been doing |
| 22:36 | <rubys> | that's why I've been advocating putting implementations into one place (html5lib)... so as to minimize the "search time" it takes to find out the actual current state of an implementation. |
| 22:37 | <rubys> | what is the license, for example, of Mike's work? |
| 22:38 | <hsivonen> | rubys: the reason why I put the Java impl in a different repo is to keep it together with the rest of the conformance checker which in turn is there in order to keep it together with the schema project |
| 22:38 | <hsivonen> | rubys: MIT/expat, IIRC |
| 22:39 | <hsivonen> | rubys: MIT/expat seems to be the convention for HTML5 parsers :-) |
| 22:39 | <rubys> | ... eventually it will likely no longer be "the" (as in "the only") Java implementation. :-) |
| 22:40 | <hsivonen> | rubys: do you mean because of the repo choice or in general? |
| 22:42 | <rubys> | the two parsers that are in html5 have essentially zero required dependencies, and very few optional dependencies. I'd like to see a similar effort in PHP, Java, C#, and C. |
| 22:43 | <hsivonen> | rubys: my Java impl depends on a couple of my utility classes and ICU4J |
| 22:43 | <hsivonen> | rubys: putting the utility classes in one jar with the parser is not a big deal |
| 22:43 | <rubys> | i tried downloading it once. that was not the impression I got. But perhaps I was wrong. |
| 22:44 | <hsivonen> | rubys: making ICU4J optional for reduced correctness is not a big deal, either |
| 22:44 | <hsivonen> | rubys: do you mean you downloaded the parser that I'm currently working on or the conformance checker way back when you mentioned it in your blog comments |
| 22:45 | <rubys> | way back when |
| 22:45 | <hsivonen> | rubys: when my parser implementation is in a state where it can actually be used, I intend to offer a binary jar that doesn't require you to run the whole conformance checker build |
| 22:45 | <hsivonen> | (and the conformance checker build is now much easier, too) |
| 22:46 | <hsivonen> | rubys: the parser I'm now writing is not the prototype parser you saw way back when |
| 22:46 | <rubys> | Cool. Is there a single place where implementations can be found? |
| 22:47 | <rubys> | If not, can we make such a list on http://wiki.whatwg.org/wiki/ ? |
| 22:47 | <hsivonen> | rubys: dunno if the WHATWG wiki is up to date |
| 22:47 | <hsivonen> | rubys: in any case, I suggest that we link to each other whenever someone makes something runnable in a new language |
| 22:48 | <hsivonen> | (my tree builder is not runnable just yet) |
| 22:48 | <rubys> | How about this: I'll update html5lib to point to http://wiki.whatwg.org/wiki/Implementations |
| 22:48 | <hsivonen> | makes sense |
| 22:48 | <hsivonen> | svn co http://svn.versiondude.net/whattf/htmlparser/trunk/ htmlparser |
| 22:48 | <hsivonen> | in case you are interested |
| 22:49 | <hsivonen> | depends on the util module in the same repo, ICU4J and Java5 |
| 22:50 | <rubys> | are there any tests? |
| 22:51 | <hsivonen> | rubys: you need to check out html5lib separately to get test data |
| 22:51 | <hsivonen> | rubys: there are test harnesses for running html5lib encoding tests and tokenization tests |
| 22:51 | <hsivonen> | (tree builder harness will follow in due course) |
| 22:52 | <rubys> | this does look like the type of parser I was describing |
| 22:52 | <rubys> | Love the README. (Seriously) |
| 22:52 | <hsivonen> | good |
| 22:53 | <hsivonen> | well, it isn't runnable, yet |
| 22:54 | hsivonen | checks in a more positive README |
| 22:54 | <rubys> | I wasn't being sarcastic, I was serious. I prefer truth in labeling over marketing any day. |
| 22:55 | Philip` | 's tokeniser now works correctly on HTML documents that do not have any <, > or & in them |
| 22:56 | <Philip`> | (Well, it doesn't handle non-ASCII characters properly either) |
| 22:56 | rubys | congratulates Philip` |
| 22:58 | <othermaciej> | Philip`: is your tokenizer "cat"? |
| 22:59 | <Philip`> | (Do the html5lib tokeniser tests intentionally omit the end-of-file token?) |
| 22:59 | <hsivonen> | Philip`: so it seems |
| 23:01 | <jgraham> | Philip`: End of file token is implied by "no more tokens". Is there some reason to make it explicit? |
| 23:01 | <hsivonen> | rubys: I'm committed to providing buffered (correct) SAX, true streaming (potentially incorrect in non-conforming cases) SAX, DOM and XOM support. dom4j support should come for free with DOM support. JDOM support should be easy once those are done. True streaming StAX is intentionally not a goal. Tree-buffered StAX will be possible but not my personal interest. |
| 23:02 | <Philip`> | othermaciej: It's about as useful as cat at the moment :-) |
| 23:03 | <rubys> | hsivonen: my only remaining concern is that it is a single person project. Communities tend to outlive individuals. |
| 23:03 | <hsivonen> | rubys: I welcome contributions under the same license. |
| 23:03 | <Philip`> | jgraham: I guess not, assuming there's no way to generate more tokens after the end-of-file token (which I think is true, but not entirely obvious) |
| 23:03 | <rubys> | but that's not a today concern, you've already addressed my bigger concerns. |
| 23:04 | <Philip`> | I just need to fix my token-stream-serialiser to omit the end-of-file one... |
| 23:04 | <hsivonen> | rubys: also, it seems to me that it is a good idea to have something that runs before building a community |
| 23:05 | <rubys> | hsivonen: I've have rather mixed experience with that: http://search.yahoo.com/search?p=%22good+ideas+and+bad+code+build+communities%2C+the+other+three+combinations+do+not%22 |
| 23:05 | <rubys> | the best counter example I know of is Xalan. |
| 23:05 | <rubys> | Great code. Smart - very smart - developers. No community. |
| 23:06 | <hsivonen> | rubys: basically, my problem is that I don't know how to make the kind of commitments that I need to make in order to get paid for this and factor in the uncertainty (at this point) expectations of community |
| 23:08 | <rubys> | what commitments do you think html5lib has behind it? To my eyes, it has the exact right mix of good ideas and bad code (<smirk>) to be successful. |
| 23:09 | <hsivonen> | rubys: I've tried to be open about my plans, but I haven't published design docs, because I don't know if anyone would care to read them. I'd be happy to answer any questions on my design, though. |
| 23:09 | <jgraham> | All my bad code makes it successful? Excellent! |
| 23:09 | <jgraham> | (obviously rubys, anne and tbroyer are responsible for the good code) |
| 23:10 | <hsivonen> | rubys: as far as I can tell, html5lib is not on a paid basis in general |
| 23:22 | Philip` | can tokenise start tags now, which is handy |
| 23:22 | <hsivonen> | rubys: I added some info to the wiki |
| 23:42 | <Philip`> | This should, in theory, now do everything except doctypes... |
| 23:43 | Philip` | tries to set it up to run actual tests |
| 23:43 | hsivonen | reads Robert Burns' replies to jgraham |
| 23:45 | Philip` | wonders if there's an easy way to parse JSON in C++ |
| 23:46 | <Philip`> | Actually, that's kind of stupid, I'll just write a test wrapper in a proper language... |
| 23:46 | <hsivonen> | Philip`: are the libs linked to from json.org unsatisfactory? |
| 23:47 | <Philip`> | I guess that'd work, but downloading and installing requires too much effort |
| 23:48 | <Philip`> | (and then reading the documentation to work out how to use them) |
| 23:48 | <Philip`> | (and then actually writing the code to use them, in C++) |
| 23:57 | <Philip`> | Hmm, how are the ParseErrors in the tokeniser tests meant to work? They look like tokens, but it's not obvious where you add them so they don't conflict with all the other code that's fiddling with tokens... |
| 23:58 | <hsivonen> | Philip`: the tokenization spec is very clear about the sequence of parse errors relative to emitted tokens |
| 23:58 | <hsivonen> | Philip`: basically, you treat errors as an extra type of token |
| 23:58 | <hsivonen> | that the tokenizer emits |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}