| 00:42 | <Philip`> | Hooray, now my OCaml code passes all of the tokeniser tests (excluding the content model / escape flag ones) |
| 00:42 | <Philip`> | It's sometimes horrendously inefficient, e.g. every time it consumes an entity it sorts the whole entity list by length and then iterates through to find the first match, but that's okay because efficient is a non-goal |
| 00:43 | <Philip`> | s/efficient/efficiency/ |
| 00:43 | <famicom> | eh |
| 00:44 | <famicom> | simplicity>consistency>efficiency |
| 00:44 | <takkaria> | except, say, when writing parsers that need to be time-efficient, when efficiencey is a pretty important thing |
| 00:44 | <famicom> | takkaria |
| 00:44 | <famicom> | repeat after me: "Premature optimization is the root of all evil" |
| 00:45 | <takkaria> | I'm not talking about premature optimisation :) |
| 00:45 | <Philip`> | Overly late optimisation is a problem too - you have to be careful to get it just right :-) |
| 00:46 | <famicom> | philip: You mean like mozilla firefox? |
| 00:46 | <famicom> | which is apiece of bloat |
| 00:46 | <famicom> | it crashed when i tried to open 109 bookmarks at the same time |
| 00:47 | <Philip`> | (My OCaml thing is meant to act as a flexible reference implementation rather than as a usable parser, but the idea is to be able to compile that implementation into efficient code in other languages) |
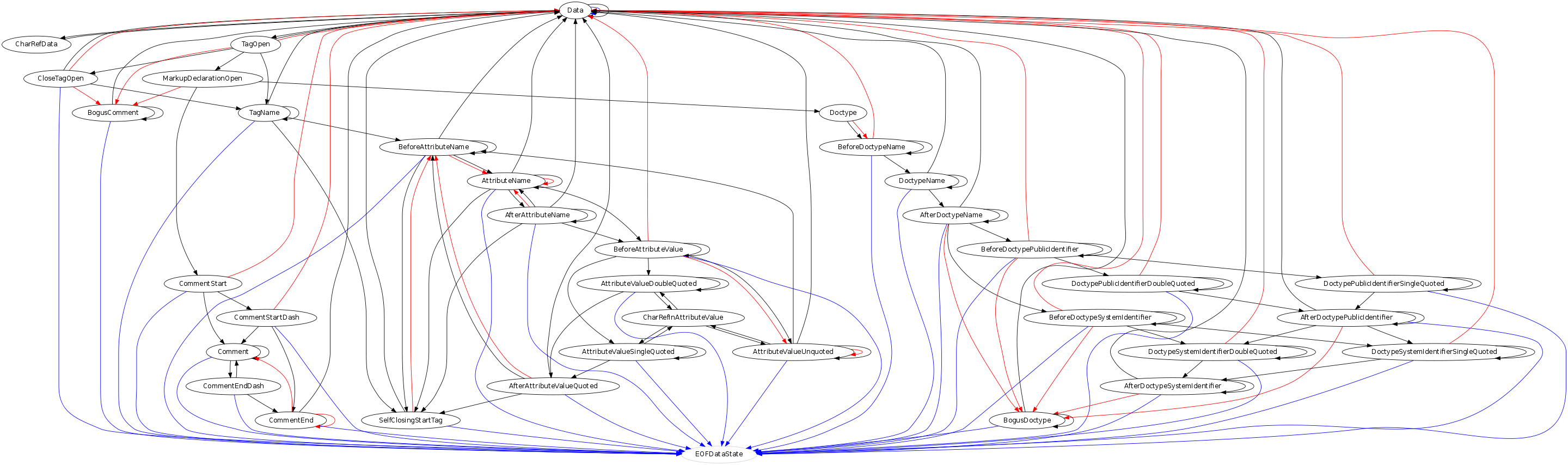
| 00:52 | <Philip`> | http://philip.html5.org/misc/tokeniser_states.png |
| 03:38 | <jwalden> | Philip`: that's the entire state-transition diagram for HTML5, I take it? beats out ECMA-262 for simplicity as I recall |
| 08:42 | <yecril71> | The advantage of having window for global scope is that otherwise you would not be able to differentiate between local and global. |
| 08:44 | <yecril71> | It does not cover all identifiers, e.g. it does not apply to constants and class names, but it is useful nevertheless. |
| 08:52 | <yecril71> | Modern blogs and wikis allow users to embed images in editable content. |
| 09:30 | <Philip`> | jwalden: That's just for the tokeniser |
| 09:30 | <jwalden> | okay, I *think* that's analogous |
| 09:32 | jgraham | tries to check in changes to html5lib gets caught by merge errors, cries |
| 09:32 | <Philip`> | jwalden: (The tree constructor algorithm is more like http://philip.html5.org/misc/insertion-modes-4.svg but that's about nine months out of date) |
| 09:33 | <jwalden> | tables |
| 09:34 | <jwalden> | bleh, let's just get rid of 'em |
| 09:34 | <jwalden> | :-) |
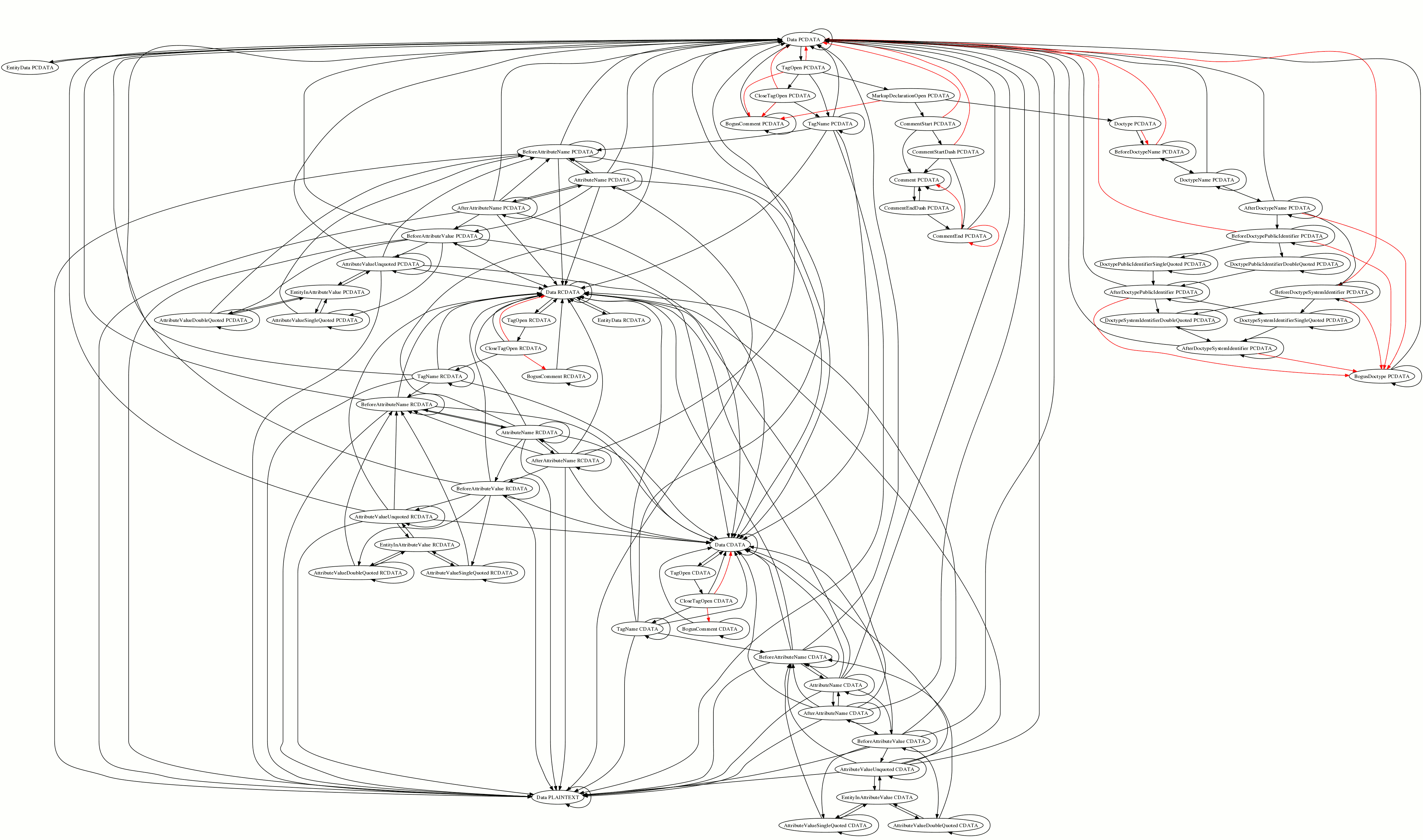
| 09:56 | Philip` | remembers he used to have something that split out the content model flags like http://canvex.lazyilluminati.com/misc/states10.png but can't find the code anywhere :-( |
| 11:16 | <gsnedders> | Philip`: Have you looked in /dev/null? |
| 12:13 | <Philip`> | gsnedders: Yes, but I couldn't find anything in there |
| 12:17 | <Philip`> | http://canvas.quaese.de/ looks like a handy canvas tutorial, if you speak German |
| 12:19 | <hsivonen> | it should be in /dev/random along with the works of Shakespeare |
| 12:31 | <jgraham> | Philip`: Any good ideas about how to implement the character encoding reparsing stuff in html5lib? |
| 12:31 | <jgraham> | s/encoding/encoding switching/ |
| 12:34 | <Philip`> | jgraham: I know almost entirely nothing about how character encoding works in HTML5 or html5lib or Python, so I have no ideas :-( |
| 12:52 | <jgraham> | Philip`: What I know: If we hit a meta element we need to either be sure that all the characters consumed so far have the same encoding as the previous characters or restart the parsing. The underlying file-like object may not natively support reseeking to the beginning so we either have to reread it or buffer the whole thing ourselves. |
| 12:53 | <Philip`> | We already try to buffer the first 10KB of the stream as soon as you start parsing it |
| 12:54 | <gsnedders> | jgraham: We don't want to re-read it if it's a urllib object of a POST request, for example |
| 12:54 | <gsnedders> | jgraham: So we probably need to buffer it |
| 12:54 | <jgraham> | I _think_ we need to buffer the raw character data before replacment characters are inserted and line breaks are normalised |
| 12:55 | <Philip`> | jgraham: Oh, that sounds true, and we only buffer the post-preprocessed input stream |
| 12:55 | <Philip`> | Is there some fixed limit on how much would need to be buffered? |
| 12:56 | <jgraham> | Philip`: AFAIK, no |
| 12:56 | <jgraham> | So maybe we should make a BufferedStream type that adds a .tell() and .seek() method to non-buffered streams |
| 12:56 | <jgraham> | By storing all the read data in a buffer |
| 12:56 | <jgraham> | (there is something like this already but it is not quite what we want) |
| 12:57 | <Philip`> | So for a document that never confidently declares a character encoding, the entire thing will be buffered in memory? |
| 12:57 | <Philip`> | In that case, we could just slurp the entire stream into a single string at the start, and then parse that |
| 12:57 | <jgraham> | Oh but then there is another problem because when we hit the <meta> element we don't know where in the unprocessed stream we are |
| 12:58 | <jgraham> | (assuming we want to read that in chunks for the sake of efficiency) |
| 12:58 | <Philip`> | Why does it matter where we are in the unprocessed stream? |
| 12:59 | <Philip`> | If the encoding changes incompatibly, it would just have to seek to 0 and start again, and it wouldn't matter where it had changed |
| 12:59 | <Philip`> | Oh |
| 13:00 | <jgraham> | It matters if we want to continue without reparisng if the encoding is compatible |
| 13:00 | <Philip`> | but it needs to work out whether anything has changed incompatibly, up to the end of the meta charset element |
| 13:00 | <Philip`> | which means it needs to know where it's read up to |
| 13:00 | <Philip`> | Oh, and that too |
| 13:01 | <Philip`> | It'd be easier if html5lib decided not to be a "user agent [that] supports changing the converter on the fly" |
| 13:01 | <jgraham> | Yeah, we could ignore that for now |
| 13:01 | <jgraham> | (but it would be a perf. in if we supported it) |
| 13:01 | <jgraham> | /in/win/ |
| 13:02 | <jgraham> | (assuming supporting it didn't place an undue burden on the implementation) |
| 13:02 | <Philip`> | jgraham: (Probably not much of one, since meta charset will typically be near the start of the document and it wouldn't have to reparse much at all) |
| 13:02 | <takkaria> | Hubbub doesn't allow changing the convertor on the fly, it just reparses |
| 13:02 | <Philip`> | takkaria: Is its input a stream or a string or something? |
| 13:03 | <takkaria> | yes, a string, so not a particularly useful comment from me there. :) |
| 13:04 | <Philip`> | jgraham: Is there a reason why html5lib should use streams rather than slurping everything into a string? |
| 13:04 | <Philip`> | Memory is cheap, after all :-) |
| 13:05 | <jgraham> | Philip`: It seems nicer? (especially for long strings). Also, we could, in principle, throw the buffer away once the encoding confidence was certian |
| 13:06 | <takkaria> | more properly, what hubbub actually does is call a "character encoding change" hook, which then can set a flag on the tokeniser so that it stops parsing and returns the new character encoding |
| 13:06 | <takkaria> | and then the app that's using hubbub has to send the data in again |
| 13:09 | Philip` | mostly just wants to reduce the overhead of calling char(), to make things much faster, but that seems independent of the encoding-related buffering/reparsing issue since it's on the opposite side of the decoder |
| 13:12 | <Philip`> | BufferedStream with .seek_to_zero() (and reparse when the encoding changes, don't do the complex changing-on-the-fly thing) sounds like the sanest approach, I guess |
| 13:13 | jgraham | wonders if hsivonen solved this issue |
| 13:13 | <jgraham> | Philip`: OK, I will look at that at some point soon |
| 13:14 | <jgraham> | (like maybe this evening) |
| 13:16 | <hsivonen> | for Java, I figured that it happens too often that the buffering in the character decoder causes non-ASCII to be buffered by the time of changing encodings |
| 13:16 | <hsivonen> | so I decided to remove support for changing decoders in place |
| 13:17 | <hsivonen> | instead, the java.io-based driver restarts the parse unconditionally when changing encodings |
| 13:18 | <hsivonen> | I intend to implement the same strategy for Gecko, but the current Gecko behavior is different, so I'm not sure if the spec as currently written is completely Web-compatible here |
| 13:18 | <hsivonen> | We'll see |
| 13:18 | <jgraham> | hsivonen: What does GEcko do? |
| 13:19 | <hsivonen> | jgraham: I don't understand what it does. |
| 13:19 | <hsivonen> | jgraham: my hypothesis is that it reparses if scripts haven't run and changes decoders in place if scripts have run |
| 14:16 | <jgraham> | Philip` or someone - let me know if I just horribly broke html5lib in some way and I'll back out the change (I checked in more than I intended to anyway) |
| 14:17 | <Philip`> | jgraham: It already fails enough test cases that I probably wouldn't notice if all the rest started breaking too :-) |
| 14:37 | <jgraham> | Philip`: BTW, I think it should be a little faster now |
| 14:38 | Philip` | sees ihatexml.py |
| 16:43 | Philip` | generates twelve thousand tokeniser test cases, and finds one bug in html5lib |
| 16:46 | <gsnedders> | Philip`: Then you don't have enough test cases |
| 16:48 | <Philip`> | gsnedders: I can't think of any more test cases to add, since I have one case for each interesting character that can occur from every tokeniser state |
| 16:52 | <gsnedders> | Philip`: Do you test every possible unicode character in every state? |
| 16:53 | <gsnedders> | No, you don't. |
| 16:53 | <Philip`> | gsnedders: No, because those aren't interesting characters |
| 16:53 | <gsnedders> | Philip`: That doesn't mean there aren't interesting bugs |
| 16:54 | <Philip`> | gsnedders: It means it's very unlikely that there will be bugs, because I test all the characters that a sane tokeniser would depend on, and every other character is equivalent and has no special processing |
| 16:55 | <gsnedders> | Philip`: You are assuming tokenizers are sane, which is very naïve |
| 17:19 | <takkaria> | Philip`: please do make those testcases public. :) |
| 17:25 | <jruderman_> | Philip`: i bet you'd find more bugs by fuzzing than by trying to be exhaustive wrt one aspect of parsing |
| 18:24 | <Philip`> | takkaria: I think it'd be a bad idea to add them all into html5lib, but I could just upload them to the web somewhere |
| 18:24 | <gsnedders> | Philip`: Add them all into html5lib, please. |
| 18:26 | <Philip`> | jruderman_: This seems like a case where exhaustiveness is relatively feasible, since there's an algorithm with a well-defined series of states and state transitions, and most implementations are pretty close to that definition, so it works at providing decent coverage of the implementations |
| 18:26 | <Philip`> | gsnedders: Why? |
| 18:26 | <Philip`> | gsnedders: Also: No |
| 18:34 | <gsnedders> | Philip`: Because then we have test cases located in one place |
| 18:36 | <Philip`> | gsnedders: But if there's twelve thousand tokeniser tests, and it takes ages to run them all, people will run the tests less often, which is detrimental |
| 18:37 | <gsnedders> | Philip`: But if they aren't there then they won't be wrong, which is detrimental |
| 18:37 | <gsnedders> | s/wrong/run/ |
| 18:37 | <gsnedders> | Interesting typo. |
| 18:38 | <Philip`> | gsnedders: It's only detrimental if they would have caught a bug that the remaining tests would have missed |
| 18:39 | <Philip`> | (and most of these tests are very redundant) |
| 18:40 | <Philip`> | (e.g. there are tests for "<!DOCTYPEa", "<!DOCTYPEb", "<!DOCTYPEy", "<!DOCTYPEz", "<!DOCTYPEA", ...) |
| 18:40 | <Philip`> | Also, if I did check in all these tests, and then the spec changed, someone would find hundreds of errors and get really annoyed trying to manually fix all the test cases |
| 18:42 | <Philip`> | Oops, there's only actually about one thousand tests, since I didn't sufficiently uniquify them |
| 18:55 | <gsnedders> | That certainly isn't too many. |
| 19:06 | <gsnedders> | ergh. This is going to be horrible. Having the same @cite over and over again. |
| 19:06 | <gsnedders> | Meh. |
| 19:14 | <Philip`> | http://html5lib.googlecode.com/svn/trunk/testdata/tokenizer/test3.test |
| 19:14 | <Philip`> | Happy now? :-p |
| 19:15 | <Philip`> | (That's about 1500, after I stopped stupidly failing to remove duplicates) |
| 19:15 | <Philip`> | takkaria: There's some new tests for you to run if you fancy it :-) |
| 19:17 | <gsnedders> | Philip`: :) |
| 19:46 | <Dashiva> | Are the tests sorted in order of relevance? :) |
| 19:50 | <Philip`> | I don't have a way to quantitatively determine relevance, so they're just sorted on the input strings :-p |
| 20:27 | <gsnedders> | Is it reasonable to write notes for English in HTML? |
| 20:30 | <jruderman_> | "for English"? as in classroom lecture notes? |
| 20:30 | <gsnedders> | jruderman_: Well, not lecture notes, but for my final year of school (in the en-gb meaning of school) |
| 20:31 | <jruderman_> | i used HTML for a few papers in college |
| 20:31 | <jruderman_> | and TeX for others |
| 20:31 | <gsnedders> | These are notes for my dissertation: I intend on doing the dissertation itself using XeTeX |
| 20:32 | <jruderman_> | i liked using HTML because i could easily tweak styles across an entire document. wysiwyg word processors usually don't do that well. |
| 20:33 | <jruderman_> | for example, if i needed to pad my paper a little, it was a simple matter of p { line-height: 1.05em; } |
| 20:33 | <jruderman_> | slightly less obvious than changing the font size ;) |
| 20:33 | <gsnedders> | For notes that isn't so needed :) |
| 20:33 | <jruderman_> | hehe |
| 20:34 | <jruderman_> | still useful to be able to change the styles of all the headings at once, though |
| 20:34 | <jruderman_> | another advantage of HTML is that you can put the notes on your web site and not worry about what software viewers have; ) |
| 20:37 | <Philip`> | Is text/plain inadequate for notes? |
| 20:37 | <gsnedders> | Philip`: Yes |
| 20:37 | <Philip`> | Why? |
| 20:37 | <gsnedders> | Philip`: Can't so easily build TOCs for text/plain :) |
| 20:38 | <Philip`> | Why do notes need a TOC? |
| 20:38 | <Philip`> | Just use your editor's 'find' feature if you want to go to a certain section :-) |
| 20:38 | gsnedders | now has a header element |
| 20:42 | <gsnedders> | I need automatic indexing in anolis |
| 20:42 | <gsnedders> | I do like how I mention that then someone who asked for it comes along |
| 20:53 | <gsnedders> | Anyone have views on how to mark up a bilbiography? |
| 20:57 | <Philip`> | I suggest putting it in <cite> |
| 20:58 | <gsnedders> | Philip`: "The cite element represents the title of a work" |
| 20:58 | <Philip`> | Who cares what specs say? |
| 20:58 | <Philip`> | You're citing stuff, so use <cite> - it makes perfect sense |
| 20:58 | <gsnedders> | It does, but Hixie's stupid. |
| 21:01 | <hsivonen> | what classes of products is http://www.w3.org/TR/2008/WD-XForms-for-HTML-20081219/ supposed to be normative on? |
| 21:02 | <hsivonen> | gsnedders: my view about marking up a bibliography: http://hsivonen.iki.fi/thesis/html5-conformance-checker#references |
| 21:03 | <gsnedders> | hsivonen: That doesn't conform to ISO 690, though |
| 21:03 | <gsnedders> | I mean, sure, I can use classes, but what do I gain? |
| 21:04 | <hsivonen> | gsnedders: you probably don't gain anything |
| 21:04 | gsnedders | links urn:isbn:0-330-29666-3 |
| 21:05 | <hsivonen> | gsnedders: bibliography formats that don't show the first name of the authors in full suck |
| 21:05 | <hsivonen> | gsnedders: they are bad for googling and disapproved by feminists |
| 21:06 | <hsivonen> | gsnedders: also, emphasizing author names over titles of works sucks when you are mostly referencing specs and technical documents some of which conceal their authors/editors |
| 21:07 | <gsnedders> | hsivonen: I'm referencing a book for English work, so that isn't relevant :) |
| 21:08 | <hsivonen> | gsnedders: you could still make the argument that in cultural contexts where the surname of the author is the surname of the spouse, abbreviating the first name of the author diminishes the personal identifier of the author to one letter, which is uncool |
| 21:11 | <hsivonen> | gsnedders: besides, I suggest making references in a way that you can GET without paying CHF 72 |
| 21:11 | <gsnedders> | :) |
| 21:12 | Philip` | realises that efficiently cutting wrapping paper for varyingly-sized presents is probably a bin packing problem and therefore NP-hard, which is totally unfair |
| 21:23 | gsnedders | tries to follow the Oxford Guide to Style |
| 21:24 | gsnedders | comes up with the probably stupid, "Vladimir Nabokov, The Enchanter [En. trans. of Volshebnik] (trans. Dmitri Nabokov) (London: Pan Books Ltd, 1987) (ISBN 0-330-29666-3)." |
| 21:27 | Philip` | suggests focussing on the parts of the dissertation that are likely to result in marks :-) |
| 21:28 | <hsivonen> | gsnedders: at least it's positive that they approve of listing the ISBN |
| 21:28 | <gsnedders> | hsivonen: They don't, I ignored that part. |
| 21:28 | <gsnedders> | :) |
| 21:28 | <hsivonen> | oh well |
| 21:28 | <gsnedders> | hsivonen: They do however, as with most of the style guide, give a lot more flexibility than almost anything else |
| 21:29 | <gsnedders> | Philip`: Yeah, I should :) |
| 21:31 | <gsnedders> | Hixie: "A person's name is not the title of a work " |
| 21:32 | <gsnedders> | Hixie: Lolita's name is the title of the book about her! |
| 21:36 | <Philip`> | gsnedders: Only if you do a plain string comparison and ignore the context and semantics |
| 21:36 | <gsnedders> | Philip`: Oh, sure. :P |
| 21:36 | <gsnedders> | (and yes, I am doing my dissertation on such books) |
| 21:47 | <virtuelv> | JohnResig: you around? You have a few broken links on http://docs.jquery.com/UI |
| 21:47 | <virtuelv> | (namely, all linked examples) |
| 23:33 | <takkaria> | it depends an awful lot on your citation style |
{kind=link}
{kind=link}
{kind=link}