| 00:39 | <cgriego> | Say HTML 6 adds a new void element. How would an HTML 5 parser know that the rest of the document isn't a child of that element? |
| 00:40 | <Hixie> | it wouldn't |
| 00:42 | <cgriego> | That seems problematic. |
| 00:43 | <Hixie> | why? |
| 00:47 | <cgriego> | Any new void element then creates a chicken & egg problem. Authors won't adopt it because they can't use it in a progressive enhancement safe way since it corrupts the DOM. Agents won't add it because authors don't use it. Similar situation to XHTML 2. |
| 00:50 | <Hixie> | doesn |
| 00:50 | <Hixie> | er |
| 00:50 | <Hixie> | doesn't seem to have caused particular problems in the past |
| 00:50 | <Hixie> | people don't really want to use new elements until the browsers use them anyway |
| 00:51 | <Hixie> | er, until they implement them i mean |
| 00:51 | <Hixie> | browsers add lots of stuff before authors use them |
| 00:51 | <Hixie> | in fact, they add everything before authors use them |
| 00:51 | <cgriego> | People are jumping in and using section/header/footer/etc now without proper browser support. |
| 00:51 | <Hixie> | not many people :-) |
| 00:52 | <Hixie> | and those people will get burnt anyway, e.g. when we rename <headeR> |
| 00:52 | <Hixie> | (or remove it, or whatever we end up doing with it) |
| 00:52 | <cgriego> | Not if they're serving as text/html ;) |
| 00:52 | <Hixie> | well i mean their pages won't be correct html5 anymore |
| 00:52 | <Hixie> | i don't mean that their site will break or anything |
| 00:53 | <cgriego> | As for the past, there's never been a time where HTML was actively evolving with so many authors and authoring programs. |
| 00:53 | <cgriego> | …as we have today |
| 00:53 | <Hixie> | yup, it'll keep on increasing until we have everyone on the planet online |
| 00:54 | <Hixie> | (and then it'll keep increasing until the population stops growing) |
| 00:55 | <cgriego> | I'd propose that HTML 5 parsing treat unrecognized elements (and only unrecognized elements) similar to foreign elements, where the SOLIDUS marks the start tag as self-closing. |
| 00:56 | <Hixie> | what problem does it solve? |
| 00:56 | <cgriego> | Author adoption of new void elements. |
| 00:57 | <Hixie> | wouldn't the fact that the browsers don't support those elements be a bigger barrier to adoption than the fact that the author has to jump through some minor hoops to get teh styling right? |
| 00:57 | <Hixie> | (if we introduce <foo>, you can always just do <span><foo></span> to get the parsing right in older browsers) |
| 00:58 | <Hixie> | put it this way: historically, HTML has never had a void element that was useful without the browser actually supporting the element directly somehow |
| 01:01 | <Philip`> | What about <meta>? That's useful for some UAs (e.g. search engines) even if browsers don't do anything with it |
| 01:01 | <Hixie> | elements in <head> have much bigger problems in the parser than whether they're void or not |
| 01:01 | <cgriego> | When <area> was first introduce, authors would add an image map to their site but also provide supplemental navigation below the image. Authors were able to adopt the element before all agents supported it. |
| 01:02 | <Hixie> | cgriego: but with <area>, the elements all get closed by the <map>, so it doesn't matter if the element gets closed or not |
| 01:03 | <cgriego> | You can't know that all new void elements will have a mandatory parent element. |
| 01:05 | <Hixie> | no, but i can predict the likelihood of there being a problem if unknown elements can't be closed by />, based on past experience |
| 01:06 | <Hixie> | (note that "span" is an unknown element per the parser, and we definitely don't want to support <span/>) |
| 01:06 | <Hixie> | (so actually what we would need to do is more complex than what you describe) |
| 01:09 | <cgriego> | Didn't realize span was unknown to the parser. Why is that? |
| 01:09 | <Hixie> | because only the elements with weird rules have to be known |
| 01:10 | <cgriego> | ah, like void elements :) |
| 01:10 | <Hixie> | yeah |
| 01:11 | <cgriego> | One of the solutions offered on the mailing list back in August was to have not add any new void elements. |
| 01:11 | <Hixie> | i maintain that there's no problem, so discussion of solutions seems pointless to me :-) |
| 01:11 | <Hixie> | but sure, we could just not add more void elements if that makes people happy :-) |
| 01:13 | <Hixie> | (at least until we have a need for one!) |
| 01:14 | <cgriego> | Not a fan of the idea, would just lead to more cases like <script src=# /> |
| 01:15 | <Hixie> | hm? |
| 01:17 | <cgriego> | I can see how not allowing new void elements would lead to elements with empty content models instead, which then authors would just try to self-close (like with script src) causing more problems in the end. |
| 01:19 | <Hixie> | well then we'd just use a void element |
| 01:20 | <Hixie> | or we could just not introduce elements with empty content models as well |
| 01:23 | <Hixie> | wooot! i've finally gotten through all the feedback on microdata stuff |
| 01:23 | <Hixie> | ok now i have to go through all the notes i collected |
| 01:23 | <Hixie> | and actually come up with a set of use cases, requirements, and scenarios |
| 01:23 | <Hixie> | so that i can evaluate solutions |
| 01:25 | <Hixie> | so far i've boiled down 15000+ lines of e-mail and dozens of pages of wiki and blog comments into 600 lines or so of notes |
| 01:38 | <Hixie> | here are my notes http://wiki.whatwg.org/wiki/Microdata_Problem_Descriptions |
| 01:38 | <Hixie> | i'll clean it up later |
| 02:07 | <Dashiva> | The tomato video comment thing seems painful |
| 03:50 | <MikeSmith> | Hixie: the two tables in 4.10.4 "the input element" with info about states and attributes |
| 03:51 | <MikeSmith> | it would be nice if those had IDs so the could be more easily referenced with fragment IDs |
| 03:51 | <MikeSmith> | and maybe table titles on them |
| 04:58 | <Hixie> | MikeSmith: file a bug |
| 05:23 | <MikeSmith> | Hixie: OK |
| 05:23 | <MikeSmith> | http://twitter.com/_masaka/statuses/1581828896 |
| 05:23 | <MikeSmith> | "hmm, **HTML5** web addr says relative path to be % encoded with UTF-8, but query with document encoding. What if path+query in non UTF-8 doc?" |
| 05:26 | <Hixie> | i don't understand the question |
| 05:36 | <MikeSmith> | Hixie: I don't either. was hoping you would |
| 06:14 | <MikeSmith> | Hixie: 'wondering if a relative URI "パス?クエリ" in EUC-JP doc, "パス" to be % encoded as UTF-8 octets while "クエリ" as EUC-JP octets?' |
| 06:18 | <MikeSmith> | http://twitter.com/_masaka/status/1582345343 |
| 06:28 | <Hixie> | MikeSmith: yes, that is indeed what browsers do (and what the spec says to do) as far as i'm aware |
| 06:29 | <MikeSmith> | Hixie: OK |
| 06:58 | <hsivonen> | the use case starting "Getting data out of poorly written Web pages" is clearly a winner |
| 06:59 | <MikeSmith> | hsivonen: where? |
| 07:02 | <Hixie> | http://wiki.whatwg.org/wiki/Microdata_Problem_Descriptions |
| 07:02 | <Hixie> | extracted out of 15,000 lines' worth of use case descriptions |
| 07:02 | <Hixie> | or what should have been 15,000 lines' worth |
| 07:02 | <Hixie> | but was actually 600 lines' worth about about 10,000 lines of stuff that had nothing to do with use cases |
| 07:04 | <MikeSmith> | Hixie: I see |
| 07:04 | <MikeSmith> | hsivonen: were you being sarcastic? "Getting data out of poorly written Web pages" does seem to be at least like a pretty decent use case |
| 07:05 | <hsivonen> | MikeSmith: I was being sarcastic. if the use case is about poorly written pages, a solution that requires the cooperation of the poorly-writing authors is likely to fail |
| 07:06 | <MikeSmith> | ah, yeah |
| 07:06 | <MikeSmith> | wasn't clear to me that it would require that cooperation |
| 07:06 | <Hixie> | hsivonen: you're assuming that that came from something to do with rdfa, which i don't think it did |
| 07:07 | <hsivonen> | Hixie: I'm not assuming anything about the origin of the use case |
| 07:07 | <MikeSmith> | "Getting data out of poorly written Web pages" seems similar to what browsers are already designed to do as far as rendering |
| 07:07 | <olliej> | MikeSmith: hehe |
| 07:08 | <hsivonen> | Hixie: I am assuming it is about new syntax rather than new algorithms, though |
| 07:08 | <Hixie> | hsivonen: use cases aren't about any kind of solution |
| 07:08 | <Hixie> | hsivonen: that's rather the point :-) |
| 07:08 | <Hixie> | we come up with problems then try and solve them, instead of coming up with solutions then trying to find problems for them |
| 07:13 | <hsivonen> | all the use cases that contain the word "commercial" seem like problems of CC's own creation |
| 07:15 | <hsivonen> | see also http://twitter.com/diveintomark/status/1256490748 |
| 09:42 | <hsivonen> | I'll implement the <p><table> quirk... |
| 09:56 | <annevk2> | you could write a little story around it how Hixie infected HTML parsers with a quirks mode switch |
| 10:00 | <hsivonen> | annevk2: yeah, I was thinking I'd blog about this |
| 10:01 | <annevk2> | I was thinking about a comment in the source code to be laughed about by people who know, but I suppose that works too :) |
| 10:14 | <hsivonen> | made innerHTML propagate the document quirkiness properly, too |
| 10:15 | <hsivonen> | which means this thing now has API surface! |
| 10:24 | annevk2 | finds it weird that only Gecko has this quirk: https://bugzilla.mozilla.org/show_bug.cgi?id=489532 |
| 10:24 | <annevk2> | usually it's the other browsers that are less strict |
| 10:28 | <hsivonen> | annevk2: IIRC, someone behind a firewall complained |
| 10:29 | <annevk2> | if we really need to have it zcorpan better documents how it works, but hopefully Gecko people are willing to fix the bug |
| 10:30 | <annevk2> | e.g. afaict it doesn't match what IE does |
| 10:30 | <hsivonen> | oh? |
| 10:31 | <annevk2> | I read that IE supports attributes as well, createElement("<x foo=bar>") |
| 10:34 | <zcorpan> | check the source of web dom core |
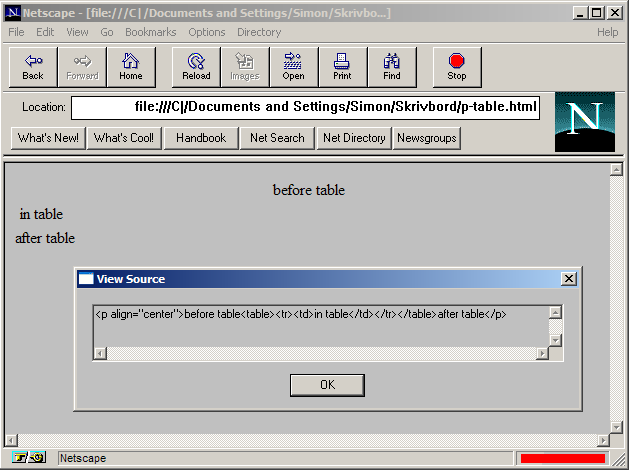
| 10:44 | <hsivonen> | anyone got Netscape 1.1 around to test how it laid out <p align=center><table>? |
| 10:45 | <hsivonen> | out of historical interest |
| 10:51 | <zcorpan> | hsivonen: netscape 1.1 seems to not support the align attribute |
| 10:54 | <Philip`> | zcorpan: <p align=center> works in Netscape 1.1 |
| 10:55 | <Philip`> | But <p align=center><table> looks left-aligned |
| 10:55 | Philip` | goes away for a bit |
| 11:00 | <zcorpan> | hmm it didn't want to center for me at first but then suddenly it did |
| 11:00 | <zcorpan> | netscape 1.1 seems to close the p |
| 11:04 | <zcorpan> | hsivonen: http://simon.html5.org/dump/p-table-nn11.PNG |
| 11:05 | <zcorpan> | same in netscape 2 |
| 11:13 | <hsivonen> | I wonder how the non-closing behavior was introduced |
| 11:33 | <zcorpan> | even netscape 4 doesn't center the table |
| 11:37 | <zcorpan> | when did ie first support tables? |
| 11:39 | <zcorpan> | ie3 is the earliest i could get running, and it centers the table |
| 11:42 | <zcorpan> | netscape 6 does not center |
| 11:52 | <Philip`> | Netscape 1.1 would be more usable if it used HTTP 1.1 |
| 11:52 | <Philip`> | (particularly because of Host headers, I guess) |
| 11:52 | <Philip`> | Currently even Google doesn't work in it |
| 11:58 | <Philip`> | (...where "doesn't work" means it always returns a 302 response saying it's moved to exactly the location I was looking at) |
| 12:05 | <Philip`> | IE 2.0 centers the table |
| 12:08 | <Philip`> | IE 1 (which calls itself "Microsoft Internet Explorer/4.40.308" but I think really is version 1) also centers the table |
| 12:12 | <Philip`> | zcorpan: (It seems easy enough to run IE1 and IE2 (at least on Linux) - download from http://browsers.evolt.org/?ie/32bit , make Wine pretend to be Windows 95, start the installer, copy the .cab file out of c:\windows\temp, cabextract it, then run iexplore.exe) |
| 12:39 | jgraham | wonders if anyone has got timbl's broser running on anything other than NeXT |
| 13:16 | <hsivonen> | zcorpan, Philip`: thank you for the testing. (the Netscape 4 and 6 results surprise me) |
| 13:33 | <annevk2> | in HTML4 <link> has a charset attribute |
| 13:33 | <annevk2> | I think browsers use that to determine e.g. the encoding of an external style sheet |
| 13:35 | <Philip`> | jgraham: Surely it wouldn't be too hard to recompile on modern Linux |
| 13:37 | <Philip`> | It's nice how its documentation still works correctly in modern web browsers |
| 13:38 | <Philip`> | though it looks a bit outdated since it says <HEADER> <TITLE>WorldWideWeb source files</TITLE> <NEXTID N="19"> </HEADER> |
| 17:04 | <myakura> | "HTML5 poses to make web development less secure, more complicated and more expensive" http://loud.anotherquietday.com/post/98616203/the-threshold-of-ebook-progress |
| 17:04 | <Philip`> | Sounds like technological progress to me |
| 17:06 | <Philip`> | since adding features will cause those effects, and it's impossible to remove features, so the only alternative is to stagnate |
| 17:09 | <Philip`> | ("HTML5 allows more flexibility in the markup format, which will lead to more XSS vulnerabilities" just seems incorrect, since it's no more flexible than what browsers already accept, and at least it'll be more consistent and better defined) |
| 17:10 | <Philip`> | (but "adds a layer of the most maliciously exploited software layer in mankind to every page (SQL)" seems a reasonable criticism, because SQL is easy to misuse and so people will misuse it) |
| 17:14 | <mpt> | It's not reasonable to say it adds it to "every page", though |
| 17:16 | <Philip`> | Ah, yes |
| 17:16 | Philip` | missed that bit |
| 17:18 | <Philip`> | I wonder how long it'll be before some writes a sqlite_real_escape_string function so they can safely concatenate values into their query |
| 18:02 | <Hixie> | hsivonen: in my defence, i was just trying to get the browsers to follow the specs. the real problem is html 4.01 didn't go through a real CR phase. |
| 19:43 | <tantek> | Hixie - can you name any W3C RECs that went through a real CR phase? |
| 19:49 | <Hixie> | tantek: not yet. Selectors is close. |
| 19:50 | <tantek> | I would tend to agree with that assessment. |
{kind=link}